Click to learn more about author Will Ochandarena.
Easily the most talked about application of AI is detecting and classifying objects in images and videos. Having long outgrown obscure trade magazines and conferences, it has been featured in TV with HBO’s Silicon Valley “Not Hotdog” app, and there was news recently about how Chinese police detected a crime suspect out of a crowd of 50,000 people using facial recognition on video feeds. Further, object and facial recognition is making its way into several consumer products, such as Nest’s latest generation of cameras, which can not only detect the difference between a person and a plastic bag, but also distinguish between members of your family.
Image classification is also a key enabler in Industrial IoT. Here, the most talked about example is self-driving cars, trucks, and trains, but use cases also exist in energy, mining, agriculture, and healthcare. In mining, AI-enhanced analysis of videos taking during blasting can more quickly and accurately determine success before the dust settles. In agriculture, analysis of drone and satellite imagery can help determine and predict crop health and improve yield. Last, in healthcare, AI-assisted reading of MRI and CT scans can help spot injury and disease more quickly and accurately than eyes alone.
Building video image collection and classification infrastructures in the industrial space proves trickier than doing so in consumer products. First, the location where video is being created, like mines, farms, and oil platforms, rarely has reliable, high-speed network connectivity. This means there is either insufficient network bandwidth to transmit full-fidelity video for remote classification, or the connectivity isn’t reliable enough to trust that classification will happen when it needs to, or both. Second, each of these use cases involves distinguishing between objects that look somewhat similar, like a healthy crop compared to a crop that is drying out from insufficient water. This means that off-the-shelf image classification models won’t work, and specialized models need to be trained.
The first step in building an industrial image classification system is training a classification model. To do this, a body of historical images that have been labeled into the desired classifications (healthy, needs water) can be fed into a Deep Learning framework like Tensorflow or MXNet. There are several tutorials online that discuss how to transform an off-the-shelf image classification model like Inception-v3 into a model customized for your use case.
Next, a data collection and processing infrastructure needs to be architected in order to classify images as close as possible to the point of collection, a pattern commonly known as “edge processing”. In a scenario with several related, but distributed, collection points the key is to design for collection, classification, and action at the edge, with aggregation of edge data in a central place like the Public Cloud for further model training and more advanced actions. This idea is illustrated in the diagram below. Here, computing systems at the edge consume the raw video feed, buffer it in case it’s deemed interesting later, and use the classification model to produce a stream of metadata that is sent to the central processing site. At the same time, a subset of images that have been determined useful for further learning are also sent to the central site for continuous enhancement of the classification models.
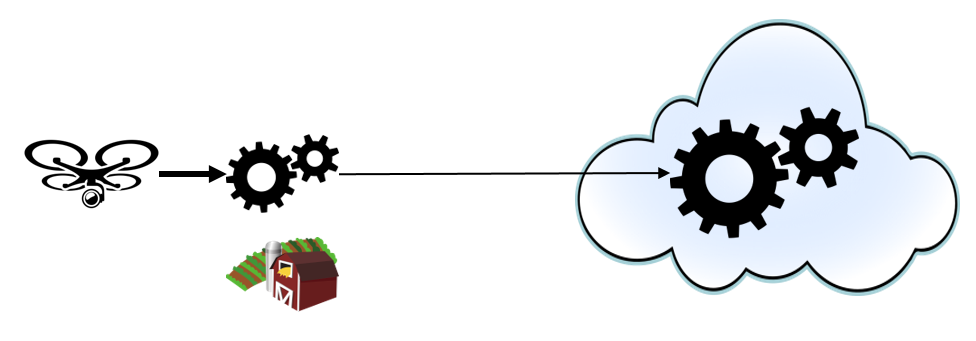
Edge-first architectures will not only improve efficiency and profitability of businesses, benefits will also trickle down to the consumer population. For example, in agriculture, innovation will lead to more plentiful, cost-effective, tastier food, and in healthcare we will see faster, more accurate diagnosis of disease leading to better outcomes. Most exciting of all, we’re only seeing the tip of the iceberg of what will be possible.