Click to learn more about author Thomas Frisendal.
”Nudge nudge, wink wink, say no more, say no more”. Says British Eric Idle in the third Monty Python’s Flying Circus episode, “How to Recognise Different Types of Trees From Quite a Long Way Away” from 1969.
Indeed, it should not be necessary to say more, once you have gotten your data model together.
Or is it?
What should we expect from a data model? According to Wikipedia:
“A data model (or datamodel) is an abstract model that organizes elements of data and standardizes how they relate to one another and to properties of the real world entities”.
Alright, here is a set of elements of data:

Clearly, something is not spoken out. Nudge, nudge? Yes, “how they relate to each other” is missing.
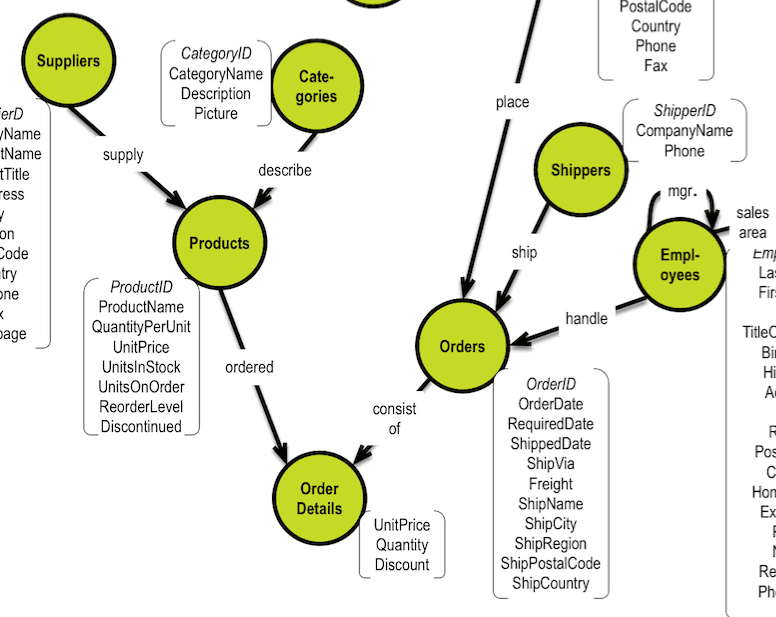
Maybe a proper data model will help us. Here is a snip of a data model describing a fictitious corporation, Northwind:

Northwind was Microsoft’s sample database for a number of years and can still be found on Codeplex. Copyright © 2006-2017 Microsoft Corporation. The diagram is produced by the author using Oracle Data Modeler.
Let us look at a scenario to check how much help the data model can give us:
We need to answer a C-level exec, who wants to know: “Which employee had the highest cross-selling count of “chocolate” product and which other product was it?”
So we need to somehow access these data:
- Orders and Order_Details concerning Product with the name “Chocolate” and find out, who of the Employees were involved in those orders.
- Find the Order_Details of all other Products on those same orders, which were not the “Chocolate” product.
- Count the number of other Products distinct across those same Orders and Employees.
- Return the top 5 Employee – Product – count combinations.
We know that the relationships in the diagram, are not named, which is a pity, because we need to say which relationship, we are referring to. Many data modelers have adopted a standard of using the two table names in combination as the name of the foreign key constraint. This works OK, as long as you do not have more than one relationship between the two tables. But you do see them, quite often.
But in reality this means that we could have two relationships between Customers and Orders. As far as SQL is concerned all that matters is that the constraint names are unique. Constraint names are not really externalized in any tool that I have seen. And they are not used in queries.
Wouldn’t it be nicer, if the query facility knew about relationships directly, knowing that they have some things in each end of the relationship?
It is time for a “wink, wink”, because information which is unsaid in the data model above. Somebody has to say more. That somebody is the data modeler / business analyst. Speak out the previously unspeakable: What are the names, and henceforth the meaning, of those relationships? (Really a sensible question, if you ask me).
Let us try a different approach. Instead of focusing on defining tables and constraints, what about starting with defining the business concepts (object types) and their relationships first:

The drawing above is a concept map, and in concept mapping you name the relationships. In fact, relationships at this level are most often action verbs, because the relationships reflect some business process or flow or composition of concepts:
- Products ordered are on Order Details
- Orders consist of Order Details
- Employees handle Orders
This resembles the subject->predicate->object thinking of the semantic standards (RDF etc.).
Concept Maps originated in the psychology of learning (Prof. Joseph Novak and others). These researchers called the relationships “linking phrases”. Very appropriate.
A concept map is not quite semantics, but it is full of business meaning, and it is definitely more meaningful than data, which are just defined in SQL.
Aside: Besides the semantic community there is one community of modelers, which go to this level of detail, and that is the fact modelers. Praise them for that. End of aside.
If you need to supplement your concepts with their properties you can do so as a property graph (a snip of a model):
The named relationships enable us to read the text of the query directly from the data model.
In the graph query languages on the market today, you start with defining the path that you want to traverse in the graph.
The notation below is sort of in “pseudo-Cypher”. Cypher (invented by Neo4J) is the most widely used graph query language. In the examples below, I have highlighted the relationships, for pedagogical reasons:
- First we want all Chocolate products:
Choose Products where ProductName is ‘Chocolate’, name the result set “Choc”
- Then we can proceed to the Orders containing those products and the Employees, who handled those orders:
“Choc” – ordered – Order Details – consist of – Orders – handle – Employees
- Looking for which other products those Employees handled is simply a continuation working from the result set from 2) just above:
Employees – handle – Orders – consist of – Order Details – ordered – Product
- So, now we have the set of orders, we are interested in, and the rest is a matter of aggregation.
This way of describing a path in a graph is the best practice way to do it in graph databases.
OK – but my data are not organized as graphs? The answer to that is: All data are graphs! And they can be presented as graphs. That is precisely what is going on in the very popular GraphQL community – check it out. Using GraphQL, your good old data in SQL can be made good to go as enterprise data graphs. You just need to define the relationships. And map them to GraphQL APIs.
In conclusion: Don’t ever leave home without named relationships! I cannot emphasize it enough – this is important!
Your data model must be verbal. Not only nouns, but also verbs. Verbs are actions and make things happen. So, having named relationships in the data model is key to enabling meaningful queries. They are business-friendly and easy to define and to read. Machine learning cannot name relationships, it can just detect them. You have work to do!
Name the relationships and do it using the business action verbs relevant to the reason for those object types to exist.
If you do it like this, say no more!