Click to learn more about author Michael Blaha.
This blog continues last month’s UML theme. Last month we discussed UML associations. Now we’ll discuss UML generalizations.
The UML (Unified Modeling Language) is a popular modeling notation that arose from the programming community, but it is also applicable to databases. The UML has a variety of models, one of which is the class model. The UML class model is essentially just a dialect of the ER (Entity-Relationship) approach. ER models have been used to model databases for forty years now since PP Chen’s original seminal paper.
SQL has excellent support for UML associations. These are the one-to-one, one-to-many, and many-to-many relationships that we routinely use in data models.
In contrast, SQL has weak support for UML generalizations. UML generalizations are the same as Entity-Relation subtyping. This blog discusses only single inheritance (a table has at most one generalization parent). We do not cover multiple inheritance (a table can have multiple generalization parents), as our experience is that multiple inheritance is not important for databases.
An Example
Consider a library. Various kinds of Library Items are available for lending. There can be magazines, videos, audio tapes, books, and other items. Library_Item is the superclass (the parent table) in a generalization. Magazine, Video, Audio_Tape, Book, and Other_Library_Item are subclasses. Here is a data model.
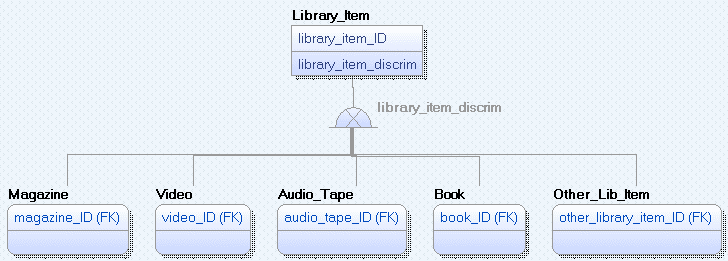
Object-oriented programming languages readily implement generalization. It’s built into the fabric of the language. Each Library_Item object is extended by the attributes of one subclass. For each object, the combination of a Library_Item and the pertinent subclass is atomic and has a single lifetime.
Generalization Implementation
There are three basic database approaches for implementing generalization: separate tables, push attributes up, and push attributes down.
With separate tables, the database has six tables for the library example – a Library_Item table, a Magazine table, a Video table, and so forth. The subclass primary keys are foreign keys to the superclass table. Logically, each superclass occurrence corresponds to exactly one subclass.
If attributes are pushed up, the library example has one table. The Library_Item table has a primary key, the discriminator, the Library_Item descriptive attributes, the Magazine descriptive attributes, the Video descriptive attributes, and so forth. The data model does not show descriptive attributes, but they are easy to add. As you can see, the single table has the union of all the attributes for the six classes.
If attributes are pushed down, the library example has five tables – Magazine, Video, Audio_Tape, Book, and Other_Lib_Item. The Library_Item descriptive attributes are repeated for each of the five subclasses. The discriminator attribute is not needed because there is no dispatch table indicating which subclass applies. Either the application knows which subclass table to look in, or it must check each of the subclass tables to find the desired Library_Item record.
Weaknesses of Database Implementation: Separate Tables
Separate tables are the most natural implementation, but this approach suffers from several serious flaws.
One issue is there is nothing in SQL to cause a partitioning across subclasses. A Library_Item with ID = 5 could have a Magazine record and a Book record. This is nonsensical as each Library_Item should correspond to exactly one of the subclasses. There is nothing in SQL to force the population of the subclasses to correspond to the discriminator. About the only way to implement partitioning with SQL is to use triggers which are tedious and error prone to implement.
Another issue is that SQL has only one-way referential integrity. If we delete a Library_Item record, we can cause the delete to cascade to the appropriate subclass record. However, if we delete a subclass record, there is nothing to cause the delete to propagate upward to Library_Item. This lack of two-way referential integrity becomes important for large data models with relationships at all levels of the generalization hierarchy. Once again, about the only way to implement two-way referential integrity with SQL is to use triggers.
Weakness of Database Implementation: Push Attributes Up
By pushing attributes up, we violate third normal form. There is a transitive dependency – the appropriate descriptive attributes depend not only on the primary key, but also on the discriminator.
It’s difficult to ensure that only the attributes for one subclass are populated for a record while the other subclass attributes are NULL. We can’t enforce not NULL constraints for subclass attributes because we are using nullability to implement exclusion.
Also, there is much awkwardness if the same attribute name appears in multiple subclasses. We could consolidate the names if they have the same meaning, but we have a problem if two subclasses have the same attribute name with different meanings. Then we would have to rename one or both attributes.
Weakness of Database Implementation: Push Attributes Down
Technically, by pushing attributes down we satisfy normal forms. But we violate the spirit. The schema of Library_Item descriptive attributes are duplicated for each of the subclasses. This makes the application more difficult to support and maintain. The problem only becomes more severe for multiple generalization levels.
Also, it’s awkward to find records. There is no Library_Item dispatch table indicating which subclass holds a pertinent record. This flaw becomes more severe for large models with multiple generalization levels.
In Conclusion
The bottom line is that generalization (also called subtyping) is an essential part of Data Modeling. Unfortunately, SQL semantic support is weak. That means that applications must support the semantics on their own with additional programming. Of course, such programming is error prone, so you must perform extra testing on applications with generalizations to catch bugs.