
Click to learn more about author Shay Lang.
With the major changes in the global economy this year, the need to monitor and reassess corporate expenses has never been more important. Both small startups and large enterprises have had to improve on the sales side, reduce their overhead, and review their variable costs in what the famous investor Elad Gil has coined as the “Startup Offense and Defense in the Recession.”
In the digital age, one of the most significant expenses that many companies have is their cloud costs, which is largely a variable expense. With effective monitoring and cost optimization, many companies can drastically improve their cloud expenses. For many organizations, cloud costs represent such a significant portion of their operating expenses that a new field has emerged called Financial Operations (FinOps), which brings together engineers, developers, and financial professionals with the goal of improving cost efficiency.
Here is a look at how the application of AI-based monitoring can be used to more proactively manage cloud costs, and how we’re using an innovative platform to cut a projected $360,000 this year from our AWS bill.
Our Five-Pronged Strategy
As mentioned, one of the pillars of our defensive strategy in 2020 was to reduce our cloud costs – specifically, we set out to do this with the following three objectives:
- The process of reducing cloud costs needed to take no more than one month, with three engineers working on it.
- The proposed changes needed to fit seamlessly within our existing code base.
- The changes needed to be sustainable over the long run, meaning that our cloud cost savings would continue in subsequent months after implementation.
With these objectives in mind, three engineers were tasked with working on the cost-cutting mission for one month, while the rest of the team continued working on our core app.
After researching the challenge and having several discussions, the team decided to tackle this problem in five key verticals.
1. Tag AWS Resources
First off, we knew that our product uses many different AWS services concurrently and we wanted to pinpoint specific costs associated with each one. To accomplish this, we tagged each AWS resource with the relevant instance type, components, and processes. For example, we tagged each of our S3, EMR, and EC2 instances and went through each one individually to determine if we could reduce cost by storing files more efficiently, compressing data, and so on. In the case of our EMR processes, the process of tagging resources allowed us to go from an average text file size of 200MB to 18MB per file.
2. Reduce Workloads in the Development Cycle
Next, we looked at optimizing our development cycle for R&D and new releases. Our development cycle uses Feature Branches where each branch has its own environment. After reviewing these feature branches, we determined that we could reduce each workload size and create “mini-production” environments instead. By using the minimal operational size and removing nonessential services, this allowed us to reduce development cluster sizes by roughly 50 percent, leading to further cloud cost savings.
3. Cloud Usage Planning & Reserving Instances
Another of the benefits of tagging each resource individually is that it allowed us to predict and reserve cloud usage much more efficiently. In particular, we were able to switch from using reserved instances (RI) and convertible RI to a more flexible savings plan. The savings plan didn’t require us to commit to using specific instance types or geographic regions. Instead, we simply needed to commit to an hourly budget for cloud resources, which allowed us to switch between instance types more cost-efficiently. Ultimately, this change increased our financial planning capabilities related to cloud usage.
4. Cloud Cost Forecasting
Similar to how we planned and reserved cloud usage in advance, we also used time series forecasting techniques for cloud costs. The main reason that we, and other companies, want to forecast our cloud cost bill is to avoid surprises at the end of the month. One of the primary causes of surprises in cloud costs is due to anomalies – for example, a developer may accidentally forget to stop running a service or a bug in a release may cause costs to unexpectedly increase. By forecasting based on previous usage data, you can then identify when anomalies lead to runaway expenses.
Prior to widespread use of cloud services, the costs of computing infrastructure were largely a fixed CapEx, meaning you bought servers and data storage upfront and were able to plan for the expenses six to 12 months in advance. Cloud computing, on the other hand, comes with significantly increased flexibility in usage – and costs. And with that comes a greater need for accuracy in planning and forecasting budgets.
Many cloud providers do provide simple forecasts based on linear regression, although the issue is that these estimates can easily be off by 10 to 20 percent. Given the size of cloud expenses for mid- to large-size companies, this often equates to millions of dollars each year.
If a cloud forecast is too high at the beginning of the month, the next step is to figure out what is causing the increase. The main difference between this kind of forecasting and cloud providers is that our solution provides a breakdown of how each individual service contributes to your projected bill. Contrast this with a cloud provider that typically only provides a single forecast for the total cost next month.
Below is an example of an AWS cost forecast that includes total costs and future forecasts, as well as the top increases and decreases in costs broken down by service, compared to the previous month.
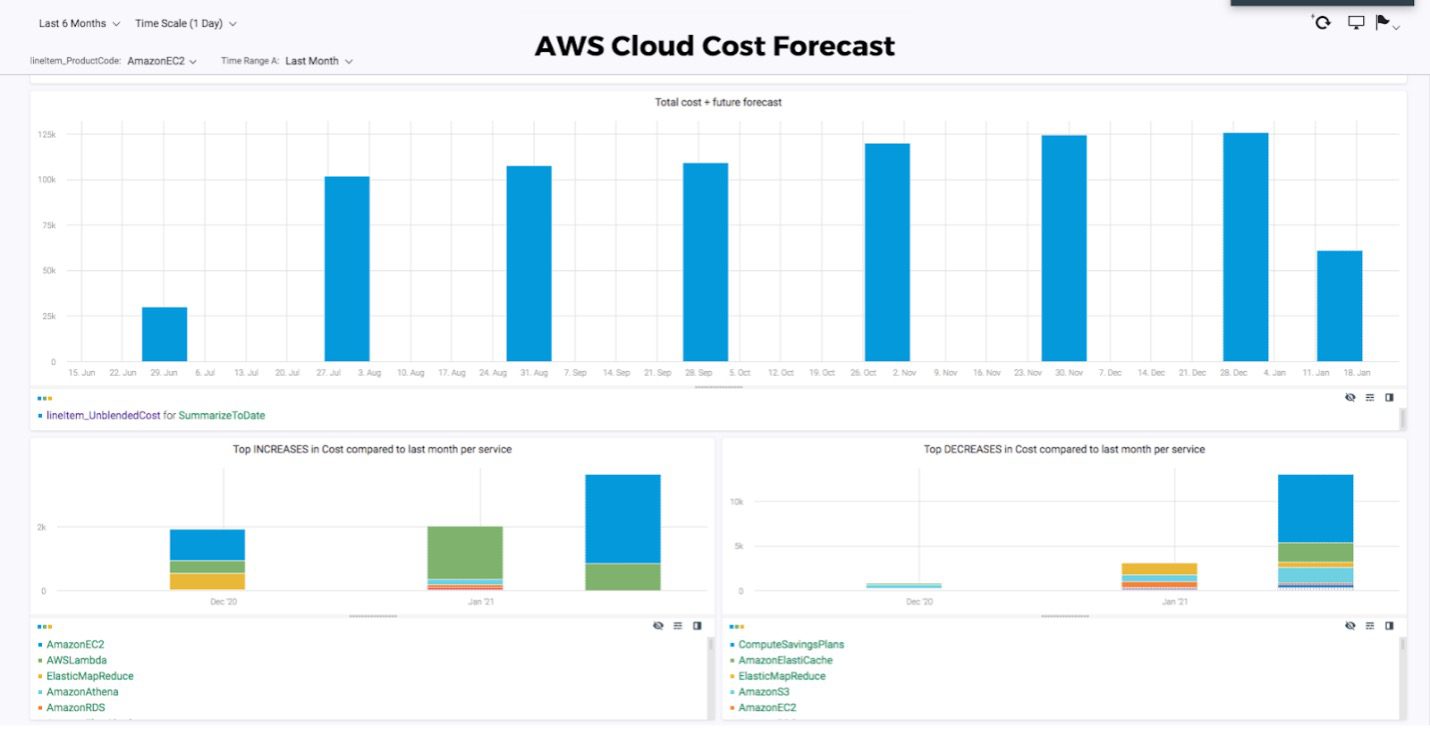
In summary, cloud cost forecasting keeps companies from facing unwelcome surprises in their monthly bill, and instead works proactively to manage their usage and meet their budgets.
5. Real-Time Monitoring
Finally, since our third objective was to have these cloud cost savings persist over time, we knew that we needed to use our own product for real-time cloud cost monitoring. As mentioned, the issue with using the traditional cloud monitoring provided by AWS was that there was an eight-hour delay in the data, which could have led to surprise expenses.
Instead, we used patented algorithms to monitor elastic load balancing, spot instance usage, and so on. As spikes in cloud usage did occur, we received real-time alerts with a root cause analysis and were able to resolve each incident before they significantly impacted our bottom line. For instance, below is an example of detecting two anomalies from our S3 instance: One was related to our Cassandra backup snapshots and the other to our helm charts.
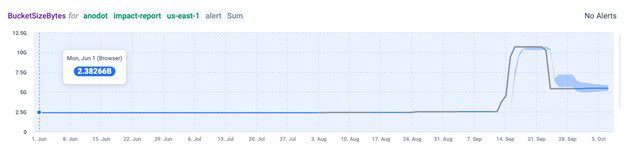
Another example of monitoring our cloud usage came from a spike in vCPU, which was caused by one of our data scientists accidentally spawning new machines. Thanks to the near real-time alert, we were able stop the experiments before incurring any significant costs.

Why AI Is a Crucial Differentiator
As you may know, one of the main challenges with cloud costs is that traditional monitoring, including those provided by cloud providers, has a delay in usage reporting. This data lag can often be between eight hours and two days, depending on the cloud provider. What’s more, with the growing number of services, instances, and regions, optimizing cloud costs is an increasingly complex task. As a result, when incidents inevitably do arise, runaway costs can easily go undetected, which allows the expense to snowball into a larger issue.
There are three main reasons that business metrics, such as cloud costs, are so difficult to monitor:
- Context: Each cloud-related metric has its own unique context, which means they cannot be evaluated in absolute terms. Instead, each metric needs to be evaluated in relation to other cloud variables.
- Topology: In addition to being contextual, the topology of cloud costs is unknown. In other words, the relationships between cloud cost variables are highly dynamic and complex, and correlations between individual metrics must be accounted for.
- Volatility: Finally, the rate of sampling for cloud costs is incredibly volatile. Often, there may be minutes or hours between cloud instances being used at their normal levels, which makes real-time monitoring that much more challenging.
Now that we’ve discussed that landscape and challenges of cloud cost monitoring, let’s review how machine learning can be applied to the field.
Unlike traditional cloud monitoring systems, which involve setting manual thresholds for known anomalies and readjusting them as new ones arise, machine learning can solve the above-mentioned challenges in the following ways:
- With the use of unsupervised learning, each individual metric’s normal behavior is independently learned, and every layer of an organization’s cloud data can be monitored in real time.
- As behavior fluctuates and seasonality occurs, algorithms autonomously learn the new topology and adjust its anomaly thresholds.
- Each incident is also paired with a deep root-cause analysis of correlated metrics, so DevOps teams have the necessary information to resolve incidents faster.
What We Learned
One of the pillars of our cost optimization strategy this year has been to review our cloud usage and costs. In doing so, we found four verticals that could be improved including:
- Tagging cloud resources
- Reducing development workflow sizes
- Efficient financial planning
- Real-time cloud cost monitoring
By using an advanced monitoring system, we were able to detect and resolve spikes in cloud usage before significant expenses were incurred, saving our company a projected $360K from our AWS bill this year.