
Click to learn more about author Roy Hegdish.
Today’s data-intensive world presents both challenges and opportunities for modern organizations. Data grows exponentially, as do the breadth and depth of the types of analysis business departments wish to perform. Data infrastructure must adapt to this new reality of higher volumes, velocity, and veracity of data. A robust, agile, and scalable Data Architecture will be a key driver of enterprise success in the coming years.
While most enterprises are already aware of the big data opportunity and the risks of lagging in the current data arms race, their data infrastructure has not necessarily kept up with their ambitions. Data warehouses that were designed to solve the problems of two decades ago are not necessarily suited for solving current-day problems. Relying on legacy systems is often the easy choice in the short term, but dangerous and costly in the long term.
One main reason organizations hesitate to migrate from legacy data platforms is the belief that such migration is going to be long, arduous, and costly. While in many cases, this is true, it is not an unchangeable fact of life. Migrating an enterprise data warehouse is going to be an undertaking, but planning ahead and following a few best practices can make it a relatively painless process.
In this article, we’ll present a framework for migrating from an on-premise data warehouse to a Big Data Architecture in the cloud, based on our years of experience working with customers on such migrations (from the data infrastructure side).
Conceptual Reference Architecture
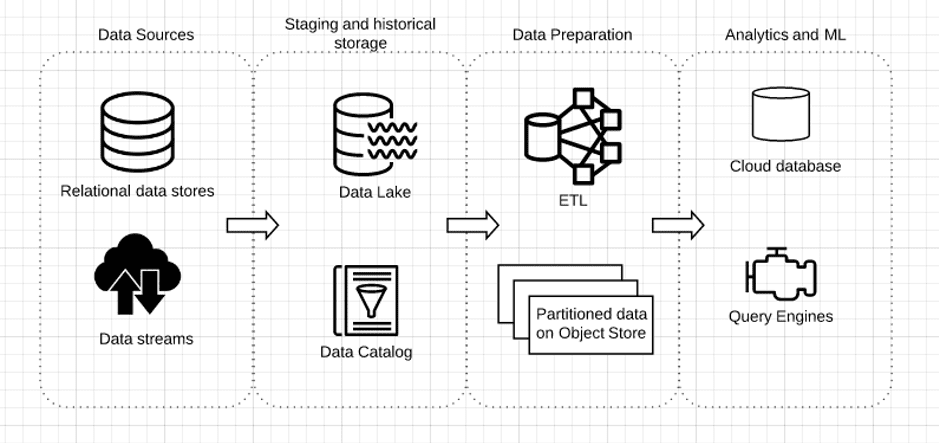
In the suggested architecture, we are keeping all the data generated across the organization in one centralized location — this will be your data lake. Any object store such as Amazon S3 will be a good fit here. We have divided the data your organization generates into two broad categories:
- Relational data such as database tables and spreadsheets, which would typically be used in business departments and applications.
- Streaming data such as sensor output, application logs, and mobile interactions, which would typically be of interest to technical departments.
In the first stage, we perform minimal transformations on the data and store all the raw data in our object-store. This removes much of the initial data preprocessing that would need to be done before loading the data into an enterprise data warehouse, such as IBM Netezza. Since we are shifting a cloud data lake, our architecture will be predicated on the principle of “store now, analyze later” — with the relevant ETL work being moved to the next phase, based on the types of analyses and use cases which we eventually want to build. This enables us to store petabyte-scale data much more easily and cost-effectively.
The next phase will be ETL (extract, transform, load) — where we will be preparing the data for analysis and writing it to a cloud-based data warehouse or analytics engine (like Amazon Athena), which analysts and business users can then use to answer business questions.
Having a data lake before your data warehouse will help you go through the migration process to the cloud and deal with both existing and future complex business problems. Following the guidelines we’ll present in the next section will ensure you end up with an agile and performant enterprise data platform rather than a data swamp.
Ensuring Agility in the Cloud
Moving your Data Architecture to the cloud does not magically ensure it will meet your business requirements. You need to design a data platform that empowers teams across your organization to access and manipulate data in order to answer their own business questions. If you’re still relying on IT-intensive operations to ingest and prepare data for every new business question, you’ve mostly just moved your legacy headaches with you to the cloud.
With that in mind, here are four guidelines to ensure your post-migration data lake provides the value you expect.
Open Architecture Rather than Database Lock-in
Existing business problems in the fields of Data Science, data serving, text search, and more require modern query engines. Relying on a data warehouse for your analytics solution is not sufficient due to the lack of a good built-in analytics solution in the data warehouse package.
Data warehousing solutions are aimed at solving data storage problems rather than analytics problems. While the newest generation of high-performance databases is geared more towards analytics, these tools still suffer from limited extensibility, rely on proprietary file formats, and force lock-in to a specific vendor.
In the suggested architecture above, the data lake is being used as a staging area for your data. Using your data lake as a staging area while both storing your data in the data lake in an open format and metadata layer enables your organization to use various existing and future query tools for accessing data stored in your data lake. For more about this, check out the principles of data lake architecture.
The specific tools you use to query data will probably evolve over time and may require different optimizations, but the baseline is common — you’re going to need to have open format storage and metadata as data volume increases to avoid chaos. The tools will integrate with your data lake infrastructure due to its open architecture and lack of lock-in.
Unlock Innovation Through Ubiquitous Access to Data
Data in a database is the result of lengthy table modeling and ETL. Some consumers want access to the raw source, and only using a database will block that innovation. In addition, every theory they come up with can be tested retroactively with reprocessing instead of waiting for new data to accumulate.
In your Big Data Architecture, you want to ensure different consumers can access the data using the tools they are familiar with. For analysts, this would mean SQL. Data scientists might prefer Python or R, but you want to avoid having your data locked behind coding languages such as Scala. When every new dashboard or hypothesis needs to be an R&D sprint, the ability to rapidly iterate with data grinds to a halt.
For access to data to become a reality rather than a slogan, you need to apply a low-code or no-code approach across your entire data value chain. Non-coders should be able to grab the data they need, define the schema and tables, and run the analysis — all with minimal oversight from data engineers, who should act as enablers rather than executors
Increase Operational Availability with Historical Replay
Keeping a copy of the raw data enables an event-sourcing architecture. With this architecture, the raw data is stored as an immutable log of events, enabling end-to-end data lineage and the ability to fix production errors by reprocessing the lake data with a new ETL code. If there wasn’t a data lake, the IT person would need to find a DB backup to work with and merge it with the existing database. That’s both risky and time-consuming.
In addition to storing a copy of all the relevant historical data on inexpensive object storage, you need to be able to capture data changes in order to be able to quickly revert to a historical state.
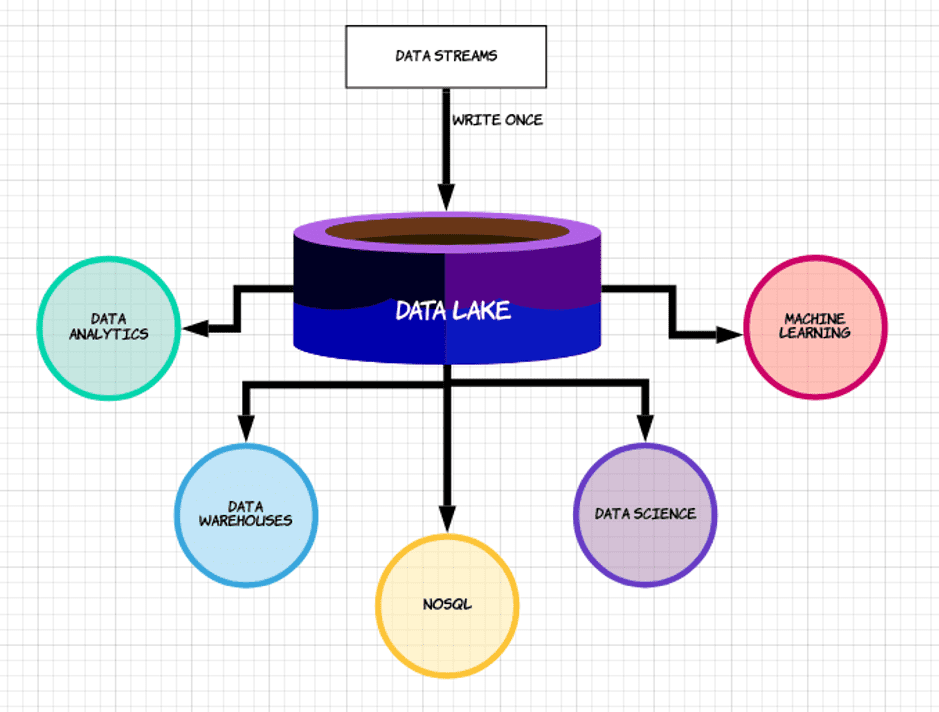
Reduce Costs by Replacing ELT with Data Lake ETL
One of the reasons organizations want to migrate away from data warehouses is that they are more busy processing ELT jobs than actually serving analytics users. Large scale joins and aggregations are notorious for consuming data warehouse resources, causing slowdowns for analytics users, and wasting valuable DBA time.
Additionally, ELT processes keep most of the data cleanup logic in one database. If you want to use this data for a different use case, you’ll need to do replication, which is another painful process to manage.
By moving the data transformation to the data lake (data lake ETL), analytics databases can be focused on serving users, and adding additional databases becomes easy since the data (raw and clean) is accessible for the lake.