
Click to learn more about author Juras Juršėnas.
Not all machine learning applications have been met with resounding success. In fact, there’s a lot of disappointment involved. From overly ambitious projects to the expectation of ever being a finished product, machine learning is marred with false hope.
I think Andrey Kurenkov has done a stellar job outlining the weaknesses in his article. Machine learning (or AI, in his case) is:
- Data-hungry (or sample-inefficient). Acceptable models require inordinate amounts of data.
- Opaque. At best, we can make a few educated guesses on what’s truly going on under the hood (more applicable to reinforcement learning than other methods).
- Narrow. They can do one particular task, can be easily broken, and cannot transfer knowledge to other tasks or models.
- Brittle. Only generalize well to unseen inputs after having accessed huge amounts of data.
However, it’s not all doom and gloom. Machine learning models are incredibly effective at specific sets of tasks. If applied correctly, the entire process of training one can be more than worth it. They can bring exceptional efficiency and bring out completely new features that put you ahead of any competition.
What Is Machine Learning Good At?
You likely have had this experience: You see someone’s face on the street and recognize them as a familiar person. Once you get closer, a realization dawns – it’s a complete stranger.
What has likely happened is that your brain matched many different patterns and according to available information, assigned a specific prediction. In this case, it was a false recognition of a friend or acquaintance. However, such a prediction is only possible due to the ability of your memory to hold vast amounts of information.
Most businesses will deal with machine learning models that do much of the same. All of them are stochastic. They make predictions based on a (admittedly, painfully) large amount of data and training. These predictions are either classifications or random variables (based on regressions).
Classification is intuitive even for those outside the fields of logic, math, or programming. You have a set of N objects with X amount of categories (e.g., hats, dogs, pants, etc.). Moving these objects to their respective category is classification. But machine learning models, unlike humans, are still making predictions. They are never 100% certain about the essence of the object provided.
Regression is a bit more complicated and requires some math to be explained. Say you wanted to measure the correlation between employee age (X) and salary (Y). Collecting the required data means you will have a set of value pairs (X:Y). If it’s a simple linear regression, it can be expressed by:
Y = a + Xb, where a and b are unknown coefficients. A regression-based machine learning model will be finding these.
A simple solution is to plot these data points out on a graph. Often, they will look something like this:
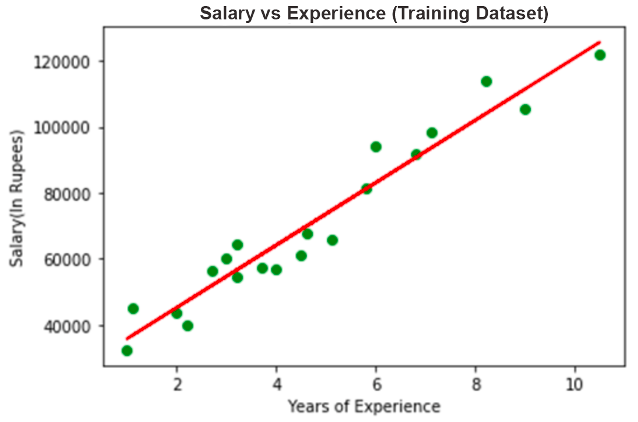
Finding these coefficients is often not as simple, as they will change when more data is introduced. However, there are some fancy statistical tools that are used to maximize accuracy: Mean Squared Error (MSE) and Gradient Descent. Simplifying it (by a lot), we basically pick two random coefficients and draw a line. Then each dot and its distance squared to the line is calculated separately. After that, the process is repeated numerous times to minimize the average distance between the dots and the line (also called the cost function).
I won’t be getting into the meat of the statistics. What’s important is that the machine learning model, after sufficient training, will be able to provide predictions from just one set of variables. Continuing the example, it will be able to take just a set of years and produce predictions for salaries (and vice versa).
These two are the most popular options for machine learning models. Of course, they can be significantly more complex and solve problems through several sets of tools. Some of them I have avoided mentioning here (e.g., clustering and dimensionality reduction) as they are the less popular options.
Specific Tools for Specific Problems
As I’ve briefly covered above, machine learning is not designed to solve everything. There are two specific sets of problems that it’s good at. Everything else is likely an attempt to teach a fish to fly. Although, I should mention that the number of problems that can be solved with extremely clever applications of machine learning math is greater than may seem at first glance.
Before getting into the heat of things, we should keep in mind one important caveat: Machine learning is bad at tasks that have a lot of (potentially) unique variations. Put simply, models will have an easier time learning to differentiate between hats and dogs than learning to write novels in English. In other words, it’s easier to conceptualize the idea of an abstract “average” hat and “average” dog than an abstract “average” text in English.
As a rule of thumb, models are bad at what most people call “creative” tasks (lots of potential unique variation) and good at “logical” tasks (comparatively little unique variation). While making models for both types is possible, “creative” ones will simply be too resource-intensive for most businesses. Therefore, we should be looking to automate tasks that have small variations between data points. That’s something that machine learning models are really good at.
Another important aspect to take into account is scalability. Machine learning is great at problems that need to be solved at a large scale. If your business receives dozens of emails a day, you can probably go through them manually. As the joke about developers goes, you would be taking hundreds of hours to automate a 10-minute task.
Finally, think whether the solution is solvable through a rule-based approach. You don’t need a machine learning model to, say, block access from or to specific IP addresses. Testing the waters through a rule-based approach is the way to go.
Business Limitations
There are some simple business considerations to take into account before starting out in machine learning. Unfortunately, machine learning is time- and resource-intensive. You will need to have dedicated experts working primarily on the model continuously (from collecting data to testing the model). If you don’t have experts or it simply isn’t financially viable to maintain the model, even if the fit is perfect, the idea will have to wait.
As a corollary, it’s important to take stock of the availability and expertise of your development teams. Developing a highly accurate and functioning model is a full-time job for several people. At least one developer will need to be completely dedicated even for a simplistic model. Additionally, someone will have to procure the data necessary, which might necessitate some outsourcing.
In the end, it’s always at least partly about weighing the potential benefit of automation against the high cost.
Machine Learning: If at All and Where
By now, it should be clear that if your business mostly involves artistic tasks, you are less likely to find success with machine learning. However, that doesn’t mean there wouldn’t be any use for it.
What we did at our company before deciding to create our first machine learning model is to dissect and deconstruct one of our solutions. We landed upon Real-Time Crawler (essentially, a tool that our clients use for public data web scraping) as it’s our most complex tool.
So, our solution gives our clients an opportunity to do web scraping without programming something from the ground up. Web scraping involves several steps – going to URLs, downloading the content in HTML, storing it in memory, parsing (in some cases), and delivering the data extracted to the destination. Then, some proxy rotation and HTTP header changes happen.
Users take care of the URLs. Content downloads are already optimized and there’s nothing to do for the delivery process and memory storage. However, parsing (making the data easier to understand and use) is an incredibly difficult task due to numerous reasons I won’t be outlining here.
Luckily, data on the internet is (almost exclusively) stored in HTML. It’s one language, usually reserved for browser-use, that has some variation and creativity but also relies on a strong identical foundation. In essence, it’s nearly impossible to write a rule-based approach that would be able to parse different sources of HTML but for the human eyes all of it looks frustratingly similar – a perfect candidate for machine learning.
But we didn’t stop here, as the potential variation is still too vast. We checked several things: for which data sources parsing was requested most frequently. Our teams discovered that there was a significant uptick in parsing requests in a specific category of web pages. That seemed to be a narrow-enough field for our project.
Finalizing Your Decision
I personally think this is the correct way to approach machine learning applications. First, categorize, dissect, and deconstruct your product or service into sequences or smaller parts. Second, take a smaller part of the entire process, think about what is the problem(s), and how it’s being solved. Third, use data to narrow down to the most important aspect and apply machine learning there.
Working your way up through problems is going to save a lot of time, resources, and headaches. You can always make more models if you’ve already got a smaller working one. You can’t make anything out of a nonfunctional large model.