
To make Data Science part of business value creation, business users have to be part of the Data Science lifecycle. They need to be able to go back to Data Science teams and provide feedback so that the Data Science process reflects their requirements — and quickly. Models may need to be updated or functionalities automated, for instance.
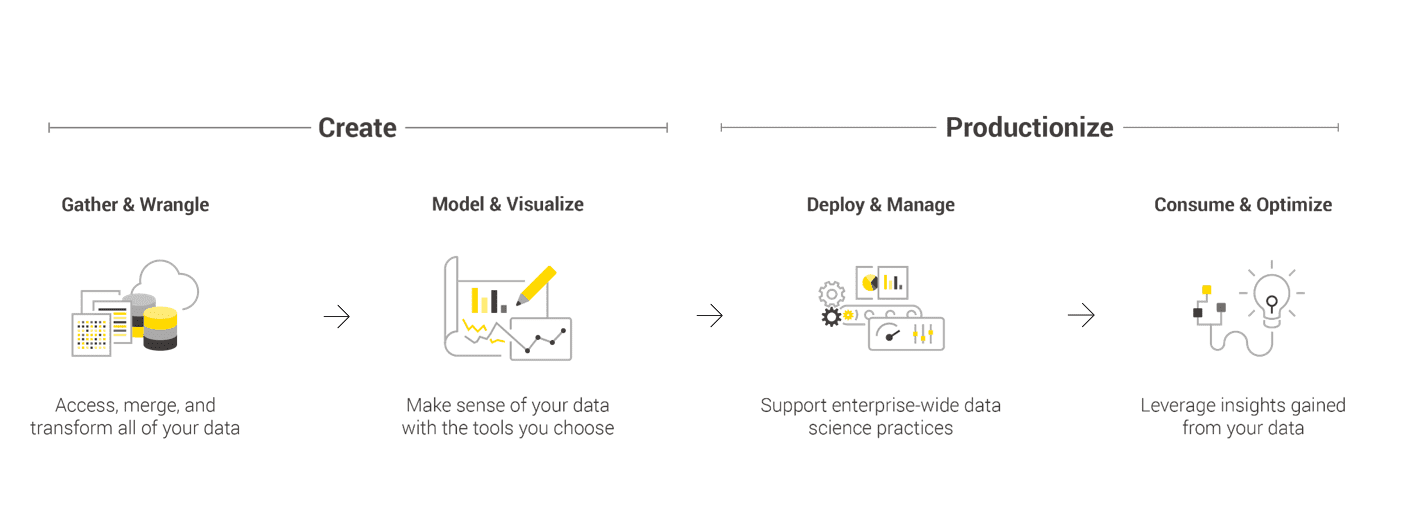
What businesses need is Data Science productionization. That’s the merger of creating Data Science applications and services and productionizing them through enterprise-wide Data Science practices and business user consumption and optimization.
Many companies aren’t quite there yet. “We’re at the beginning of the curve,” said Michael Berthold, CEO and co-founder of Data Science platform KNIME. “A lot of companies talk about end-to-end Data Science, but mostly they’re thinking about data wrangling for colorful reports. They’re ignoring productionizing.”
It’s a maturity issue, he said. Think of it like software engineering a couple of decades ago: practices were a lot more chaotic compared to today when there’s more discipline around building and maintaining professional software.
Similar discipline is moving into the Data Science realm. Companies are increasingly realizing that it’s important to create and productionize Data Science in an end-to-end environment.
Gartner has explained today’s Data Science requirements in its 2019 Magic Quadrant for Data Science and Machine Learning Platforms.
“To achieve fully mature advanced analytic capabilities, organizations should provide capabilities across the end-to-end analytic pipeline,” it reads. “The pipeline includes processes for accessing and transforming data, conducting analysis and building analytic models, operationalizing and embedding models, managing and monitoring models over time to reassess their relevancy, and adjusting models to reflect changes in the business environment.”
Gartner named KNIME a leader in the Magic Quadrant, along with Tibco Software, RapidMiner, and SAS.
Data Science Challenges
Berthold talks about the challenges of productionizing Data Science as he sees it. There are different ways of consuming Data Science and productionizing it. It can be automated, rely on APIs, or be customized.
Automating it for business users using a “black box” vendor requires some caution as it depends on the vendor keeping the product up-to-date so that it continues to provide the insights the business needs. And it requires that data be up-to-date, and wrangling data requires extra effort.
Using reconfigured, trained models with Data Science APIs is a good way to handle standard problems like image classification. But it’s important to ensure that the model was trained on the right data with the right goal in mind and that the results are stable and usable. The API approach also can be an issue because you can’t count on backwards-compatible upgrades.
Custom Data Science makes it possible to leverage messy data and it is adaptable to ongoing change. It’s possible to pull data from different sources — on-premise, cloud, and so on. But when the model has to be handed off and recoded to put into production, operationalization problems can occur. That’s why it makes sense to use the same environment to productionize what has been created.
Custom Data Science also makes it possible to assure reliable and reproducible results; that means you can use what was built a couple of years ago with confidence. “Backwards compatibility is hugely important,” he said.
Two-Pronged Approach
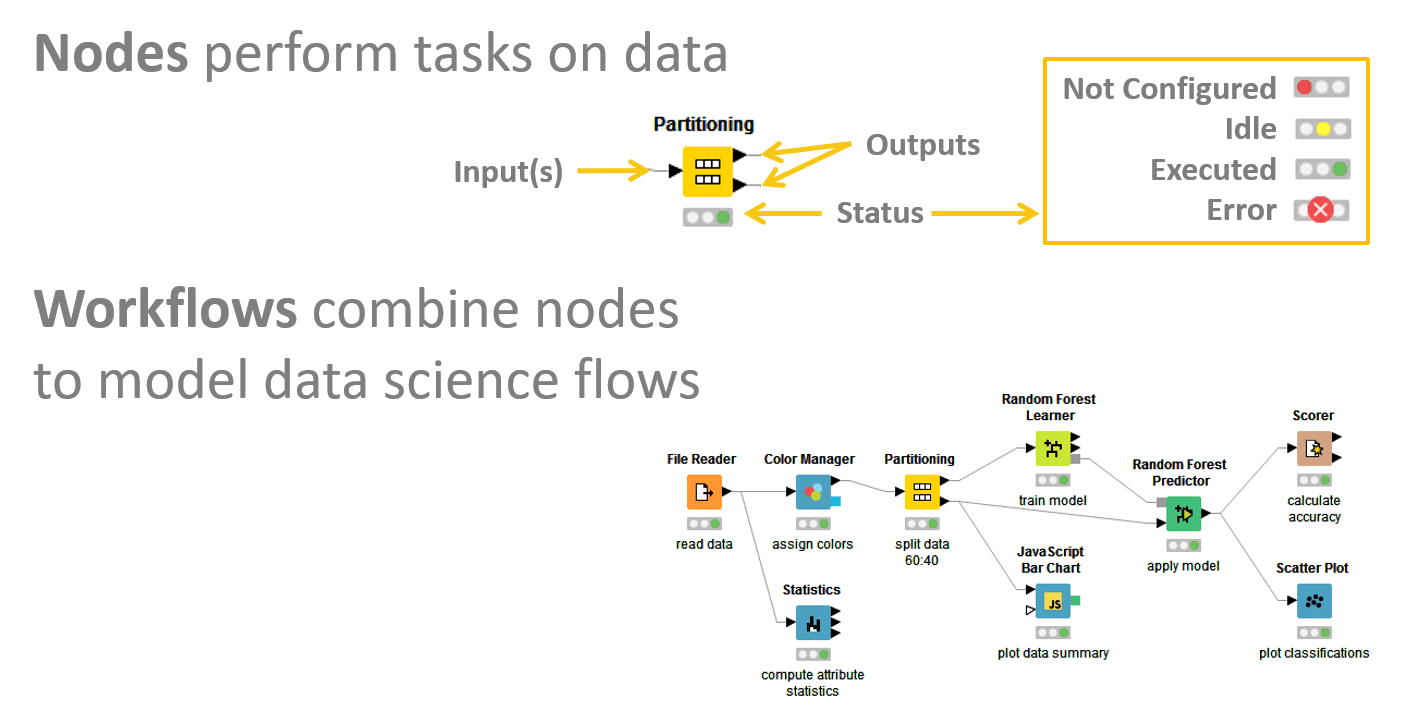
KNIME’s approach to helping organizations achieve Data Science maturity with an end-to-end solution splits its software platform into two pieces. KNIME Analytics is open source software for creating Data Science applications and designing visual Data Science workflows with no need for coding.
API nodes are the smallest programming unit in KNIME that each serves a dedicated task, and KNIME has 2000 available nodes to build workflows. Companies can integrate Python or R when there isn’t a pre-built node. As open source software, extensions are contributed by the community.
“Community-based Data Science is about sharing,” said Berthold. KNIME provides workflow templates for use cases including customer intelligence, social media, finance, manufacturing, pharma/health care, retail, government, and cross-industry.
“Hard-core data scientists will build their own complicated workflows from scratch,” he said. “But in reality, a lot of people start with examples — blueprints, and they only need to change a few components.”
The server productionizes work with team collaboration to build and revise workflows, and to retain knowledge of those workflows for successfully reusing them. Workloads can run on schedule as well as remotely and be monitored if configuration changes are needed, and permissions and control access on these as well as on data files can be built for compliance requirements.
It’s possible to take snapshots to keep track of changes in order to roll back to a previous workflow version if required. “We have backwards compatibility,” he said. “You may retire some code but if you load the whole workload you can still use the retired code and know the workload produces the same result.”
Business users have access to the server through its WebPortal or REST APIs. A cloud-based collaboration solution is available for smaller groups that don’t want their own server, he said.
With the total package, users don’t have to move data between applications or platforms to complete projects. Raw data is easily ingested, assessed (statistics), viewed (charts), processed (machine learning), and exported to various formats.
The Latest News
KNIME has introduced new versions of its open-source solutions: KNIME Analytics Platform 4.0 and KNIME Server 4.9.
It’s now possible to search the Hub, which is where users can find workflows, nodes, and components from within the Analytics Platform. The extensions on the KNIME Hub can be browsed to quickly learn about all nodes of an extension and explore related workflows to find examples of how to use this extension. Nodes can be dragged and dropped from the Hub into the Platform.
Machine learning interoperability is enhanced to help users have a better grasp on complex models. New nodes give explanations for how models behave on a per row basis to better understand how it predicts individual rows. There is also machine learning integration with AWS.
With the KNIME Server update comes the ability to edit workflows directly on the Server. Users can directly browse the KNIME Server repository from File Reader/Writer nodes and views on database output ports.
Image used under license from Shutterstock.com