
Click to learn more about author George Demarest.
It is the nature of software engineers to quickly adopt new, superior algorithms, tools, and approaches while they quickly and unceremoniously jettison the old. The most positive result of these impulses is rapid and continuous innovation – which savvy business leaders can turn to their advantage. The less positive result is technical debt, the aftermath of having to pick up the mess you made yesterday.
This dynamic is now playing out in the ongoing story of online analytical processing (OLAP). As a quick refresher, let’s see what our friends at OLAP.com have to say:
“OLAP performs multidimensional analysis of business data and provides the capability for complex calculations, trend analysis, and sophisticated data modeling. It is the foundation for many kinds of business applications for Business Performance Management, Planning, Budgeting, Forecasting, Financial Reporting, Analysis, Simulation Models, Knowledge Discovery, and Data Warehouse Reporting.”
That all sounds fine. So what’s the problem? The problem is data. Lots of data. Big data. Too much data for traditional OLAP systems such as Microsoft SSAS or IBM Cognos. BI teams have been asking more and more of their OLAP platforms and the result is that these systems are collapsing under the weight of this new data.
So, in this era when cloud analytics is expected to grow at 23% CAGR, many reason that “we can do that in the cloud instead.” On the face of it, it makes sense. The cloud provides “unlimited power” and “unlimited scale” – just the thing for “unlimited data.” So let’s start over using this shiny new big data stack. Right?
Hold on. Let’s not throw the champagne out with the cork.
With OLAP tools, techniques, and databases burning brightly for more than a decade, there is considerable technical debt that may still be able to be turned into profit. In other words, there are some very useful ideas behind the OLAP model that still make sense in the cloud era. One is the precomputation of results and the creation of data structures called “cubes,” in the OLAP lingo.
With today’s rich new set of algorithms like recommendation engines, predictive analytics, and user behavior analysis, we can certainly benefit from the multidimensional analysis that OLAP enables. So, why not have that arrow in your quiver if you are an application architect or full stack developer?
And what about the data? Many companies have invested untold time, effort, and budget into the organization of data into high-performance, multidimensional OLAP cubes. This type of intellectual property could be worth millions if there were a way to bring it forward into the cloud big data stack. This is actually happening both in the open-source world (Apache Kylin), and the commercial (AtScale, Kyligence, IBM). This bodes well for the options that customers have for their cloud analytics ambitions.
As more and more analytics are done in the cloud, cloud resources (CPU, storage, network) and associated costs will become a critically important commodity that must be scrutinized, managed, and optimized.
Prior to running big data analytics on infrastructure for hire from AWS, Microsoft, and Snowflake, a macrocosm of this same challenge played out on-premises. But cloud OLAP must be – and is – significantly better than its ancestors. While individual solutions vary, they all seek to gain advantages from a cloud-native approach.
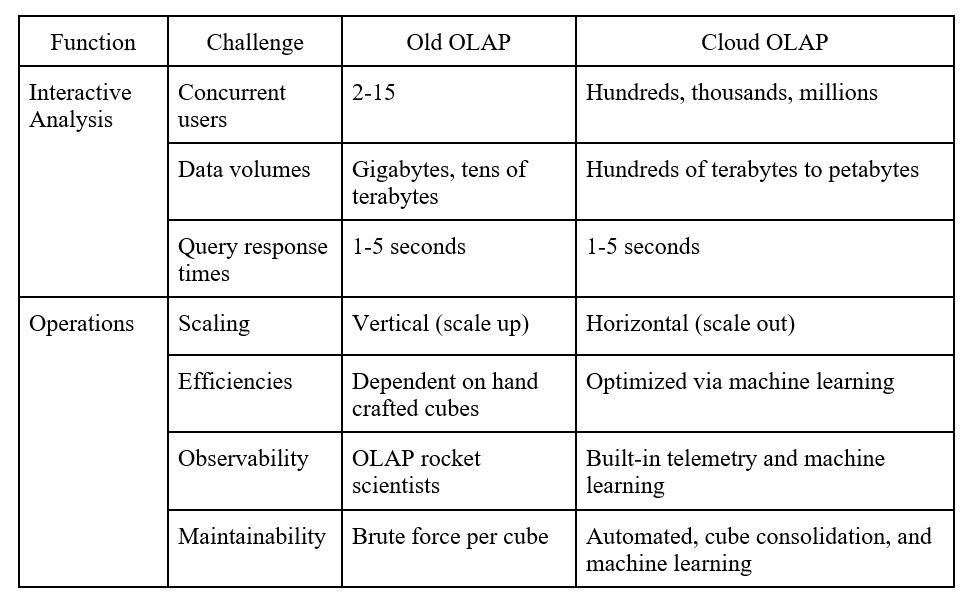
As we compare old and new approaches, we see how cloud-native OLAP seeks to repair the limitations that have dogged traditional OLAP.
Scale
It was scale that eventually threatened the life and value of traditional OLAP. OLAP databases were designed for single-server operation and could scale up only through larger and larger servers. Cloud OLAP can handle thousands, and eventually even millions of active, concurrent users by distributing processing across clusters, or scaling out.
Speed
Traditional OLAP systems eventually got so bogged down by data volumes that they have become unusable. Dashboards must be interactive or why bother? This is the one requirement that has remained constant. You can’t have a dashboard that has a “go get some coffee” light on it. Cloud OLAP can deliver predictable response times under five seconds regardless of the data volumes.
Immediacy
A common complaint of traditional OLAP was that it required highly trained OLAP experts to design, configure, and maintain the environment and the data (cubes). This required specialized skills that were hard to come by and hard to retain. Cloud OLAP must be far easier if it is to succeed. Machine intelligence needs to be applied to the process of designing, optimizing, and pruning OLAP datasets so that cloud resources are not squandered through inefficiency.
Teachable
Cloud OLAP needs to learn on its own. The system needs to get smarter, more automated, and self-tuning. The movement to apply machine learning across IT functions must also apply to analytics infrastructure and operations.
Even Intelligence Should be Smart
The role of cloud OLAP is to reduce the brute force processing of data analytics in the cloud in favor of smart organization of data into optimized, multidimensional data structures that are faster and easier to read. That could drastically reduce the number of queries that are hammering away at your cloud warehouses and data lakes. In the cloud era, accounting for every last CPU cycle will increasingly become the name of the game. When processing vast datasets in the cloud, that CPU clock is ticking, and that is straight-up cost.