
Click to learn more about author Martyna Pawletta.
Let’s see if we can serve pizza via the Semantic Web and an analytics platform. Will they blend?
Ontologies study concepts that directly relate to “being,” i.e., concepts that relate to existence and reality as well as the basic categories of being and their relations. In information science, an ontology is a formal description of knowledge as a set of concepts within a domain. In an ontology, we have to specify the different objects and classes and the relations — or links — between them. Ultimately, an ontology is a reusable knowledge representation that can be shared.
Fun reference: The Linked Open Data Cloud has an amazing graphic showing how many ontologies (linked data) there are available on the web.
The Challenge
The Semantic Web and the collection of related Semantic Web technologies like RDF (Resource Description Framework), OWL (Web Ontology Language), or SPARQL (SPARQL Protocol and RDF Query Language) offer a bunch of tools where linked data can be queried, shared, and reused across applications and communities. A key role in this area is played by ontologies and OWLs.
So, where does the OWL come into this? Well, no — we don’t mean the owl as a bird here — but you see the need for ontologies, right? An OWL can have different meanings, and this is one of the reasons why creating ontologies for specific domains might make sense.
Ontologies can be very domain-specific, and not everybody is an expert in every domain — but it’s a relatively safe bet to say that we’ve all eaten pizzas at some point in time — so let’s call ourselves pizza experts. Today’s challenge is to extract information from an OWL file containing information about pizza and traditional pizza toppings, store this information in a local SPARQL Endpoint, and execute SPARQL queries to extract some yummy pizza, em — I mean data. Finally, this data will be displayed in an interactive view, which allows you to investigate the content.
Topic: Meet the Semantic Web
Challenge: Extract information from a Web Ontology Language (OWL) file
Access Mode / Integrated Tool: Semantic Web/Linked Data Extension —
the ontology used in this blog post and demonstrated workflow is an example ontology that has been used in different versions of the Pizza Tutorial run by Manchester University. See more information on Github here.
The Experiment
Reading and Querying an OWL File
In the first step, the Triple File Reader node extracts the content of the pizza ontology in the OWL file format and reads all triples into a Data Table. Triples are a collection of three columns containing a subject(URI), a predicate(URI), and an object(URI or literal), short: sub, pred, obj. The predicate denotes relationships between the subject and the object. As shown in the screenshot below (Figure 1), in the example, we see that the Pizza FruttiDiMare is a subClassOf the class NamedPizza and has two labels: a preferred and an alternative one.

Once the Triple File Reader is executed, a SPARQL Endpoint can be created using the Memory Endpoint together with the SPARQL Insert node. This allows the execution of SPARQL queries. Note that our Triple File Reader does not officially support the OWL format. We can read RDF files and, consequently, because OWL files are very similar, we can read these files too. However, not all information is necessarily retrieved, as OWL can have additional parameters.
The example in Figure 2 shows a SPARQL query node that contains a query to extract a basic list with all pizzas included in the OWL file.
A recommendation here: If the ontology you want to query is new to you — I would highly recommend exploring the structure and classes first quickly in another tool like Protége. This makes it easier later to create and write SPARQL queries.
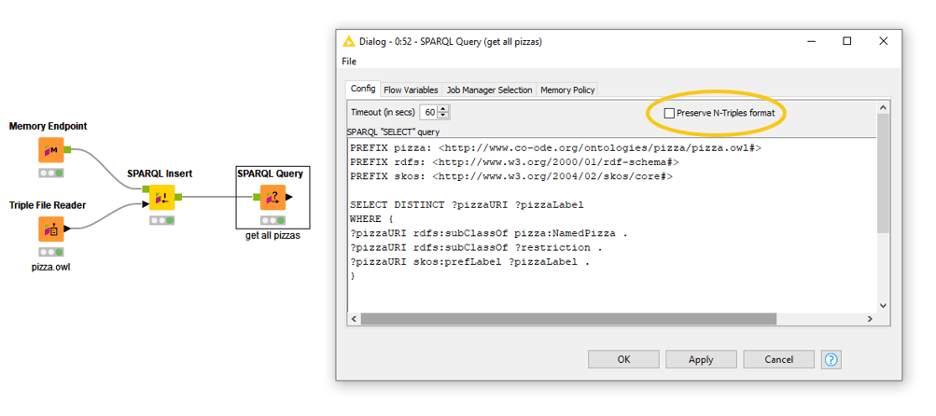
The SPARQL query node has a checkbox on the top right (see Figure 2), saying “Preserve N-Triples format.” Selecting this makes a difference in terms of what the output data will look like. The N-Triples format needs to be kept if the triples will be inserted into an endstore.
The example below shows the effect of not checking (top) or checking (bottom) on the N-triples checkbox. In the case of URIs, the angled brackets are not preserved in terms of literals quotes, and type (here @en) will be removed if nothing has been selected.

Visualization
There are different ways to visualize data here. In the case of ontologies, it’s really dependent on what you are aiming to do. Here, we will extract a bit more information than in the first example and create an interactive view within a component that allows us to explore the content of the pizza ontology.
Additional to the pizza labels now using two SPARQL query nodes (see Figure 3), further information like toppings per pizza type or its spiciness were extracted. Also, we query for pizza toppings that are a subclass of the class VegetableToppings and create a flag if the topping is a vegetable or not using the Constant Value Column node.
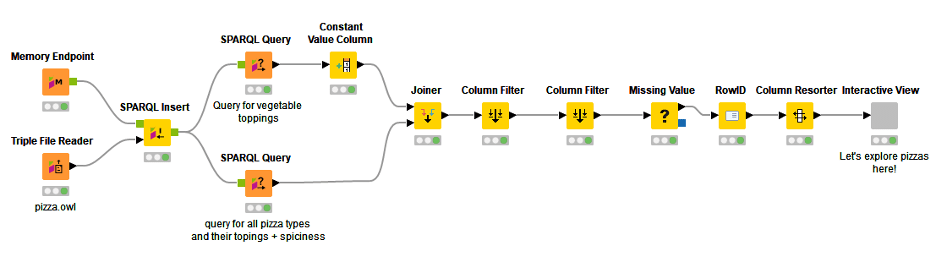
Finally, we create an interactive view where the extracted data can be explored (see Figure 4). To open the interactive view, right-click the “Interactive View” Component plus select Interactive View.

Is It Real?!
When I first looked at the dataset using the view, I saw the “Sloppy Giuseppe” Pizza and directly had to google it as it was something completely new to me. I saw the toppings but was wondering if this was something really Italian? This brought me to the idea of adding another feature here in addition to the tables and charts.
If you now click on the Pizza name, a new window will open, showing Google search results for that specific pizza type. I did this using the String Manipulation node, which creates a link. To make sure the link opens in a new window and not in your current view, the “target=_blank” option needs to be included.

The Results
We showed today how to extract data from an OWL file and create a SPARQL Endpoint and SPARQL query. Finally, we generated a view where the content can be explored.
After playing with such yummy data … hungry now? Let’s order a pizza then?
Download the workflow “Exploring a Pizza Ontology with an OWL file” from the Hub here.
In this “Will They Blend” series, we will continue experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with NoSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: Will they blend? Want to find out what happens when website texts and Word documents are compared?