Click to learn more about author Akshay Pore.
NoSQL databases have seen increased adoption in the last five years. A growing number of companies have at least one NoSQL database as a part of their enterprise data landscape. In today’s IT environment, where DevOps, SAFe and Agile are being increasingly embraced, utilization of NoSQL database for application development is seen as a huge advantage in speeding up time to market for software products.
Developers have been quick to adopt NoSQL databases due to their flexible schema, efficient processing & storage of unstructured & semi-structured data and ability to support high performance queries in a scale out environment. In the case of some NoSQL technologies, developers can create the schema and design the database through their application code without the data team’s involvement. However, a lack of formal design and inadequate processes around the execution can have unintended consequences for the application and can affect overall data governance for the enterprise.
For example:
- Due to the flexible nature of the schema, capturing the data model is a challenging and time-consuming task. It is difficult to determine what is stored where during the future development sprints. It also poses a major challenge for auditing & compliance reporting for companies.
- Furthermore, each type of NoSQL database technology is developed for a specific set of use cases. There are chances that more than one type of NoSQL database along with an RDBMS component will be used for a single application. A stronger Data Governance framework is required to understand the data being stored in such variety of database technologies.
- Dynamically created database objects can cause schema inconsistencies and unforeseen Database Management issues resulting in increased time to troubleshoot. The DBAs and other data professionals may have to review the application code to understand the schema and determine if the issue is in the data, schema or the infrastructure (database clusters).
Hence, there is a need for developing an end-to-end Data Architecture & Governance framework for assimilating NoSQL database technologies in enterprise Data Architecture. In this series of blog posts, I will try to cover all aspects of adopting and maintaining a successful NoSQL portfolio for an enterprise.
The first step in this journey is to understand the different types of NoSQL technologies and the reasons behind their evolution. This is important because, unlike RDBMS where the schema is database agnostic, the NoSQL technology type drives the schema design.
NoSQL technology types can be broadly classified into four categories based on their database model implementations as follows:
- Key-Value Stores
As the name suggests, this type of NoSQL database implements a hash table to store unique keys along with the pointers to the corresponding data values. The values can be of scalar datatypes such as integer or complex structures such as JSON, List or BLOB etc. Key-Value stores are simplest type of NoSQL databases to design and implement. Clients can use get, put and delete APIs to read and write data and since they always use primary key access, they very easy to scale and provide high performance.
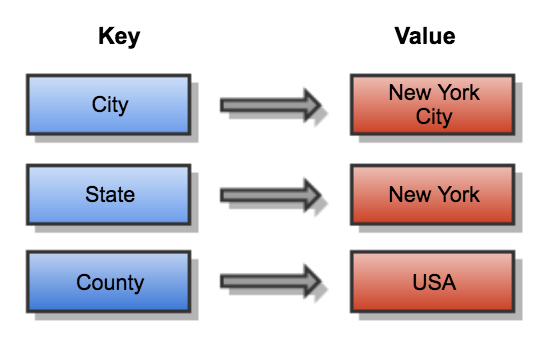
Key-Value stores are ideal for applications with simple data models and require high velocity read & writes.
Sample use cases include:
- Session management
- Profiles, preferences & configurations
- Data Caching
- Storing multimedia files or large objects
Key-Value stores are not suitable when the application requires frequent updates or complex queries involving specific data values, multiple unique keys and relationships between them.
Examples of Key-Value databases include – Redis and Riak.
- Document Stores
Document Stores are similar to Key-Value stores, as there is a key and a corresponding value, but the value provides structure to the stored data in XML, JSON or BSON formats. This value is referred to as a document. Each document is effectively an object containing attribute metadata along with a typed value such as string, date, binary or an array. This provides a way to index and query data based on the attributes in the document.
Document databases have flexible schema, each document can have a different set of attributes. Documents are grouped into containers based on business requirement. Relationships are not stores within such containers and hence, joins are not available in the database. Alternatively, a set of documents can be embedded within a document to provide a level of denormalization.
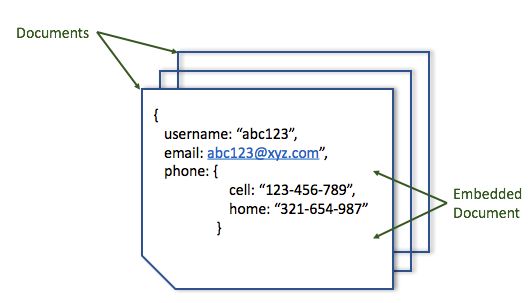
Due to its flexible schema and complex querying capabilities, Document Stores are popular and suitable for variety of use cases such as:
- Content management systems
- E-commerce websites
- Middleware applications that use JSON
Document stores are not suitable if the application requires complex transactions with multiple operations.
Examples of Document Store databases include – MongoDB and Couchbase.
- Column Family Database
In Column Family databases, data is stored in cells of columns, grouped into column families. These databases are implemented as multidimensional nested sorted map of maps. The innermost map constitutes a version of the data identified by a timestamp and stored in a cell. A cell is mapped to a column which in turn is mapped to a column family. A set of column families are identified using a row key. Read and write is performed using the row key on sets of columns. These columns are stored as a continuous entry on the disk enhancing performance.
Column Family databases are designed for large volumes of data requiring high availability and are well-suited for use case such as:
- Time-series data
- IoT applications
- Logging and other write heavy applications

Column Family databases should not be used for applications with ad-hoc query patterns, high level of aggregations and changing database requirements.
Examples of Column Family databases include – HBase and Cassandra.
- Graph Databases (Property Graphs)
A Property Graph consists of nodes and relationships between the nodes. Both nodes and relationships can store number of attributes called properties. Nodes are the entities in the graph and can be tagged with labels which can be used to provide context and metadata to the node. Relationships provide directed, bi-directional and named connections between two nodes. There can be more than one relationship between two nodes and each relationship has a direction, a type, a start node and an end node.
Graph databases can be implemented as a native graph; which means they store data in the graph model described above, while non-native graphs store data in relational or other NoSQL databases such as Cassandra and use graph processing engines for data access. Native Graphs implement index-free adjacency for data access.
Graph database is well-suited for applications traversing paths between entities or where there is need to query the relationship between entities and its properties.

Sample use cases include:
- Location & navigation based services
- Network and IT infrastructure
- Fraud detection
- Metadata Management
Examples of Graph databases include – Neo4j (native graph) and DSE Search/TitanDB (non-native Cassandra based Graph).
Another type of Graph is RDF Triple Store or Semantic Graph. These Graph databases differ from the Property Graphs in that they do not store properties for Nodes and Relationships. They are modeled in a Subject (Node) – Predicate (Relationship) – Object (Node) format. Semantic Graphs are used for Ontologies and metadata management. I will cover these in detail in another blog post.
As you have seen, these NoSQL database types are designed for specific use cases and directly impact data architecture for an application. Hence, we need to understand the implementation of each of these technology types in detail to efficiently design and model the database
In the next blog post, I will cover BASE & CAP theorem for NoSQL databases and analyze different factors that should be considered while choosing a right NoSQL database for your application.