
Cognitive Computing technologies have caused tectonic changes throughout the data industry: such as improving the cooling efficiency of data centers by 15%, detecting malware, customer support, and deciding which trades to execute on Wall Street.
To accomplish these types of tasks, computers need models. As Adrian Bowles quoted in a recent DATAVERSITY® Webinar: “There is no machine intelligence without (knowledge) representation.” Without some sort of useful map or scheme, Artificial Intelligence becomes noise, mere echoes between wires. Taxonomies and ontologies provide machines powerful tools to make sense of data.
What is a Taxonomy vs Ontology?
Taxonomies provide machines ordered representations. According to Bowles, a Taxonomy represents the formal structure of classes or types of objects within a domain. Bowles noted that taxonomies:
- Follow a hierarchic format and provides names for each object in relation to other objects.
- May also capture the membership properties of each object in relation to other objects.
- Have specific rules used to classify or categorize any object in a domain. These rules must be complete, consistent and unambiguous
- Apply rigor in specification, ensuring any newly discovered object must fit into one and only one category or object
- Inherits all the properties of the class above it, but can also have additional properties.
Bowles gave the following example of a Taxonomy:
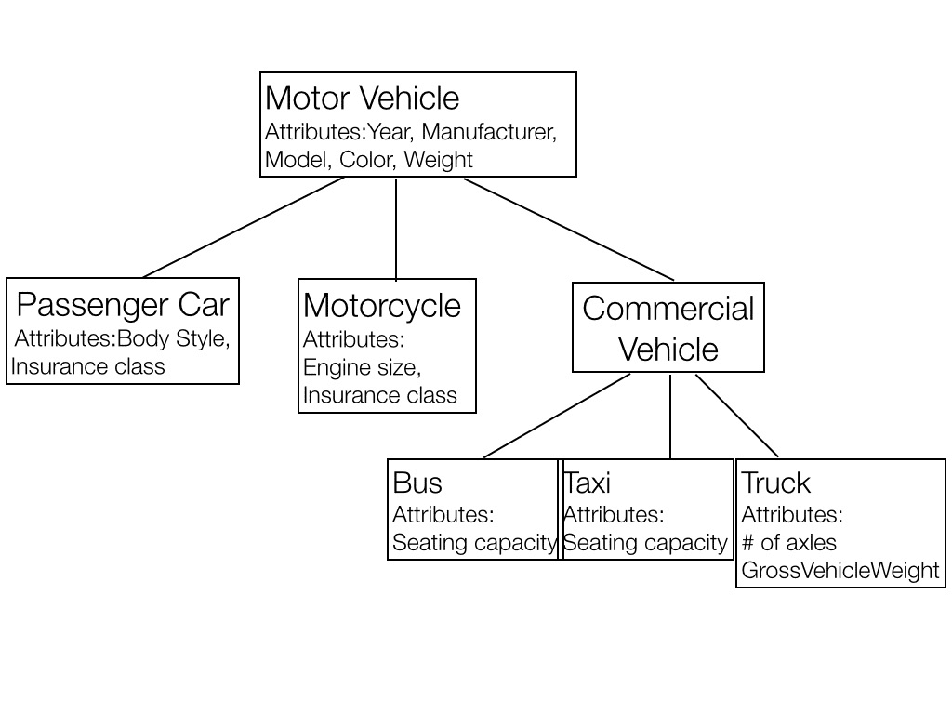
Image credit (Adrian Bowles – Smart Data Webinar)
Bowles said, that “this Taxonomy could have been organized differently, where [the vehicle] requires a special kind of license, it may be including off-road.” Regardless of how taxonomies are organized, they provide controlled vocabularies and information about the type of content. Specific types of Metadata could form taxonomies. Finding a book or document in a library or locating a specific website in Google, requires a Taxonomy.
Ontologies Explained
Bowles described Ontology as a subset of Taxonomy, but with more information about the behavior of the entities and the relationships between them. He defined an Ontology as a domain: “including formal names, definitions and attributes of entities within a domain.”
The W3C refers to an Ontology as a more complex and quite formal collection of terms. Consider the Ontology examples provided by Bowles below:
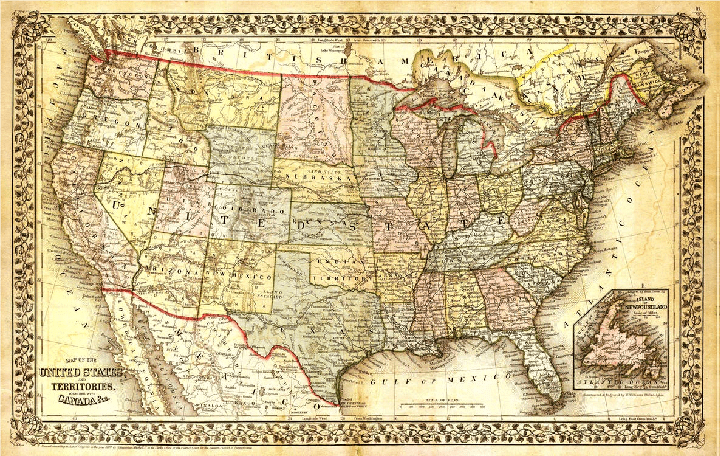
Map of the United States
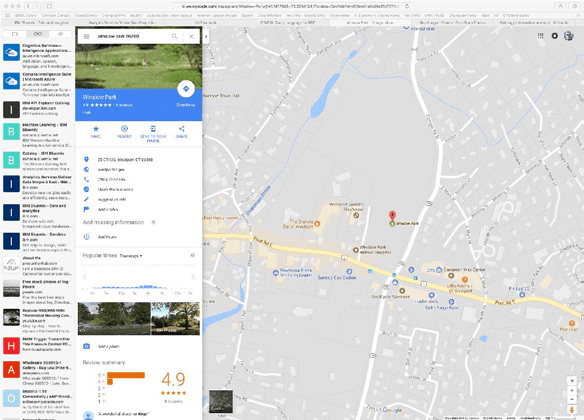
Directions to Winslow Park

The Winslow Park area
All three maps or domains contain Winslow Park and in a global sense, could be in the same Taxonomy. But these different domains or ontologies have very specific uses. For example, a history teacher lecturing on the history of Winslow park in the United States, may find the first map more useful.
The map of the United States would also help answer questions on locating all the Winslow Parks in the United States. However, a person wants to drive to Winslow Park in Connecticut from their house. The directions to Winslow park in the second picture provide the most help. What if someone is planning a company picnic and wants to know if Winslow park has a shelter? What if a person’s car has died near Winslow Park in Connecticut because the fuel gage is empty? The person needs the nearest gas station. The map of the Winslow park area, the third map, would provide the needed domain.
Ontologies factor the thinking about how a domain influences such elements as choices of maps and models, rules and representations, and required operations. Using taxonomies, alone, just does not model this type of thinking well. As Louis Sullivan stated in The Tall Office Building Artistically Considered, 1895, “Life is recognizable in its expression, that form ever follows function.” Ontologies provide representation of terrains that follow functions.
Importance of Taxonomy vs Ontology
Since machines need representations to be smart, why use taxonomies and ontologies as frameworks? Cannot a computer take any data and create a model to use for further learning? Bowles stated, “You can certainly do Machine Learning without an underlying Taxonomy or Ontology.”
Consider, though, a viable framework needs to provide Artificial Intelligence with the knowledge or ability to understand, reason, plan, and learn with existing and new data sets, and generate expected, reproducible results. A machine needs to take its knowledge, including facts or beliefs and general information within context, and apply this validly to existing or new inputs.
Well, how does a computer know it has generated a reasonable and expected result? This requires some supervised learning, where an instructor provides examples towards and guides the learning process to known solutions. To do this, computers need to develop effective neural networks that collaborate, and can using Deep Learning to recognize patterns.
Humans need to intervene, at least initially, to direct algorithmic behavior towards effective learning and neural network collaboration towards generalizing its knowledge when presented with future data. Using taxonomies and ontologies as tools to help machines learn and use its representations well with the promise of eventually requiring less interference by people.
Using Taxonomies and Ontologies
If machines learn efficiently using taxonomies and ontologies, then how can we apply these tools to a system’s architecture. Bowles said: “When we are trying to build up a system for reasoning, for communication, for doing cognitive work is to start with the idea of a Taxonomy.”
Taxonomies can be stored “using a variety of different data structures,” as Bowles discussed. “In a Relational Database, in a Draft Database, in a tool just for Taxonomies.”
The World Wide Consortium (W3C), a leading authority on the Web, provides The Simple Knowledge Organization System (SKOS). Based on the Resource Description Framework (RDF), a standard model for data interchange on the Web, SKOS makes it easy to read and create data in XML format. It allows for easier reuse of well-known vocabularies and the ability to create connections between contents that use the same vocabularies.
But, as Bowles stated, “Taxonomies are a lightweight version.” By adding Ontologies to a computer’s representations, machines can “process the content of information instead of just presenting the information to humans.” So that Artificial Intelligence can process such complexity and use Ontologies, the W3C recommends OWL, Ontology Web Language. OWL provides additional vocabulary along with formal semantics, facilitating greater machine interpretability of content. OWL is a “Semantic Web language designed to represent knowledge about things and relationships between things on the web.”
Since contexts change over time System Ontologies must be flexible. Bowles used the example of “autism” in the Diagnostic and Statistical Manual of Mental Disorders (DSM). Autism’s interpretation has changed over time based on additional knowledge gained by psychologists, educators, and other professionals. As Bowles noted:
“It is important to understand when the Ontology is put into use in some data repository, when the Ontology actually becomes the domain and evidence changes our understanding, we need to change the Ontology.”
As people develop taxonomies and ontologies, machines gain representations and new knowledge through symbolic logic and, more recently, statistical models, said Bowles.
“Systems that are really doing Machine Learning today, updating their knowledge base as a result of experience with data. Rather than reprogramming, will typically be using statistical models.”
Because of this, machines can update their knowledge independent of a programmer’s beliefs and assumptions.
Taxonomy vs Ontology into the Future?
By using taxonomies and ontologies, machines make “statistical inferences or statistical associations, based on proximity.” As Bowles noted:
“Machines can gather inputs and process these I through models, in the context of what is known. Computers then synthesize and analyze information to produce hypothesis about the inputs and classify the knowledge.”
As new inputs enter the AI system, it adapts and modifies its behavior. Systems that include this kind of Machine Learning include Siri, Alexa, Tesla and Cogito. So how will taxonomies and ontologies propel Machine Learning into the future?
Bowles noted that efforts are out there to give machines “prebuilt knowledge” based on common sense, general knowledge, such as (OpenCyc) or Off-The Shelf Knowledge, such as (WordNet). These computers will have a greater ability, based on their representations, to suggest medical diagnosis and treatments, analyze the impact of market trends or sudden developments in a customer’s financial status, and even take the role of a human customer service representative.
Brynjolfsson and Macafee, wrote in the Harvard Business Review:
“Machine Learning, is the most important general-purpose technology of our era. The impact of these innovations on business and the economy will be reflected not only in their direct contributions but also in their ability to enable and inspire complementary innovations.”
Taxonomies and ontologies form the building blocks to drive computer’s self-learning, opening a wide array of collaborations with machines leading to past unthinkable and new beneficial inventions.
Photo Credit: ESB Professional/Shutterstock.com


