
Key Takeaways
- In enterprise environments, AI agents can quietly compromise the quality of decisions made by them by providing them with stale, biased, or hallucinated context, a phenomenon known as context poisoning.
- Data security in any traditional computing focuses on access control and encryption; however, in agentic computing, the attack surface is the metadata layer.
- Adopting the principles of zero trust for the metadata layer, where context is verified for provenance, freshness, and semantic accuracy at each access, establishes a “metadata firebreak” to prevent context poisoning from spreading.
- Vector databases, in conjunction with orchestration patterns like the saga pattern, can ensure semantic truth at scale, but only if we apply the same discipline to the metadata layer as we do to our networks.
Why Your AI or RAG Pipeline Is Leaking the Truth
What if your AI agent is making confident decisions based on information that is no longer true (factual gaps)?
The vast majority of enterprises that have implemented AI agents to date tend to have tunnel vision regarding the accuracy of their AI models, prompt engineering, and output safety. All of these are important concerns to consider. Having spent almost two decades designing event-driven microservices, data streaming, and distributed systems, and now running RAGs and vector database POCs to explore GenAI integration into platforms, I believe we are overlooking perhaps the most critical failure case for agentic AI systems: the quality of the context consumed by AI agents.
What happens when an AI agent fetches an outdated customer record, an outdated policy document, or an embedding that has lost its meaning over time (data mutated, but still referring to obsolete data)? The decisions it makes based on this information are quietly wrong – not catastrophically wrong. Not wrong in any way that raises alarms. Just wrong in ways that quietly accumulate over time, eroding trust in your data governance stack without anyone really understanding why (skew in data or data corruption).
I call this “context poisoning,” and it is precisely at this juncture that metadata management, data quality, and AI governance intersect. It is the metadata governance challenge that every data engineering leader must address in 2026.
AI Governance Comprehensive
Gain the practical frameworks and tools to govern AI effectively.

What Is Context Poisoning?
In traditional security, we will be obsessed with having a bouncer at the front door to keep bad people out. But in the new agentic AI era, the threat is already inside. Context poisoning is about keeping the wrong information from getting in, even if it is coming from one of your own trusted sources.
Context poisoning is the situation in which the retrieval pipeline for the AI agent provides it with information that is technically correct but semantically incorrect. In this way, context poisoning is not like a traditional data breach that it is not happening outside the “correct” systems. The information is correct that it is in your data store. The information is incorrect in the sense that it is no longer “ground truth” or “true fact.”
There are three primary dimensions we need to consider:
- An agent receives an embedding that was previously generated on a document that has since been modified. The vector store is unaware that the underlying data has changed. I have seen this in action in a proof of concept we were doing on a RAG system. I had vector stored a set of policy documents, but in just three weeks, two of those policies were modified by our compliance team. The vector store was happily returning those old or stale versions of those documents. No one noticed until a test response conflicted with an actual FAQ.
- It creates a summary, and it gets stored as another document. It gets retrieved by another agent as an original source, also becomes unrecognizable over time from reality. This is something I have seen in multi-agent POCs for regulatory guidelines, where one agent summarizes, another one retrieves it instead of the original, and over time, it becomes unrecognizable from the source to the point (hallucination feedback loops) where it would not pass a compliance review. It is like the “telephone game,” but in AI, it is in your quarterly reports.
- When the retrieval is driven by semantic similarity, the agent will favor surfacing information that confirms the patterns it was trained on, not information that disputes them. This bias amplification poses a level of compliance risk that may be uniquely difficult to audit against in a regulated industry.
The common thread? None of these failures are visible at the point of retrieval. The agent does not know it is consuming bad context. The downstream consumer, whether a human analyst or another agent in a chain, has no idea that the decision was made in a bad context.
Why Traditional Data Security Falls Short
Enterprise-level data security has been based on a simple model: You define a perimeter, control access to that perimeter, encrypt data both at rest and in transit, and audit who is interacting with whom. This model has worked for us for decades. RBAC, encryption, and audit trails are the foundation of every compliance standard from SOC2 to PCI-DSS norms (I come from a fintech background and we are heavily scrutinized by this).
Agentic AI violates this model in a subtle way. Consider this analogy. Traditional data security is like a nightclub bouncer. He checks IDs at the door. But once you are inside, no one checks to make sure you are still who you said you were. Context poisoning is when the information inside the nightclub has changed identity since it was let in.
The question is no longer, “Who can access this data?” The question now becomes, “Is this data still true, and does the agent know the difference?”
For a chief data officer or data engineering leader, context poisoning is not just a retrieval error, it’s a critical risk in terms of compliance and liability. In heavily regulated industries, it’s precisely this “silent” nature of context poisoning errors that makes them a risk in terms of audits.
- Standard security layers such as RBAC, encryption, or firewalls do not detect the accuracy of content. If an AI agent is using out-of-date terms in transaction handling – despite high confidence in its answers – it’s a compliance violation that standard security cannot detect or report.
- Standard audits like SOC2 or PCI-DSS require data integrity. With context poisoning, data that is technically correct in a system but semantically incorrect in terms of its ability to drive decisions, especially in an automated system – makes it difficult to establish the “truth” of an AI’s answers in a look-back audit.
- This type of semantic similarity can cause a bias amplification effect, where the agent is more likely to favor information that confirms patterns rather than facts. This is a unique level of risk that is exceptionally difficult to audit against in a regulated industry.
- A metadata firebreak changes the paradigm from a “Black Box” type of AI model to one that has a paper trail for every piece of context. This allows you to demonstrate to the auditor that the decision was made based upon the most current and “golden record.”
Let’s take the example of a retrieval-augmented generation pipeline, which is the architecture pattern most enterprises are using to ground their LLM responses in their own data. A typical RAG flow looks like this:
- The query is made by a user or agent.
- The query is embedded in a vector form.
- The vector database returns the top-k chunks with the most semantic similarity.
- The chunks are injected into the context window of the LLM as “grounding” information.
- The LLM produces a response.
The following diagram illustrates the point where context poisoning can enter the typical RAG pipeline:
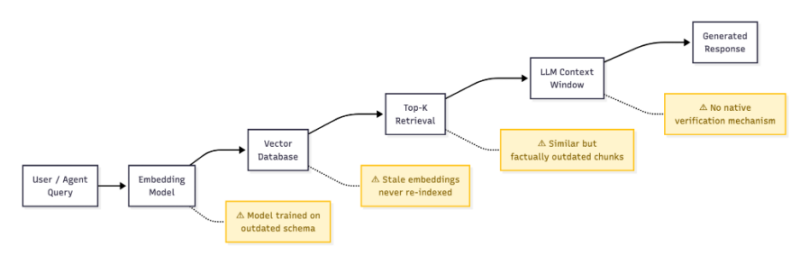
In the diagram shown above, all steps in an RAG pipeline, apart from the initial query, represent an attack surface for context poisoning.
Every action taken after the first block above represents a potential context poisoning surface. Was the embedding model trained on data that no longer represents your current schema? Does the vector database contain embeddings that are no longer accurate? Does the top-k retrieval contain chunks that are semantically similar but factually obsolete? And can the LLM even begin to validate any of these things?
Your security stack, IAM policies, encryption layers, and network firewalls have nothing to say/think about the accuracy of the content. That is a metadata governance problem – not a security problem.
The Metadata Firebreak: Applying Zero-Trust to Context
I always love a good analogy, so I thought I’d share one related to wildfire management. A firebreak is a space where a fire is prevented from spreading. It does not prevent a fire from starting, it prevents a fire from propagating. This is exactly what we need for context governance in agentic AI systems.
The concept is similar to one that is already well known by all data professionals: zero-trust architecture (ZTA). By default, no request is trusted, regardless of its source. Every request is validated based on identity, device, and context.
A metadata firebreak applies the same philosophy to AI context retrieval:
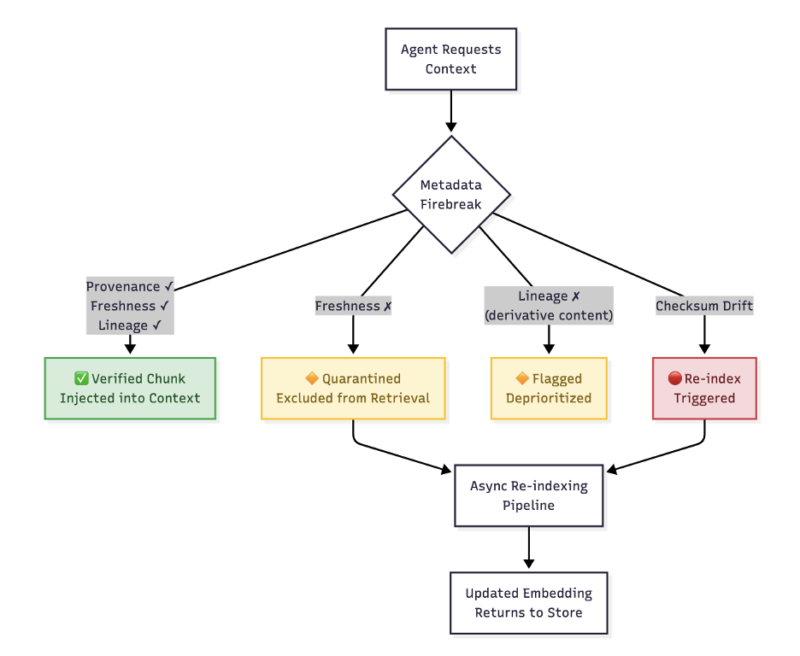
The metadata firebreak in the above diagram: a zero-trust verification layer that validates every retrieved chunk before it enters the context window of the agent.
The four pillars of the metadata firebreak:
- Never trust a retrieved chunk by default. Every piece of context injected into an agent’s window must be accompanied by verifiable metadata: source information, creation timestamp, last verified timestamp, and a confidence score.
- Verify freshness continuously. Develop a metadata service that tracks the timestamp of injection and compares it to the last-modified timestamp of the original document. Should this timestamp delta exceed a certain limit, quarantine this chunk – not delete it, but flag it as unverified and exclude it from any retrieval process until re-indexing.
- Enforce lineage tracking. Every chunk must have a lineage that tracks its original document, its generation by a certain embedding model, and if it has been used as input for another generated chunk. This will prevent any hallucination feedback loop.
- Apply semantic checksums. Similar to how checksums are used to check integrity of files, a “semantic checksum” can be developed – a new, mini version of the original document – and compared to the original vector. Should this score dip below a certain limit, a new vector should be generated.
This is not a hypothetical situation. I see a lot of places not prioritizing their metadata for their vectors, thinking they’ll get to it eventually. Eventually, never happens, and by the time they realize their context is expiring, it’s been expiring for weeks.
Vector Databases and the Semantic Truth Problem
Vector databases are the foundation of the modern RAG architecture, and they are incredibly good at what they do: finding similar content in a meaningful way. However, the catch here is that they were not designed to find truth, only similarity. This is a big difference, and it is one that teams don’t understand until it bites them.
You can think of a vector database as a library card catalog. They are incredibly good at telling you what books are about a certain topic. However, what they are not able to tell you is if the information in the books is still accurate. When we store a document in a vector database, we are taking the text in the document and converting it into a mathematical format that represents the meaning of the text at the time it was stored in the database. If the underlying document changes, the vector doesn’t adapt in response. If the underlying vector model is updated, the vector it produces is no longer compatible.
In the course of doing the POC for our vector database, I did a simple experiment. I built a vector database that had terms related to customer policies, and I updated the original documents by changing the key parameters. The vector database showed the old terms with high confidence levels. From the perspective of the model, it’s not a problem. From a compliance perspective, it’s a huge problem. This is where the concept of context poisoning happens.
This is a data quality issue, and it is the sort of issue that traditional data lineage is well-equipped to tackle, if only the concept of the AI retrieval layer is taken into account.
This is where metadata governance comes in:
| Challenge | Governance Response |
| Source document updated after indexing | Metadata freshness checks with automated re-indexing triggers |
| Embedding model version mismatch | Version tagging on all vectors; query-time model compatibility validation |
| Duplicate or near-duplicate chunks from different sources | Deduplication via lineage-aware metadata, preferring primary sources |
| Agent-generated content stored alongside human-authored content | Origin classification metadata (human vs. generated) with retrieval filtering |
The basic idea is that the vector itself is not the unit of trust; rather, the metadata envelope surrounding the vector is the unit of trust. If the metadata is not present, then the foundation of the decision layer of the AI is unverified.
Data Governance Bootcamp
Learn strategies for planning, designing, and sustaining successful data governance programs – October 6, 13 & 20, 2026.

The Saga Pattern for Context Governance
If you’ve ever initiated a refund for a faulty product and seen it propagate through your credit card statement, shipping label, and inventory system, well done, you’ve just lived through a saga in the wild! For those of us who have spent years working with distributed microservices, the saga pattern is a well-known technique for handling long-running business transactions that span service boundaries. In the original paper by Hector Garcia-Molina and Kenneth Salem, a saga was described as a series of local transactions where every step has a compensating action in case the transaction fails further down the line.
The saga pattern maps surprisingly well onto context governance. Suppose we have an agentic workflow:
- Agent A uses context information from the vector store.
- Agent B adds context information from a real-time API.
- Agent C uses context information for a decision.
If the context retrieved in #1 is later deemed stale – perhaps because a freshness check ran asynchronously and determined the source document has been updated – we need a mechanism to:
- Flag all downstream decisions that used that context.
- Compensate by re-running affected workflow steps with updated context.
- Audit which decisions were impacted and whether they need human review.
This diagram illustrates how the saga pattern applies to context governance:
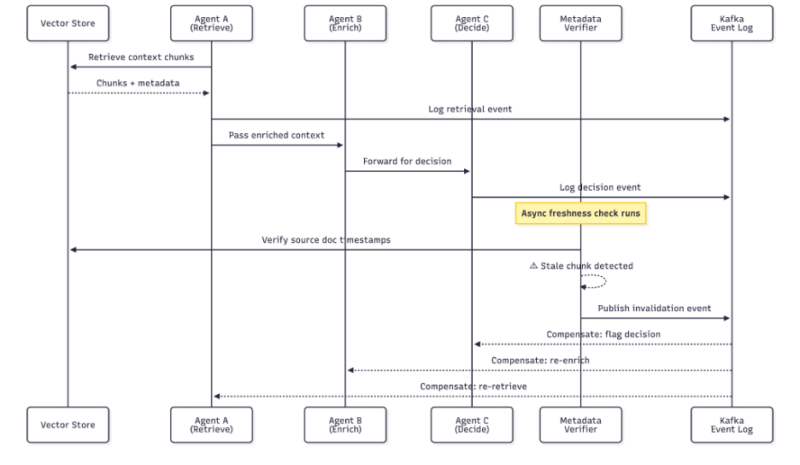
A metadata saga in action. When a freshness check detects stale context, compensating actions propagate downstream through the event log, flagging affected decisions for re-evaluation.
That is a metadata saga. That is, every time we retrieve, it is a local transaction, and there is associated metadata. However, when the metadata is no longer valid, compensating actions propagate down. That is when I got really enthusiastic about this. As you can see, we already have a mission critical enterprise platform. It is already built on top of Kafka-based event-driven microservices. We already have over 100 of them, and they handle millions of events. We already have an event backbone, we already have a topic infrastructure, and we already have the discipline around event sourcing. This is where we can add context retrieval events for our AI integration.
A Practical Framework: Building Your Metadata Firebreak
With regard to what I have seen work in different POCs/testings, as well as what I have seen fail, I will provide a framework to address context governance. I must say that, in our initial stages of developing our RAG POCs to address services integration, we had nothing in place. I think we were so focused on retrieval that governance was an afterthought. What I am about to discuss is what I wish we had developed from the beginning.
The following is a high-level overview of how all of these pieces fit together:
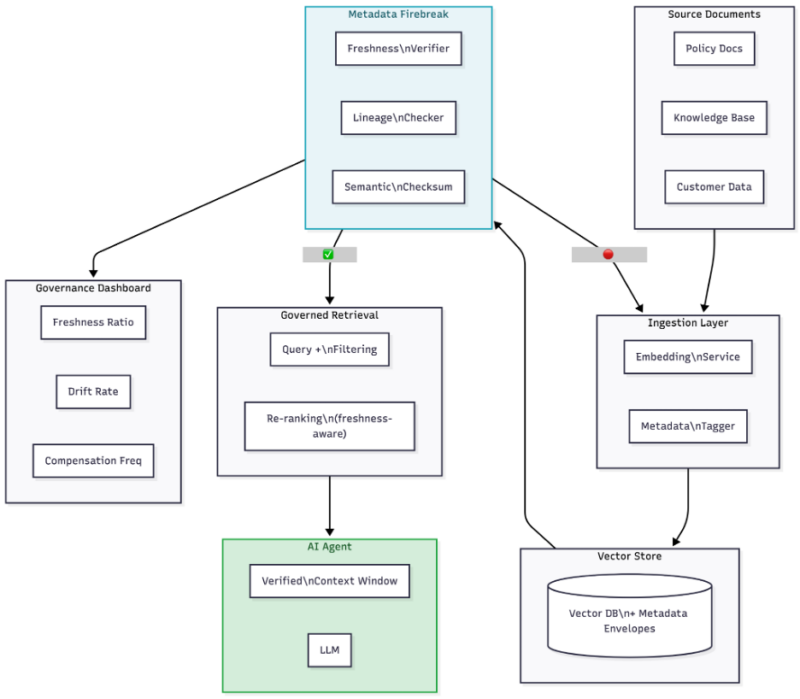
End-to-end Metadata Firebreak Architecture: This essentially sits between the vector store and the retrieval layer.
Step 1: Instrument Your Retrieval Layer
Add metadata to every retrieval event:
- Source document ID and version
- Embedding model version
- Embedding creation timestamp
- Retrieval confidence score (cosine similarity)
- Freshness status (verified/unverified/quarantined)
Step 2: Build a Metadata Verification Service
This service runs asynchronously and:
- Compares embedding timestamps with source document modification times
- Periodically performs semantic checksum validation on high-value document collections
- Publishes freshness invalidation events to a Kafka topic (or similar event bus)
Step 3: Implement Retrieval-Time Filtering
Modify your RAG retrieval logic to:
- Exclude quarantined chunks in top-k results
- Adjust unverified chunk scores (lower their rank score)
- Primary sources over agent-derived content
Step 4: Deploy Compensating Actions
Using a saga orchestrator:
- Track which agent decisions used which context chunks
- On chunk invalidation, trigger review for impacted decisions
- For high-stakes domains like healthcare or regulatory compliance, trigger human review
Step 5: Establishing Governance Dashboards
Build observability into the system:
- Context freshness ratio: the percentage of the retrieved chunks that are verified fresh
- Drift detection rate: the rate of semantic checksum failure
- Compensation frequency: the rate of re-evaluation of downstream decisions
Real-World Scenario: Context Poisoning in a Regulated Enterprise Environment
This is not a problem that has been encountered in a white paper, although it is similar to one we encountered in our POCs. We have been working to develop AI agents to assist in answering questions related to operational inquiries, request processing, and customer service requests. This is done through a knowledge base, which includes regulatory guidelines, product information, and customer information.
One of our RAG POCs for updated regulatory guidelines included updated rules for transaction processing. These updated guidelines were added to the source documents, as all source documents are. However, the vector store still included the previous guidelines. The AI agent is giving outdated terms for operational handling, although it is giving them at high confidence. It sounds very authoritative, and LLMs are very good at sounding very authoritative.
In a traditional system, this human would have received a training update and would be aware of checking for fresh data. However, this was not the case with the AI agent, as no such enforcement was carried out through the metadata layer. This was also discovered in POC testing, thankfully. But this experience was an eye-opener for the entire team to understand that without freshness checks, lineage, and quarantining old data, old context would propagate silently in any system. This is where we began this journey on metadata governance.
The metadata firebreak would have caught this in action: The freshness check would have seen that the regulatory doc was updated after the embedding was created and quarantined the old information, serving only the verified information or flagging the response for review.
In Summary
We’ve spent decades making sure that our data perimeters are secure against unwarranted access. This is important work that must continue. But now that AI agents are going to be treated like first-class citizens when it comes to access to enterprise data, we need to shift our data governance mindset from “who can access this data?” to “is this data still true?” and “does this agent know?”
Context poisoning is not a spectacular failure. It is the leak in the roof that you do not notice until the roof caves in. The metadata firebreak, built on zero trust principles, metadata verification, and implemented using patterns such as saga, is a concrete framework that data leaders can actually do something with to stop this erosion before it reaches critical decision points.
The perimeter has changed. Metadata is now the new perimeter. And here’s the good news: If you’ve been investing in metadata management and data quality disciplines, you’ve already built this foundation. Now’s the time to take it to the next step and add the AI layer.
Data Architecture Workshop
Learn how to design unified, future-ready data architectures that bring together operational, analytical, and AI data – December 1-2, 2026.


