The Data-Centric Revolution is a TDAN column published every quarter.
The “Strangler Fig Pattern”[1] has re-emerged. It hadn’t been seen in decades and many environmentalists feared it was endangered, if not completely extinct. But we’ve had several sightings just in the last two months [2] [3] [4]; one of our partners invoked it just two weeks ago, so the fig seems to have stepped back from the precipice. Katie Koster described her use of the pattern in Kill It With Fire [5], a very informative treatise on upgrading legacy systems.
The Strangler Fig Pattern
Martin Fowler came up with the Strangler Fig Pattern in the early 2000s. It was inspired by his observation of a fig tree in the rainforests outside of Brisbane, Australia.
The strangler fig starts its life cycle high in a “host” tree and then grows down to set roots and grows up to provide its own photosynthesis. It grows structural members around the host tree such that when it ultimately kills the host it doesn’t collapse. Over time it displaces the original host but retains its original structure.
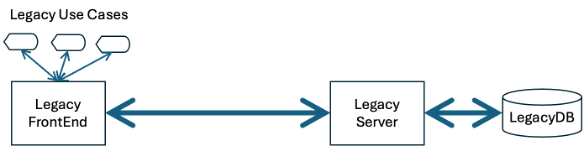
The enterprise architecture version of the strangler fig inserts an intermediary between a legacy UI and the legacy back end. We start our depiction with a front end on the left and a server side on the right.

The front end might be a single monolith (fat client style) or many independent use cases, but the idea is the same. The front end is reading and writing to the server.
The first move is to insert an intermediary between the two.

For this to be minimally invasive, the intermediary must satisfy the exact same APIs the original program calls. Same protocol, same signature, same behavior.
Then the architect begins introducing new technology.
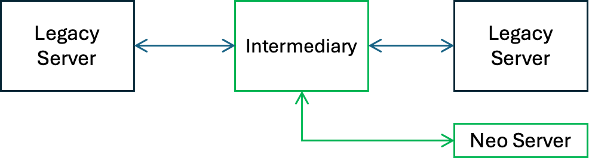
In this case we’re gradually trying to migrate off an obsolete server. Some percentage of the calls (maybe just for one use case) are redirected to the new technology version. Over time, more and more functionality shifts to the new platform until the old one can be gracefully retired.
Presumably you could do it the other way around and gradually swap out the front end. I have never done this. In principle it seems doable. In Kill It With Fire, Katie Koster reported using this successfully and I’m sure there are many others who have done so.
This approach is well-suited to cases where you want to keep the exact same functionality and merely change the technology. It would be hard to refactor the database, for instance, in the middle of this, because it must maintain all the same APIs and all the same behavior all the way through.
Data Architecture Bootcamp
Learn how to design modern data architectures that unify operational, analytical, and AI data – September 2026.

The Data-Centric Strangler Fig
We’ve been doing a variation of this for years without naming it. So now we have a name. Here’s how the Data-Centric Strangler Fig works.
We start with the same legacy front end and legacy back end, as above, but I’ve added a few items to the diagram make this part of the story easier to follow.
There are a few specific use cases on the left, and the database behind the server on the right. I’ve also made the pipes bolder to show how the flow would change over time.
The first step is to extract copies of the legacy data and put them in a knowledge graph (TS for “Triple Store”).
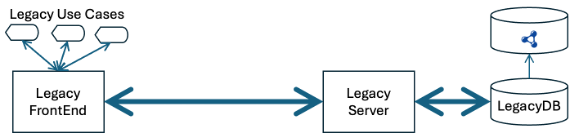
We also build a pipeline, the vertical line, to keep the knowledge graph up to date. As much as possible we try to avoid situations where we must push data back from the knowledge graph to legacy systems. Sometimes we end up needing to populate the databases downstream from the legacy database, but we try to minimize that as much as possible.
The next stage is to replace one or a few of the use cases with functional equivalents operating directly against the triple store. Note that these do not need to be API- or form-compatible. In almost every case, we have drastically reduced the complexity of the data model in the migration to the triple store, and we don’t want to suddenly reintroduce the complexity we just got rid of for the sake of being backward compatible with the legacy system.
Our observation is that the first few native use cases are either read-only (some form of visualization or dashboard) or they are use cases made possible by integration. If your task assignment systems and your labor costing systems have historically been distinct (which in most cases they are), then you might not have thought about building use cases that predicted revenue and margin based on those task assignments. With your data unified, this becomes a straightforward use case.
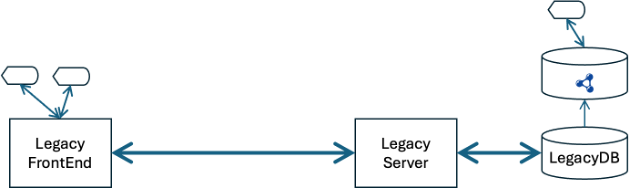
The first few use cases may not replace any use cases from the legacy system, but as the enterprise gains confidence with the new approach it begins experimenting with replacing use cases from the legacy system.
There is a bit of a trick in sequencing here. You want to document the data dependencies and implement them from the dependent to those that they depend on. If your CRM system places orders (some do), then you would want to migrate the order-taking use case before the customer setup use case because the orders depend on the customers; the customers do not depend on the orders.
If you do that you can just stop entering orders in the CRM system. The diagram suggests that the volume of traffic flowing through the legacy pipeline is beginning to decrease.
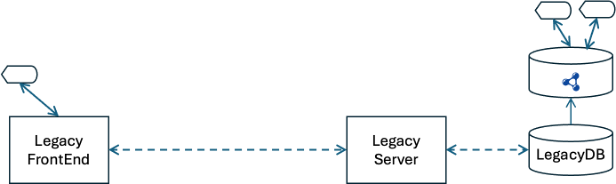
Shift some more use cases and eventually the flow becomes a trickle. This is a cartoon simplification; almost all applications have dozens of use cases, and most have hundreds or more. But the idea is the same: as you recreate the use cases in the graph-native environment, the traffic on the legacy system and therefore the pipeline that is populating the triple store diminish.
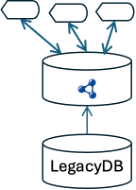
When the last use case is replicated in the graph, the legacy front end, server, and pipeline to the knowledge graph can all be decommissioned.
And the legacy database as well.
Complications
As suggested earlier, one issue is the need to sequence this to make the migration as gentle as possible. You can’t always get it to work completely. Sometimes you have to build some temporary bridges going back to the legacy system, but you should try to minimize this.
The bigger problem, which this approach shares with the original Strangler Fig, is the hidden business rules. These legacy systems (and by “legacy system” we often mean packaged applications, and even now some SaaS implementations are reaching legacy status) often come with millions of lines of code. The sponsors, stewards, and maintainers of this code are pretty convinced there are some “business rules” encoded in there somewhere.
There are. Far fewer than most people believe, but they are still there, and very hard to find because they are typically marbled throughout. It would be great if each business rule were encapsulated in its own small module, where it could be read, evaluated, and reproduced in the new environment if still needed. But what is more typical is one bit of code evaluates a few attributes and sets some status flag; then somewhere far distant this flag is used to change which procedure is applied. The procedure produces some other side effect, which is picked up even further downstream.
This is an area where LLMs are beginning to help out, and we expect approaches using them to eventually mature and provide very good coverage. While LLMs can detect what look like good candidate rules from the code, there are a lot of false positives. Many rules are no longer appropriate because of changes to the business or the configuration of the systems. Many things that look like “business rules” are fairly simplistic validation rules. Many others are rules to drive application processing (for instance, batch processing to create accumulators), which are implementation rather than business rules.
Our observation is that there are typically hundreds of legitimate business rules in most legacy systems, but they are quite well hidden, and the anxiety about uncovering and reproducing them is valid.
Advantages
That said, the Data-Centric Strangler Fig pattern has all of the advantages of the original Strangler Fig Pattern: a route to replacing a legacy system a bit at a time.
But we think it has several important advantages. The first is that it allows for an improvement in the data structures and the functions while the transition is in progress. The original Strangler Fig pretty much required that you keep the data structures and functionality constant through the transition process. As such, it was mostly useful for technology or platform upgrades.
The second is we didn’t touch the legacy code. Neither the client nor server, and did not insert and intermediary. The original Strangler Fig involved a pretty deep architectural intervention. You had to insert an intermediary and be able to direct traffic to the new or the old functionality. We haven’t done a traditional Strangler Fig, but it seems that there must be situations where the new functionality is implemented on a different database, which involves further data synchronization.
The Data-Centric Strangler Fig is much less architecturally invasive. The whole thing can be mediated by the equivalent of ETL scripts. You might opt for a streaming publishing architecture such as Kafka if there is a need to keep the two databases more closely aligned temporally.
Summary
Most big bang legacy modernization projects fail. There are just too many moving parts to be migrated all at one time. Practitioners have mostly concluded that the secret to legacy modernization is incrementalism. The original Strangler Fig Pattern is an approach to legacy modernization that may work in many situations.
The Data-Centric Strangler Fig is an alternative approach to incremental legacy modernization that we think is less architecturally invasive and has the added advantage of allowing an upgrade of the data structures and functionality while the transition is in progress.
[1] Original martinfowler.com/bliki/OriginalStranglerFigApplication.html
[2] I just looked this up and Martin Fowler had updated it in 2024. Something is going on. martinfowler.com/bliki/StranglerFigApplication.html
This Microsoft article on Strangler Fig is dated in 2025: learn.microsoft.com/en-us/azure/architecture/patterns/strangler-fig
[3] AWS from this year docs.aws.amazon.com/prescriptive-guidance/latest/cloud-design-patterns/strangler-fig.html
[4] drpicox.medium.com/the-strangler-fig-pattern-a8ea077e4480
Data Architecture Online
Join us on July 22 for a full day of practitioner-led sessions on modern data architecture.

