
Watching closely the evolution of metadata platforms (later rechristened as Data Governance platforms due to their focus), as somebody who has implemented and built Data Governance solutions on top of these platforms, I see a significant evolution in their architecture as well as the use cases they support. This evolution seems to closely mirror the evolution of data platforms.
Starting with a very simple value proposition of providing context to data, metadata today supports a whole gamut of use cases from data lineage to data observability.
The Good Old Days
Remember the days when metadata platforms supported only connectors to fetch the technical metadata from relational databases? These load jobs were run periodically to push the technical metadata into the metadata platform. The business metadata like the terms, rules, policies, and KPIs were uploaded through spreadsheets. The so-called “Data Governance team” then used to painstakingly link this business metadata to the technical metadata creating a nice searchable repository of data assets with the business context. This reminds me of the days of simple batch processing of data, run daily or even weekly, to generate canned reports for the business.
As business users and analysts saw value in this repository that provided the ability to find data assets with their business context, they asked for more.
Metadata Pipelines
Users wanted to understand the source or provenance of the data assets, be it for choosing the right datasets for analysis or understand how trustworthy that source was. This led to the need for generating data lineage diagrams, which means fetching metadata from all tools in the typical data analytics architecture and stitching them together – starting from the operational sources that went beyond simple relational databases, the data pipeline/integration tools, the data warehouse/analytic stores to the dashboarding tools.
Now, this was not an easy process like what we had for relational databases. Very few tools exposed their metadata in a structured and documented manner. Either we had to dig through the complex models in the tool repositories to figure out how they structured their metadata (like that of Informatica Powercenter ETL) or parse large XML files (for the likes of Tableau and SAP HANA). There was always a risk of these structures changing, as it was not a contract like the REST APIs. Again, it reminds me of the days when even data extraction from some of the legacy sources was challenging as we built the ETL/data pipelines.
Modeling a Metadata Warehouse or Metadata Mart
With metadata now flowing in from several tools, the metadata platform needed a repository that could have a flexible and extensible metadata model or metamodel, which could support various entity types, attributes, and relationships between these entity types.
Metadata of an ETL tool would have entity types to support connection and transformation components, whereas a metamodel for a dashboarding tool like Tableau would need to support entity types such reports, attributes, and measures. To differentiate between Tableau and Power BI, we needed flexibility to name the Tableau report entity type as Tableau Workbook and Tableau Worksheets, whereas the Power BI one would have Power BI Report and Report. Does that sound like how enterprises once spent lots of effort in defining the data model for data warehouses and data marts during the “schema on write” days, picking up industry models such as FSLDM from players like Teradata and IBM?
Metadata Metrics and Dashboards
Finally, we needed the consumption layer for the business users to search and understand the integrated metadata like the nice dashboards and charts on top of the data warehouses and marts. A search interface was the default for many of these metadata/Data Governance platforms. However, generating more valuable metrics and insights that could help drive action was difficult – for example, knowing redundant/duplicate columns sitting across tables, data assets that had poor quality scores (loaded from external tools), and so on. The other issue was that it needed metric users to log into these metadata platforms to view the metrics/insights. This is typically a big no in many organizations, as it means more licenses to be bought or the user has to be trained to navigate this metadata platform.
New Use Cases and Challenges
With the drive to derive maximum value from data that is increasing in volume, velocity, and variety (popularly known as the 3Vs), the so-called modern data stack or data architectures have evolved to become more open, flexible, and actionable (helping convert insights to actions) apart from other technical characteristics to support the 3Vs.
Metadata platforms are inevitably catching up too and getting ready to support this modern data stack. See this very informative blog post from Linkedin’s Data Hub team on new use cases driven by metadata and the evolution of the metadata platform architectures to support these.
The 3Vs seem to be now relevant to metadata as well. To support some of the use cases on compliance and access control, we need to support what is called the “operational metadata.” Thus, we need newer (v)ariety of metadata sources and types such as query logs from several tools to understand usage metadata and system logs to understand resource consumption and performance. Moving into this realm of operational metadata naturally means increased (v)elocity and (v)olume too.
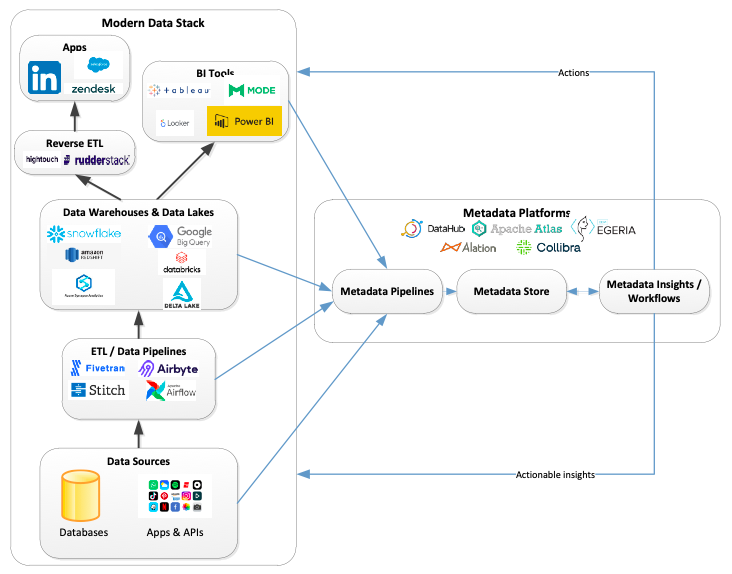
The Modern Metadata Stack
To support these new use cases and challenges, here is what a modern metadata platform needs:
- Metadata sources: Connectors to several types of metadata sources – in fact anything and everything that forms part of the data stack – are essential. This could be varied data sources, data pipeline tools, data catalog tools, data lakes/warehouses, Data Quality tools, analytic tools, query engines, identity management tools, and so on. Without fetching and stitching metadata from all these sources, we can never get to any meaningful insights on lineage, Data Quality impact, privacy, etc. With more and more data platforms exposing their metadata through well-defined contracts or APIs, this will get easier. Of course, we will hit challenges when the tools are closed, or the core metadata is to be derived using code parsers (e.g., transformations built using SQLs or Python code).
- Metadata pipelines: Next is the metadata pipeline to consolidate this metadata into the metadata platform. Referring to the three generations of platforms discussed in the LinkedIn blog post above, support for both pull-based (where pipelines are periodically scheduled to pull the metadata from sources) to push-based (where the pipeline listen to the metadata change events and act) are key. Pipelines do need to support transformations from the source metadata structures to the metamodel structures of the metadata platform.
- Metadata store: The metadata platform or the metadata integrated store needs to now accommodate the variety of metadata types keeping the flexibility to extend. As mentioned in the features of the third-generation platforms, the ability for different groups in the enterprise to bring in their perspective and add attributes/characteristics to the metadata elements is key. That is where support for collaboration and crowdsourcing aspects come in, allowing for these metadata elements to be enriched by the users.
- Process augmentation/automation support: Here is another interesting angle to this metadata enrichment process – the concept of “augmentation” or “automation” using the ML/AI processes. It is very helpful in removing the pain from manual tasks such as linking business metadata to technical metadata, auto-tagging sensitive data elements by profiling the underlying data, etc.
- Consumption layer: Now, we need the consumption layer to glean insights from these integrated metadata store to drive actions – could be by humans or integrated systems.
- Enables search – A repository linking business, technical, and operational metadata is a goldmine for any user be it business or technical to find, understand, and collaborate on all their organizations data assets
- Actionable metrics and dashboards – Helps view Data Governance-related metrics and improvements, audit dashboards, data privacy and risk dashboards, data lineage, and so on
- Trigger action in external platforms – Automated workflows (through embedded workflow engines) can be triggered based on the integrated metadata. Like applying access control to sensitive elements in external platforms, Data Quality scores can help drive data curation requests in source platforms, create and apply policies, and so on.
- Reverse metadata ETL: Lastly, one of the newer entrants into the modern data stack is “reverse ETL,” where insights from data warehouses and data lakes are pushed back to the source operational systems to drive action. A reverse ETL action of pushing the metadata insights to the source platforms adds lot of value – for example, sensitive tags of data assets/Data Quality scores of data sets can go to the BI tools that help the analyst decide its usage.
Given that metadata is nothing but a simple context wrapper on top of “data,” do you see this evolution of metadata platforms tracing the same path of “data” evolution an interesting pattern or a no-brainer?



