Click to learn more about author Steve Miller.
I’ve been blogging on Business Intelligence/Analytics/Data Science for 12 years. And I’ve been recruiting analytics candidates from top colleges for my consulting firms for even longer. Those who read my blogs know I’m pretty opinionated about what I look for in new grads, preferring students committed to data, analytics, and computation over pure math and CS types. In the past 10 years especially, I’ve had the most success hiring business, statistics, econ, physics, and industrial engineering majors with both strong stats and programming skills and a passion for research with data. Indeed, after college recruiting a few years ago, I came up with my own certificate proposal.
The last 10-15 years have witnessed the emergence of first Masters in Analytics and then Masters in Data Science curricula from top schools across the country. Some of the programs are supported by business, some by engineering, some by math and computer science, some by information science, and now some by the social sciences. More and more are entirely online. My current favorites are the Masters of Science in Analytics from the McCormick School of Engineering at Northwestern University, the Masters in Computation Social Science at the University of Chicago, and the Online Master of Information and Data Science (MIDS) from the School of Information at the University of California, Berkeley. Yes, I have expensive tastes.
The Masters in DS programs span just 1-2 years and must make trade-offs in curriculum choices balancing business, stats, Machine Learning, and computation. Many early programs were heavy in business/stats and light on computation, though industry feedback led to a re-distribution of emphasis. Still, focus choices must be made.
Never one to leave education to the academics, I’ve offered my own curricula several times over the years, first with a proposed M.S. in Applied Statistics curriculum in 2011, then an M.S. in Analytics variant in 2013. My latest M.S. in Data Science curriculum is detailed below. It’s actually quite similar to the others, but reflects the evolution to more of a computation and Machine Learning emphasis.
The new curriculum spans 3 semesters and attends at least somewhat to business, statistics, ML, and computation/programming needs. By semester, the courses are as follows:
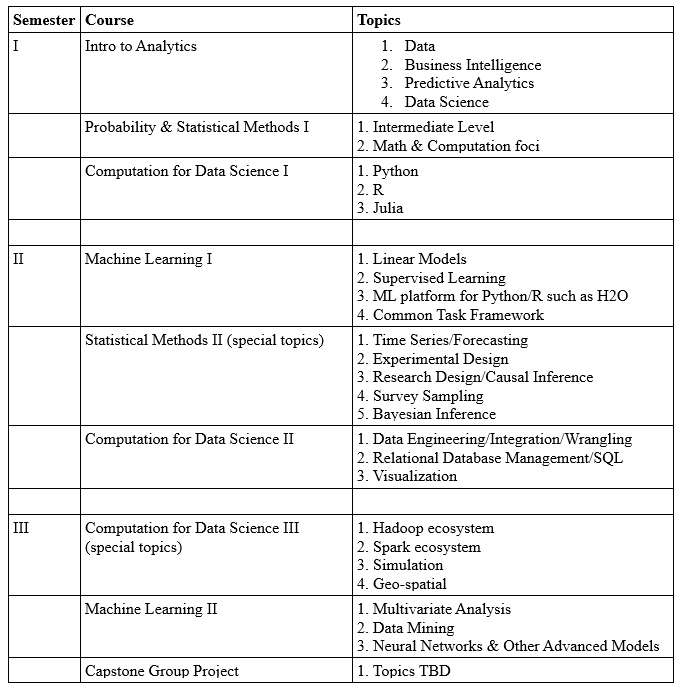
Today’s Analytics curricula invest more in computation than earlier generations. A full one third of my classes revolve on programming skills central to DS. Python, R, and SQL are lingua francas of today’s Data Science, while Hadoop and Spark are the go-to platforms for Big Data Analytics. Surf on just about any analytics job board and you’ll see these skills required time and again.
I reject the thinking of some professionals that statistics is now secondary to Machine Learning in today’s Data Science, agreeing with Stanford statistician Brad Efron that “If we abandon statistical inference, we’re doomed to reinvent it.” Probability and Statistical Methods I is the foundation course for this curriculum. And the special topic candidates for my Statistical Methods II class are each critical tools in the data scientist’s chest. I’ve done more forecasting work over the years than I have any other modeling method. And the observational data of industry presents challenges for demonstrating cause and effect that must be addressed methodically. More, how many online “surveys” are released today with inadequate knowledge of how – or if – the samples represent the underlying population? Finally, advances in computation have fundamentally promoted the emergence of Bayesian methods that update the probability of an hypothesis as more evidence becomes available. Makes sense.
Machine Learning I covers statistical learning at the level of An Introduction to Statistical Learning with Applications in R. Important is the promotion of the Common Task Framework for evaluating model performance, and consideration of a high throughput, multi-language modeling platform such as H2O. ML 2 covers evolving advanced models.
So what type of job will my new grad be qualified for? It depends on her work background before the course of study. If she’s an experienced data analyst with strong computation skills, she may well be ready for modeling challenges from the get-go. If, on the other hand, she enters grad school immediately after undergrad, she’ll likely do an “apprenticeship” with database/data programming/visualization for a period of time before being entrusted with heavy modeling. Regardless, she shouldn’t expect to be leading a convolutional neural network modeling effort as a rookie.
I believe the prediction of the imminent demise and automation of Data Science is premature. While the field is no doubt becoming more automated, I have no reservations recommending the discipline to young college grads for the near to mid future. I just hope the new DS’s enjoy their work as much as I have.




