Click to learn more about video blogger Thomas Frisendal.
Since the mid-seventies many SQL-databases have been modeled using the concept of surrogate keys:
- Non-information bearing primary keys
- Used for join purposes (inter-table relationships)
- System generated (integer) values
- Not to be shown to end-users
The advantage of using surrogate keys is guaranteed persistence, even across changes in business keys. Here is a snip showing what surrogate keys may look like:
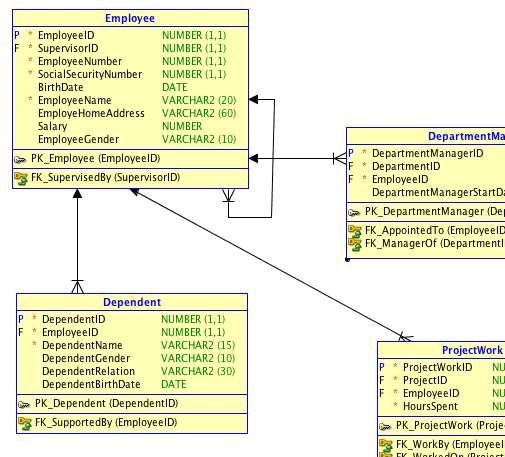
As you can see from the homemade example above, surrogate keys (ID fields) are not only for use in star schemas, but they are indeed found in many ERP-class data models. The practice emerged in 1976: P A V Hall, J Owlett, S J P Todd, “Relations and Entities”, Modelling in Data Base Management Systems (ed GM Nijssen), North Holland 1976. It became part of best practise in data modeling over the 80es. Today people realize that surrogate keys actually ease migration to NoSQL data models.
The surrogate key concept is a deviation from Dr. Ted Codd’s original concept of the relational model having primary keys, which would be (concatenated) business keys. However, surrogate keys proved to be more elegant because of their long-term persistence and the complexity of doing joins involving concatenated keys of different data types. Actually, surrogate keys were useful in making robust data structures around SQL’s primary key / foreign key constructs. But this a rather theoretical discussion, which does not need to be repeated, if you ask me.
But there is another interesting observation that is worth a good, more pragmatic, discussion today. The circumstance is the fast-growing acceptance of graph database technologies.
Dr. Codd spent a lot of effort arguing against using “links”, such as they were implemented in the dominating DBMS’s of the time (the so-called network databases be it CODASYL DBTG or IBM’s hybrid hierarchical / network DBMS’s such as IMS). And he was right in the critique of using pointers, which were too close to the physical data structures (page numbers and line indexes, in the case of IDMS and several other DBMS’s). Many a DB-person, including myself, spent several nights fixing broken pointer chains after power outages or disk drive failures.
Are pointers inherently bad?

Photo Credit: Wikipedia Commons
No, the pointer is such a powerful structure to us humans and closely tied to the way we perceive and represent the physical world surrounding us. That is why graph data models are so intuitive that whenever we sketch a data structure on a whiteboard it is actually some rounded circles being connected by arrows, right? And lifting that off the whiteboard and into a graph data model is very easy.
The Property Graph Data Model represented by Neo4J and several other vendors is growing very fast in popularity. Here is a data model in my preferred style of graph data modeling:
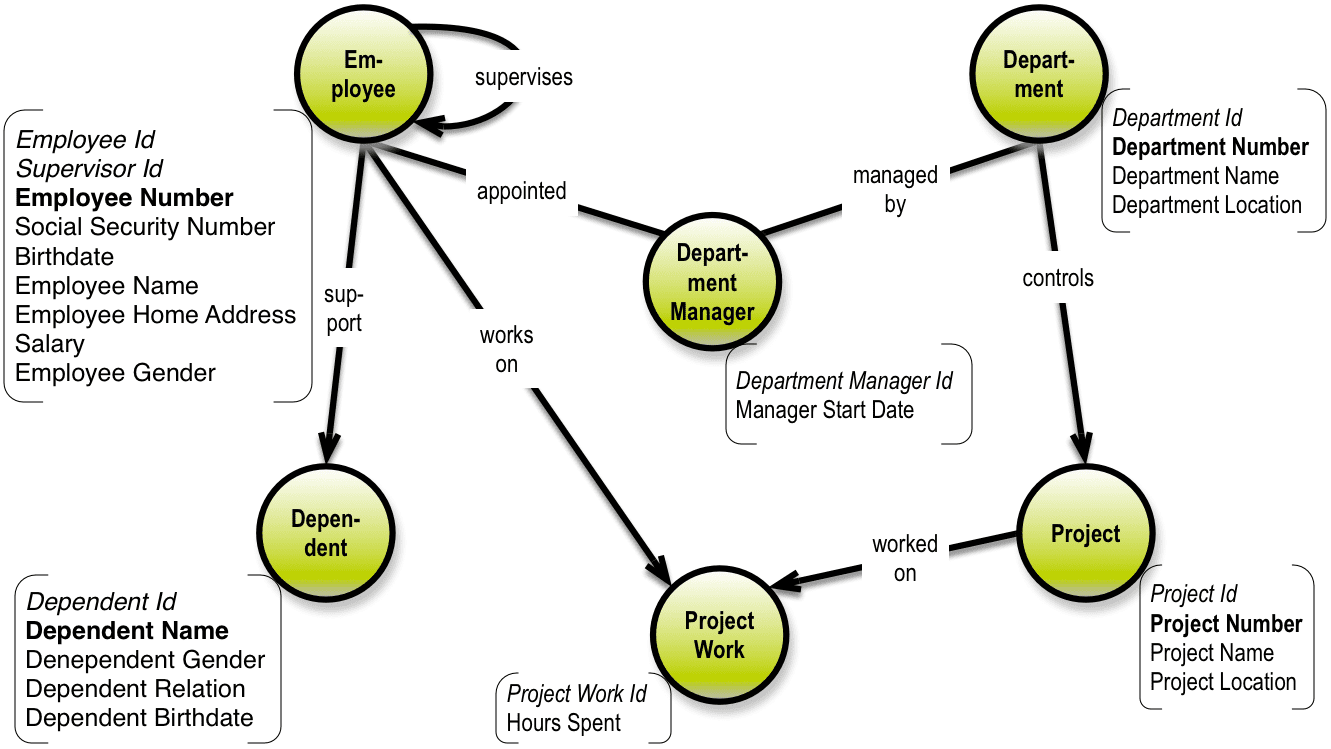
As you can see the nodes represent business objects, which in a normalized SQL model would have been tables. The relationships are explicitly named, which is not really the case in SQL. The relationships are constraints of the type foreign key. Foreign keys are sort of backwards compared to the directed graph model, where edges are forward pointing relations(hips).
The attributes are attached to the nodes as properties, and these are secondary citizens, because they do not contribute to the structure, only to the content. In the trivial cases SQL-based data models based on surrogate keys can be almost mechanically converted to a property graph model. (Given that the data model is reasonably normalized). There is much good reading about this on the internet.
The more mechanical process of moving the data is, for example, described in this blogpost on the Neo4J site that the surrogate keys move over and become indexed entries to the nodes. Another thing to note is there are no null’s in graph databases. Things are simply not there, if they aren’t.
Everything we need to know about the structure and meaning of an Employee is available in this part of the property graph:
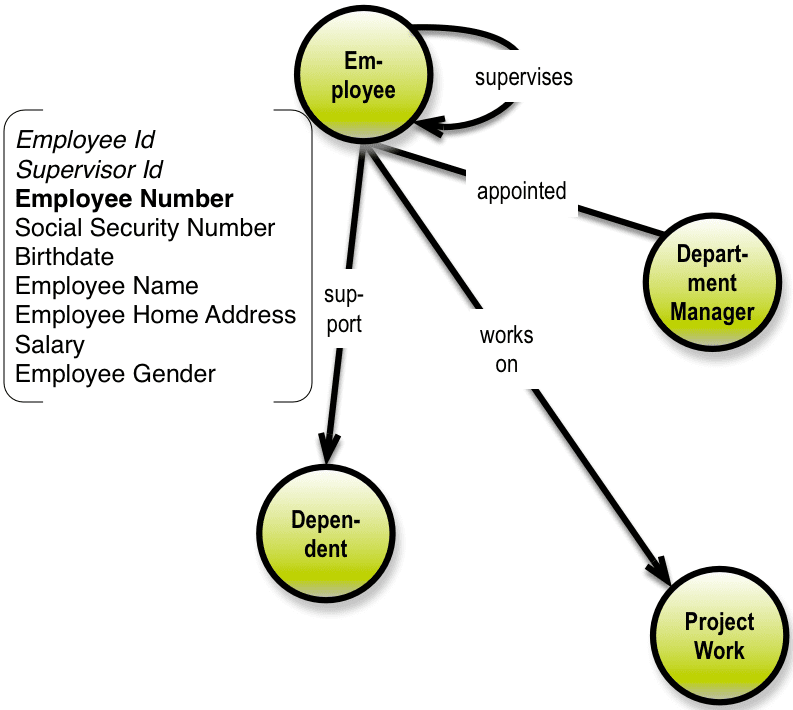
Note that in the equivalent SQL representation, the relationships would be represented by way of foreign key constraints on the three related tables. In the graph representation, they are simply relationships with a name.
On the down side: The real world is a bit more complex than simple relationships. Think about all the efforts that have been spent on cramming network structures into SQL tables. Often assuming that they are mostly hierarchical (which they frequently are not) – trying to avoid the nitty-gritty modeling and programming tricks necessary for dealing with networks (directed graphs) in SQL.
Here is an example of the dreaded SQL Common Table Expressions typically used for dealing with trees:

The example above is from IBM DB2 documentation . See also Joe Celko’s authoritative book Trees and Hierarchies in SQL for Smarties, Elsevier 2004.
Many legacy SQL-based data models using surrogate keys can now be seen as predecessors to property graph data models. And migrating them to graph database technology will make them a whole lot easier to deal with. First of all, the peculiar “reverse semantics” of relational (like “foreign keys”) now come in the shape of intuitive directed graphs; having named and more powerful relationships.
Add to that that graph algorithms deal elegantly with the traversal challenges that recursive SQL is struggling with for navigating a real network of data. Take asset management as an example: Portfolios, securities, clients, accounts, currencies, countries derivatives and other contracts, counterparties, brokers, corporate actions etc. etc. is a really complex mesh of interconnected business objects, which can be browsed easily and effectively using graph technology. Check Neo4J’s Cypher language and Apache Tinkerpop’s Gremlin ditto as well as graph browsers like Linkurious, Keylines and Quid for examples of graph browsing technologies.
If graph technology is not on your list of target platforms, other NoSQL technologies such as key/value or long row designs can be implemented with the same level of ease as graph. The surrogate keys may survive as the keys in the physical data model (possibly used for partitioning / sharding).
Graph theory is, like SQL, a data language based on mathematics. Key/value, long rows etc. are not quite that, but rather performance oriented physical models built for ultra-high performance using sharding etc. Neo4J is proposing OpenCypher as a new, standard data language for graph models. Looker is proposing their own LookML as a data language for other NoSQL contexts.
Back to graphs: As you can see from the property graph example above, the normalized data model is preserved in the property graph model and it is consequently “embedded” from the physical level up to the business level, where consistent structure and meaning of context is of utmost importance.
Finally: allow me an “out of the closet” analogy: If you are using surrogate keys you may just as well admit that you are pointing at things; go all the way to full graph data modeling!



