Click to learn more about author Pete Aven.
Data Hubs are the new way to manage data, and there’s a lot of confusion as to where exactly a Data Hub “fits” in an organization’s existing architecture. People generally want to know what a Data Hub will look like in action within their technology landscape for their requirements.
Data Hubs can be varied in their fulfillment, so the term “hub” can mean different things to different people depending on perspectives and preconceived notions. There is also a lot of misunderstanding because the technology world is overwhelmed with a glut of information, much of it high-quality and trustworthy, yet often conflicting, and some of it misleading. So let’s bring some clarity to the cacophony.
First, what is a pattern?
Technology patterns are discovered when looking across a number of successful implementations for common best practices. When a collection of best practices can be coalesced into an implementable solution that can be used repeatedly, within a given context that is distinct from other previously implemented solutions, it’s a pattern worthy of repeating for the prescribed scenario. The words “pattern” and “architecture” are often bandied about in technology conversations, but data hub patterns occur and are visible in distinct scenarios.
Enterprise Integration Patterns
There are two main patterns that occur naturally for integrating data in a data hub.
- The Data Integration Hub
- The Metadata Catalog
In the Data Integration Hub, often referred to as a Data Hub, data is taken from disparate sources to create a unified view of data. When you hear “customer 360,” or a 360-degree view of some entity, people are often referring to a Data Integration Hub.
Data silos exist for good reasons, some functional, technical, or having to do with security, geolocation, or other factors. But under every application, there is unique and complex data storage specific to that application. When used with the application it is intended for, that data source works great. But when entities require information from across silos to make business or mission decisions, they need to take parts of data from each system and stitch them together in a Data Hub to provide required answers within a unified context.
Sources of data in this scenario are often relational systems such as Oracle, SQL Server, and DB2, but can and do often include data from file systems,; data lakes; SharePoint; Office documents (people run their businesses on Excel); messages; documents in XML, JSON or plain text format; feeds from internal and external systems; graph data; geospatial data; social media; images; metadata – you name it.
With Data Hubs:
- Data is NOT entirely copied from all source systems to the hub. The only data copied is what is needed to provide the business or mission an answer.
- The systems of record do not necessarily go away. They often stay the systems of record. Their data alone isn’t complete enough for the view required by the business/mission.
- Data is kept in synch as required by pushing data from source to hub.
- Any modifications of data in the hub are captured in the hub so curated, uncurated, and original source data, along with provenance and lineage, are available for query and audit.
- Data isn’t necessarily pushed back to the source system from the hub. Often, the hub is an aggregator for the unified context. The data movement is from source to hub to downstream consumers of the unified view.
- Data in the hub may be transient. Sometimes, the downstream consumer of data is a traditional data warehouse. A Data Hub can be used as the rapid aggregator of data to cleanse it into a conformed and standardized shape quicker than traditional ETL.
In the Metadata Catalog, sometimes referred to as theLogical Data Warehouse, the data about the data is aggregated in the hub. It provides a way for people to query the hub and know where to find the data they’re looking for, which source system it resides in, and/or who they have to track down to ask permission to get what they need. Metadata catalogs are common in large media and publishing organizations that have a tremendous amount of digital assets. Storing metadata about images and videos along with info about titles, scripts, screenplays, books, actors, authors, publishers, licensing info and more allows those seeking information on a particular subject to find all related assets and know where sought information can be found. In the public sector, where there are thousands of silos deployed across the armed forces, for instance, metadata catalogs enable information sharing, reuse, and collaboration across distinct organization entities.
In reality, every Data Hub is a little of both and the integrated data falls along a spectrum of source data to source metadata. Data Hubs tend to have a particular focus in their implementation. Under these two major patterns, more granular distinctions can be made.
When the Data Hub is a knowledge graph, the same rules for data and metadata still apply.
Infrastructure Design (or Architecture) Patterns
Data Hubs can simplify infrastructure design. There are more products labeling themselves “Data Hub.” The pictures they provide for what their solution looks like are often very similar.
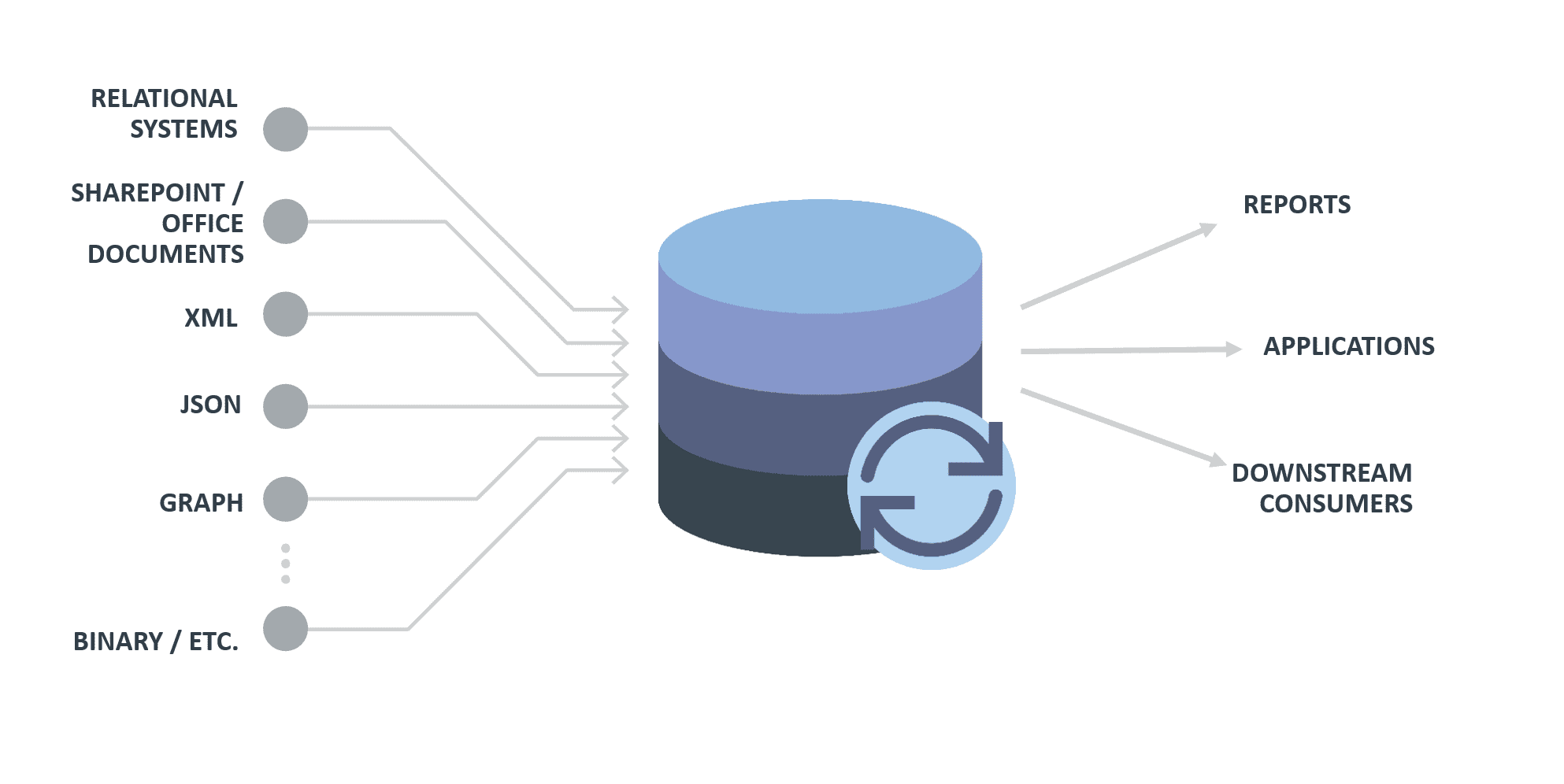
Data Hub in single platform
Image Source: MarkLogic
Many sources enter on the left, magic happens in the middle, and dollar signs and success fly out the right in the form of “insights.” But let’s take a closer look and double-click on the actual hub in the picture presented.
A Data Hub can be provided in a single binary. With composable features for supporting multiple data models and formats within a unified supporting index, the work effort can focus on working with the data and not in implementing the solution infrastructure. This type of hub drops right into the existing architecture and goes to work. Sizing and scalability are consistent as the features are provided in a single platform to ingest, curate, and deliver data.
There are other hubs that require disparate components to be assembled to create the actual hub. They are not integrated and don’t have composable features available at the start. Effort is required to plumb the entire data hub solution together before one can work with the data. Multiple components will be required if someone needs to work with relational data, document data, and graph data, and provide enterprise search in addition to query, along with unified security and monitoring, curation and mastering capabilities and more.
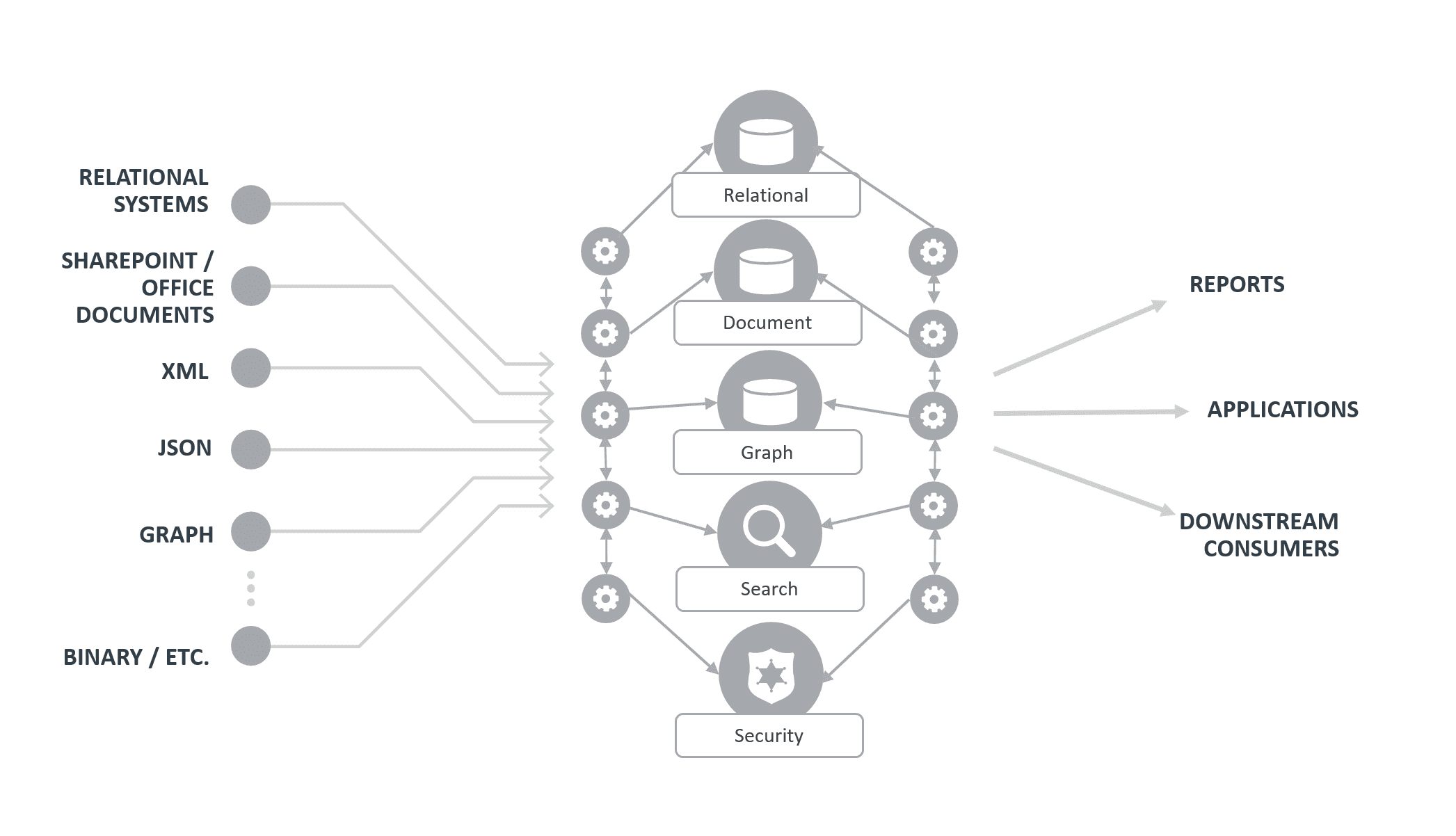
Data Hub created from many platforms and applications stitched together
Image Source: MarkLogic
This brings additional complexity to the architecture at unpredictable cost. Different databases and search engines require different indexing and storage mechanisms. Different databases require different query languages. Aggregating results of queries for different languages into a unified result set puts the solution in application logic, not in the hub, thus creating another silo of information. Then there are the different security mechanisms, etc. Assembling a Data Hub from parts can be challenging and expensive.
Data integration and data prep applications, though they have fancy interfaces that non-developers can use, can also unfortunately create more data silos if not implemented properly. The properness has to manifest in the code that plumbs the applications together. The cost of writing code to plumb any components together and provide the right tooling for interacting with the hub is a sunk cost that then has to be maintained.
Data Architecture Patterns
Here we find the patterns for data modeling, entity definitions, pipeline processing configurations, flows, etc., it is important to identify and articulate them separately as a focus area. There are entire books written on the subjects of Relational, Document, and Graph data modeling, and more to come as disparate data is brought together to solve new problems and provide new opportunities for data and information products within Data Hubs.




