Click to learn more about author Jay Sitapara.
Microservices architecture transforms the software development process, practices, and results in many ways. Microservices were born because monolithic architecture proved to be outdated to meet the demand of modern applications. While microservices solve a lot of issues, the architecture brings a new set of problems with it too. One of them is maintaining data consistency across microservices.
In a monolithic architecture, maintaining data consistency is comparatively easy since the application is built over a single database. This is not the case with microservices architecture. Depending upon your application structure and the number of microservices, you will be required to select the data management patterns. This means there could be more than one database.
With multiple databases, we risk data inconsistency. When there are more than one data storage solutions, consistency is not solved automatically. This needs to be critically taken into consideration while designing the architecture. Let’s have a look at some concrete data management patterns that can help you build data-consistent applications based on a microservices architecture.
1. Database-per-Service Pattern

You should use a database-per-service pattern when you want to scale and test specific microservices. It gives you the flexibility of choosing a database while working with specific services. However, the databases of each microservice will be separated from each other. So, there is no established communication between two microservices or their database.
To establish this communication, this pattern uses APIs to exchange data. However, this data exchange becomes complex for the larger applications, when there are numerous microservices and their respective databases. In order to perform an action, an API has to intervene, fetching the data and interacting with different databases. This becomes hectic for the successful execution of the business logic.
Because of this, this pattern can be challenging to implement when a large number of microservices or bounded contexts are involved, which can be the case in most scalable applications. Applications with a limited scope can always go for database per-service-implementation.
2. Saga Pattern
A saga pattern is mainly divided into two parts:
- Choreography based saga, where the exchange of communication is done by exchanging the events.
- Orchestration based saga, where there is a centralized control for invoking the saga participants using the requests or responses.
For the applications where multiple transactions are possible, the Saga Pattern acts as a predominant microservices Data Management pattern. It is a series of local transactions where each transaction publishes an event stating the status of the queries being triggered. The other services are dependent on the previous services’ status, and hence, for the transactions with previously failing status, the saga will automatically undo the further transactions.
When a customer places an order in an eCommerce store, the two services called customer service and order service will be working. When a customer service sends the order, the order will be in the pending state. The saga contacts the eCommerce store through the order service and will manage the placing of events. Once the order service gets the confirmation about the order, it sends the reply.
Depending on the reply, the saga will approve or reject the order. The final status of the order is presented to the customer stating that the order will be delivered or having the buyer proceed to the payment method. In cases where the order is not accepted by the eCommerce store, it sends an apology message or shows the out-of-stock indicator.
3. Shared Database Pattern
Shared database is the easiest option to pick when you can’t deal anymore with complex data patterns like database-per-service. Shared database, as the name sounds, is shared commonly by the microservices for their respective domains of service.
To keep up the consistency with the database and streamlining the process, the transactions are influenced by the ACID.
But again, when you are using a microservices architecture, this approach diminishes the meaning of using it since the pattern involves coordination between teams for changing the schema to tables.
Software architects need to be more conscious of executing this data management pattern since it creates the run-time conflict because of the overloading of multiple services on the same database.
4. API Composition Pattern
This Data Management pattern involves the join in-memory operation and disturbs the other microservices in order to perform the tasks. However, for some queries, its in-memory joins of big datasets are inefficient.
In some ways, it is good to use an API composer and have a database fetched from the services that already have used already used it. But again, for larger applications the complexity of using this pattern increases and it doesn’t make a difference in using microservices since it uses a join operation.
5. CQRS Pattern
This segregation and responsibility pattern follows the modern approach of time optimization by saving the already used data. It doesn’t invoke the actual database every time a query is fired.
The replica of the database will still be in view mode and cannot be accessed for any editing purpose. CQRS will have a separation of layers. For example, the command layer and query layer will be separated from each other. The command layer is used for inserting the data and the query layer for fetching the data from the data store.
The advantage of using the CQRS pattern is that it logs the events in the database in parallel with the messaging queue whenever the customer/end-user updates the data. Unlike conventional approaches it opposes the idea of doing read and write operations with a single view. Traditional approaches often do the read and write operations with a single view and engender more complexity. Using the CQRS pattern breaks the traditional way of program executions and speeds up the workflow.
6. Event Sourcing Pattern
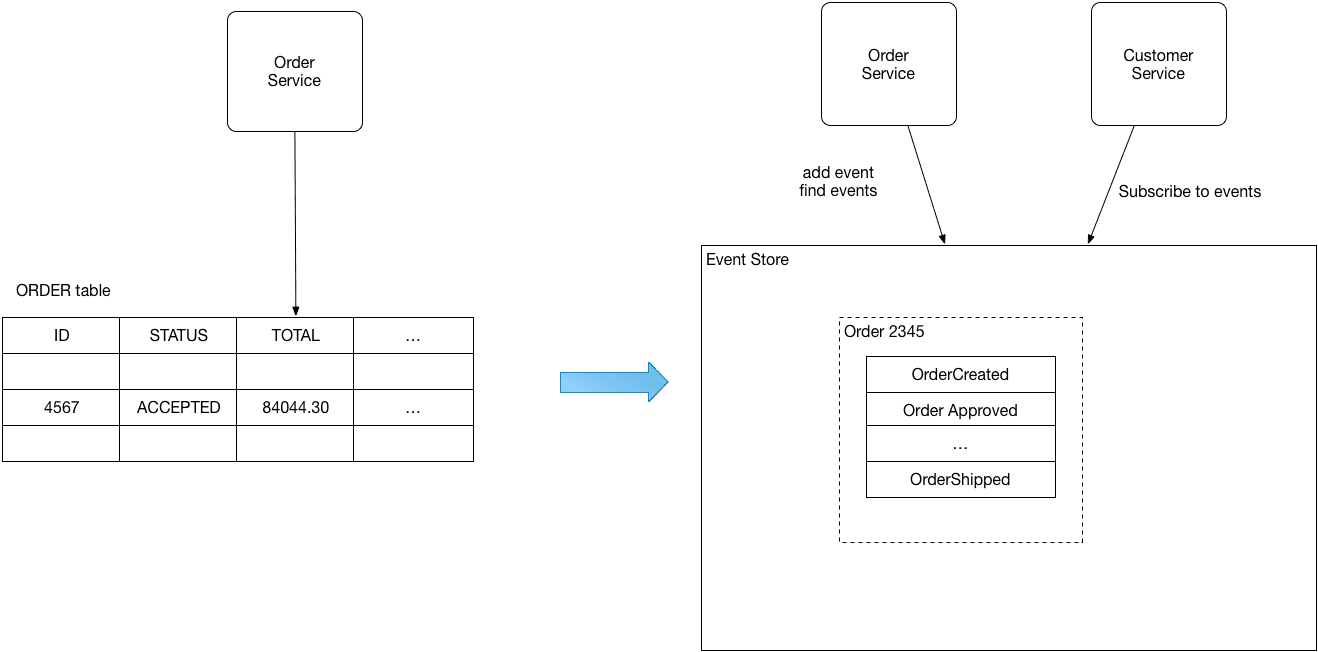
According to Chris Richardson, event sourcing gives the best possible solution among all the data management patterns. Event sourcing indicates the state of changing activity as the generation or addition of an event in the event lists.
It replays the events that already have been performed within the application. It will store and keep a list of events as the database of events and will use them in the execution of actions. The event sourcing pattern uses APIs to retrieve and add the events and to enable services for subscribing to the events.
The scalable applications are the best examples of using this pattern. Since they have multiple operations to be performed in a fraction of seconds, they cannot afford to reconstruct the event from scratch but rather to run a replay of events.
It enables capturing screenshots of events playing in certain instances of time. These snaps can be used as a form of most recent events that have been played in order to reconstruct those events. This way, the loading time of events can be greatly decreased.
Conclusion
Using Data Management patterns in microservices not only streamlines the SDLC but also speeds up the microservices testing by optimizing the time and development efforts. You should start implementing Data Management patterns as per your coding practices to handle projects in the long run in a microservices architecture. You can also extend your team of software architects by consulting microservices architects or by finding out more about the microservices and agile approach.



