
Click to learn more about author Ramesh Dontha.
Learning about data mining algorithms is not for the faint of heart and the literature on the web makes it even more intimidating. It seems as though most of the data mining information online is written by Ph.Ds for other Ph.Ds. Earlier on, I published a simple article on ‘What, Why, Where of Data Mining’ and it had an excellent reception. Thank you.
Here is a next drill down on top data mining algorithms which seems to get lot of attention and google search volume. In the spirit of demystifying these algorithms, I tried to use every day language wherever I can instead of technical language. I don’t want to apologize for this but I want the ‘purists’ to be aware of this deliberate choice. This article is for the ‘rest of us’ who just want to scratch the surface to do enough damage but not interested in diving deep (yet).
One of the first questions people ask about a particular data mining algorithm is whether it is ‘Supervised’ or ‘Unsupervised’? Here is what those terms mean.
- Supervised learning: Algorithms that need a ‘training’ set of data to learn.
- Unsupervised learning: Algorithms that don’t need any training data to work properly.
Another key question that they ask is ‘What type of algorithm it is based on how it functions’?
Here are the main types of algorithms.
- Classification: These algorithms put the existing data (or past data) into various ‘classes’ (hence classification) based on their attributes (properties) and use that classified data to make predictions.
- Regression: These algorithms build a mathematical model based on existing data elements and use that model to predict one or more data elements are mostly used with numbers such as profit, cost, real estate values etc. The primary difference between classification algorithms and regression algorithms is the type of output in that regression algorithms predict numeric values whereas classification algorithms predict a ‘class label’.
- Segmentation or clustering: These algorithms divide data into groups, or clusters, of items that have similar properties.
- Association: These algorithms find some relation (technically called correlation) between different attributes or properties in existing data and attempt to create ‘association’ rules to be used for predictions. The algorithms find items in data that frequently occur together.
- Sequence analysis: These algorithms find frequent sequences in data (Ex: Series of clicks in a web site, or a series of log events preceding machine breakdown).
- Time series: These algorithms are similar to regression algorithms in that they predict numerical values but time series is focused on forecasting future values of an ordered series and also incorporate seasonal cycles (ex: warehouse inventory management).
- Dimensional Reduction Algorithms: Some datasets may contain many variables making it almost impossible to identify the important variables with an impact on prediction. Dimension reducing algorithms help identify the most important variables.
Additionally, there are some key technical terms that we need to know before we find out about the algorithms. They are:
- Classifier program – A program that sorts data entries into different classes. E.g. a classifier might sort cars into classes such as sedans, SUVs, hatchbacks, etc.
- Outliers – Data points that are out of the usual range. E.g. in a test with most scores between 40-45, a score of 100 would be an outlier.
- Noisy data – Data with lots of outliers
With that background, let us now move onto our featured topic of the most popular data mining algorithms. I have curated this list from various publications but the most important source is this IEEE research paper . Drum roll please. Here we go!
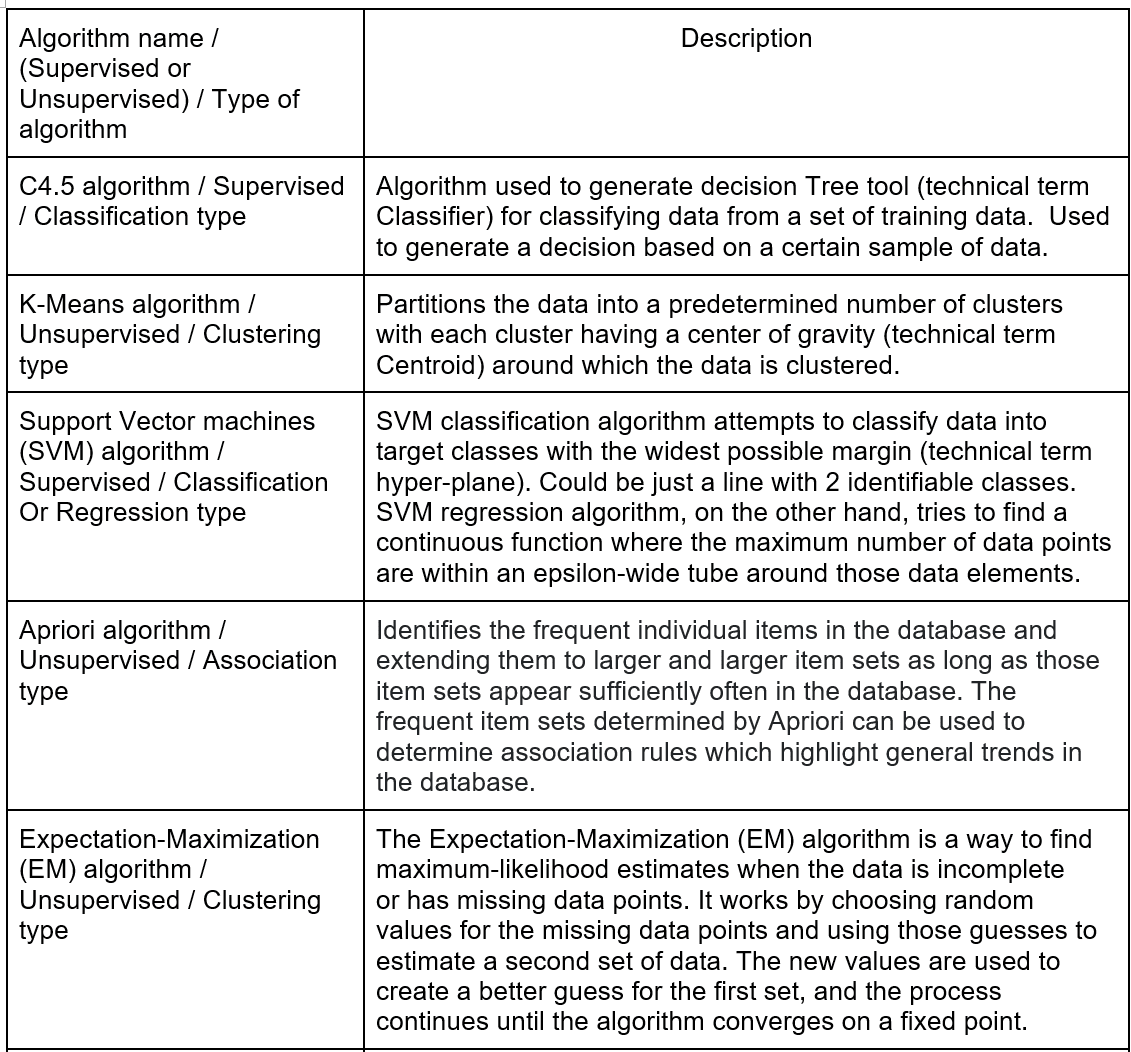
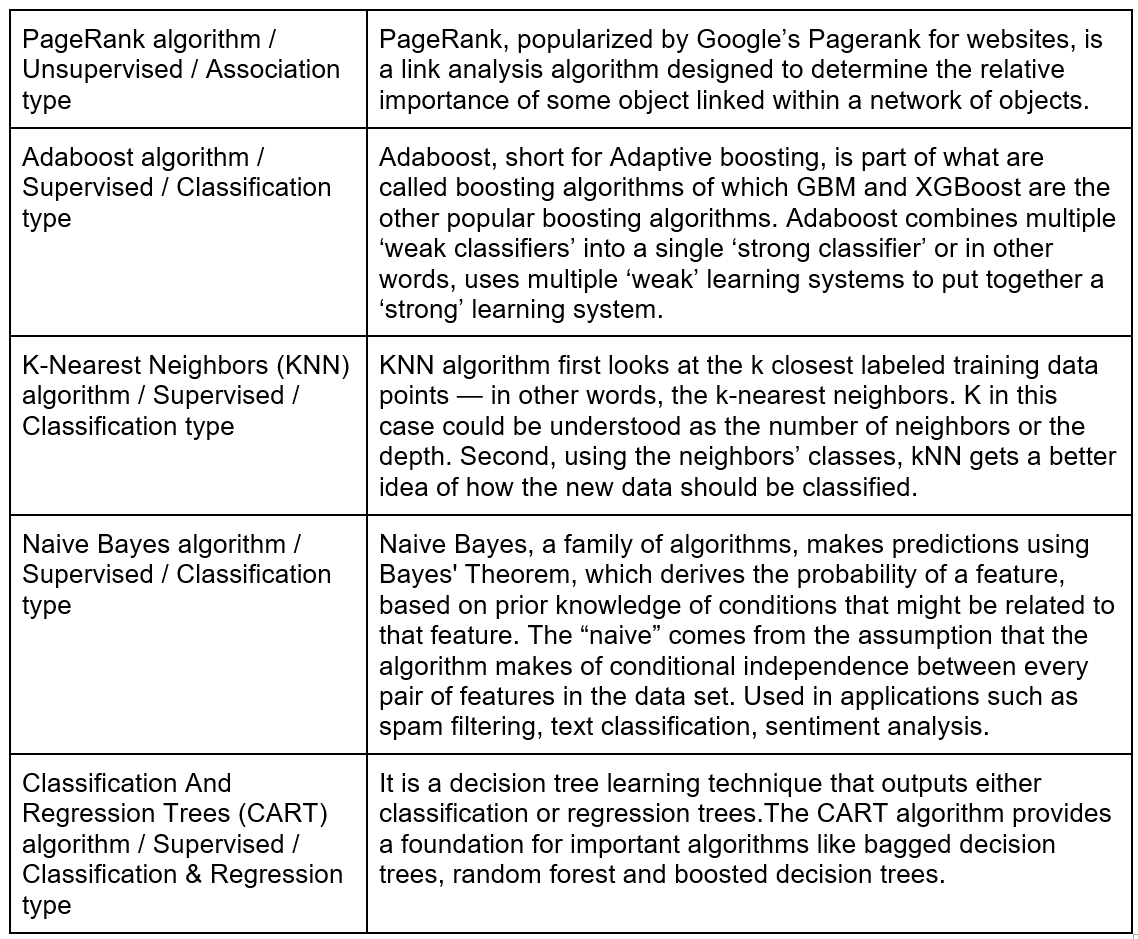
Of course, there are lot of other algorithms like random forest, GBM, XBoost, GMM, Kernel approximation etc. and choosing the best algorithm to use for a specific analytical task can be a challenge. For the same business problem, you can use different algorithms and each algorithm produces a different result, and some algorithms can produce more than one type of result. Hopefully, you are at least familiar with the most popular ones with this article.
Please let us know your feedback and if you have any favorites, please feel free to share with us.