
Key Takeaways
- The data quality checks that work for XGBoost will let you down with LLMs, and the reverse is just as true.
- Quality dimensions accumulate across ML generations. An LLM pipeline still needs null checks on its metadata tables. A tabular pipeline does not need contamination detection.
- Pairing small language models (SLMs) with large language models (LLMs) can cut data quality costs by 60-70% compared to running everything through an LLM.
- The practical framework comes down to: What does my data look like, what model am I training, and where am I in the pipeline?
Introduction
Remember the days when data used to fit in spreadsheets? Now it sprawls across text dumps, image repositories, and billion-token scraped from the open web. The checks we built for tabular data (null counts, type constraints, range validation) still matter, but they stopped being sufficient somewhere around the time deep learning took off. Most teams still grab the same tools regardless. That is worth fixing.
This article traces how data quality requirements changed across three generations of ML, lays out a methodology for picking the right checks, and lands on an architecture where small and large language models work together for data quality at scale.
Data Quality Accelerator
Learn how to build, sustain, and measure a data quality initiative – September 30 – October 1, 2026.

How Data Quality Checks Evolved Across Three Generations of ML
Early ML work lived in the world of structured, tabular datasets. Quality is captured in six canonical dimensions namely completeness, accuracy, consistency, validity, timeliness, and uniqueness. Ehrlinger et al. tested these across 19 algorithms and confirmed what most practitioners already knew: Missing values, outliers, and label noise degrades model performance in predictable ways. Fix the data, fix the model.
Then ML pipelines got ambitious. Teams joined together with multiple datasets, engineered features, split data for train-test evaluation, and a new class of quality problems became visible. Priestley et al. surveyed data quality requirements across full ML development lifecycles and flagged dimensions that traditional data management had largely ignored. They were feature-label correlation, train-test distribution overlap, class imbalance, and data leakage. These are not properties of a dataset sitting by itself. They only show up when data meets a specific modeling task. I have seen teams build a credit scoring model on a dataset that passed every traditional quality check, and still produce garbage predictions because a timestamp feature was leaking future information into the training set. Even though the data was “clean,” the model was broken.
Deep learning and unstructured data made things difficult. Whang et al. studied data collection and quality challenges from a data-centric AI perspective, showing how image, text, and audio data need different quality signals. To put it in perspective, checking for nulls in a CSV is like checking if a shelf is empty. Checking annotation quality on a medical imaging dataset is more like asking three radiologists if they see the same tumor, then measuring how much they disagree.
LLMs changed the scale of the problem. Training corpora contains trillions of tokens from web crawls, books, and code repositories, and the quality issues that come with that volume are different in kind. Dong et al. surveyed benchmark data contamination and found models memorize evaluation data that leaks into training sets, inflating metrics without improving actual capability. To capture this leak Huang et al. proposed the LLM Data Auditor framework for evaluating synthetic data quality and trustworthiness, something nobody was thinking about five years ago.
Which Data Quality Checks to Use and When
Most teams treat data quality as one discipline with one toolkit, and it costs them. You would not use the same inspection process for a warehouse of spreadsheets and a warehouse of radiology scans. The same logic applies here.
Table 1: Data Quality Check Decision Matrix
|
Quality Dimension |
Structured Data + Statistical/Traditional ML |
Unstructured Data + Deep Learning |
Text Corpora + LLMs |
|
Completeness |
Null counts, row counts, column fill rates |
Missing annotations, broken files, truncated samples |
Missing metadata fields, incomplete document segments |
|
Accuracy |
Range checks, referential integrity, type validation |
Inter-annotator agreement, bounding box precision |
Label correctness via human audit, benchmark validity |
|
Consistency |
Cross-table joins, schema matching, foreign keys |
Resolution uniformity, encoding standards, format checks |
Language detection, encoding normalization, style uniformity |
|
Drift detection |
KS-test, Chi-squared, Population Stability Index |
Feature distribution shift in latent/embedding space |
Vocabulary shift, embedding drift, topic distribution change |
|
Duplication |
Exact and fuzzy row matching |
Perceptual hashing, near-duplicate image detection |
MinHash, SimHash, n-gram overlap at document scale |
|
Contamination |
Train-test leakage checks, temporal leakage |
Data overlap across splits, label leakage |
Benchmark memorization detection, train-eval overlap audit |
|
Bias and fairness |
Class imbalance metrics, demographic parity checks |
Label distribution across subpopulations, representation audit |
Toxicity filtering, PII removal, representation analysis |
Structured data feeding statistical or traditional ML models is the most understood case. A retail team I worked with discovered that a “days since last purchase” feature was computed using the order date they were trying to predict. Every quality check passed. The leakage only appeared when they compared train-test distributions side by side. XGBoost and LightGBM still beat LLMs on tabular prediction tasks, and cost a fraction to serve. The quality checks are deterministic and fast.
Unstructured data is a different story. When you are working with images, text, or audio for deep learning, the bottleneck shifts to annotation quality. How much do your annotators agree with each other? Is the class imbalance a problem across subpopulations, not just top-level labels? Are image resolutions and text encodings consistent across batches? Metadata (file sizes, timestamps, naming conventions) is often the only reliable signal when the data has no schema.
Text corpora for LLMs need yet another layer of checking. Deduplication must operate at document and near-document level, not just exact match. Contamination checks are non-negotiable: Does your training data overlap with your evaluation benchmarks? Remember when the Codeforces community caught GPT-4 reproducing solutions to competitive programming problems that appeared in its training data, a clear case of benchmark contamination distorting capability measurements. Filter for toxicity, bias, and personally identifiable information before training, not after. If you generate synthetic data, validate it as rigorously as human-produced data. Huang et al. make a strong case that without systematic quality metrics, synthetic data degrades model performance rather than improving it.
The general principle is that quality checks accumulate. They do not replace each other. An LLM pipeline still needs null checks on its metadata tables. A tabular ML pipeline does not need contamination detection.
The Unified SLM-LLM Data Quality Architecture
Recent surveys on small and large language model collaboration, notably Lu et al. (2025, ACM KDD) and Tang et al. (2025), document over a dozen collaboration paradigms between SLMs and LLMs. Several map directly onto data quality workflows. Together they point toward an architecture that is cheaper and smarter than either model type alone.
Figure 1: Unified SLM-LLM Data Quality Pipeline
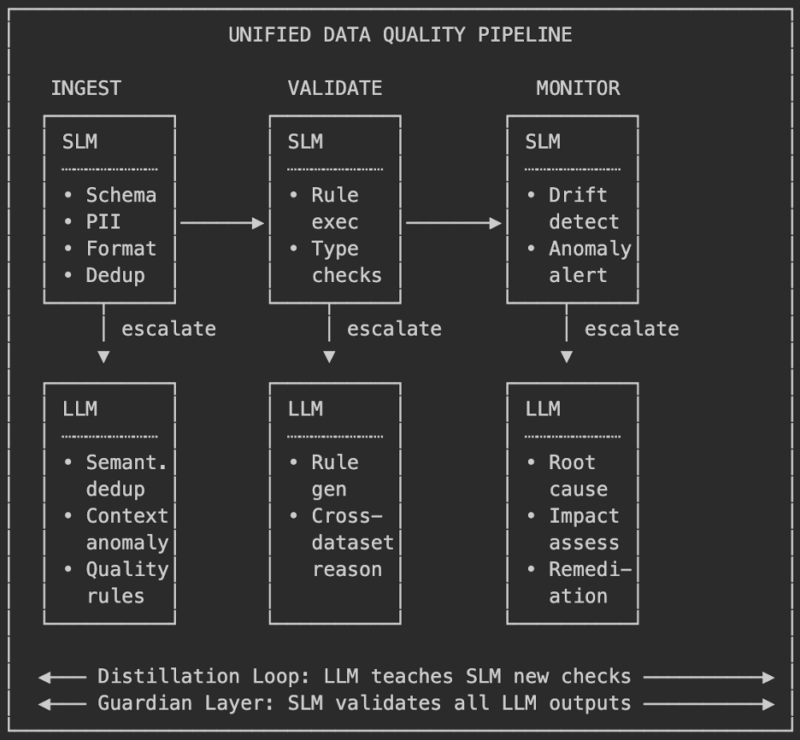
An SLM handles high-volume, routine quality checks like schema validation, null detection, type enforcement, exact-match deduplication, format compliance. These are roughly 80% of all checks and run at 10-30x lower cost than an LLM. When the SLM hits something it cannot resolve, say a semantic near-duplicate or a cross-dataset consistency question, it escalates to the LLM. Hard cases get the expensive model. Everything else gets handled fast and cheap.
On top of that, he SLM profiles thousands of tables and extracts metadata. The LLM reasons over those profiles and generates quality rules. The SLM executes those rules continuously at scale. Databricks shipped a version of this with their agentic data quality monitoring, where AI agents learn historical patterns, adapt to seasonal variation (weekend volume dips, tax season spikes), and flag anomalies without a single hand-written rule. The LLM handles rule generation and root cause analysis. The SLM handles execution and monitoring.
There is also the guardian-generator pattern, which matters for anyone producing synthetic data or auto-generated labels. The LLM generates the data. An SLM validates every output for hallucination, format compliance, and factual consistency before it enters any downstream dataset. IBM’s Granite Guardian models (2B and 8B parameters) and MiniCheck already do this in production RAG systems.
Table 2: SLM-LLM Cost-Performance Profile
|
Layer |
Model Size |
Approx. Cost per 1M tokens |
Latency |
Share of Checks |
Role |
|
Continuous monitoring |
SLM (2-8B) |
$0.01-0.05 |
<50ms |
~80% |
Schema, nulls, types, format, exact dedup |
|
Complex reasoning |
LLM (70B+) |
$1-5 |
200-500ms |
~20% |
Semantic dedup, rule gen, root cause, cross-dataset |
|
Distillation |
LLM to SLM |
One-time training cost |
N/A |
Growing |
Shifts LLM-level checks to SLM over time |
A distillation feedback loop ties it together. Over time, the LLM’s quality judgments, the patterns it spots and the rules it writes, get distilled back into the SLM. The SLM gradually picks up checks that initially required escalation. The system gets cheaper the longer it runs. Tang et al. document this across multiple enterprise deployments, reporting 60-70% cost reductions compared to LLM-only approaches. For context, that is often the difference between a data quality program the organization can actually sustain and one it quietly abandons after a quarter.
Where This Leaves Us
Data quality is not a preprocessing step anymore. It is continuous, it is model-aware, and it looks different depending on whether you are feeding a random forest or a 70-billion-parameter language model. The framework itself is not complicated: Know your data type, know your model family, know your pipeline stage, and pick checks that match. For teams working at real scale, the SLM-LLM collaborative architecture is one way to get serious quality management without the cost spiraling out of control.
The tools exist. The research is there. What is missing, in my experience, is adoption. Most teams know they should be doing more. They just have not figured out where to start. Hopefully this framework gives them a place.
References
- Ehrlinger, L., Grasser, B., Gashi, B., & Wöß, W. (2022). The effects of data quality on machine learning performance. arXiv preprint, arXiv:2207.14529.
- Priestley, M., O’Donnell, F., & Simperl, E. (2023). A survey of data quality requirements that matter in ML development pipelines. ACM Journal of Data and Information Quality, 15(2), 1–39.
- Whang, S. E., Roh, Y., Song, H., & Lee, J.-G. (2023). Data collection and quality challenges in deep learning: A data-centric AI perspective. The VLDB Journal, 32, 791–813.
- Dong, G., Yuan, H., Lu, K., Li, C., Xue, M., Liu, D., … & Sui, Z. (2024). Benchmark data contamination of large language models: A survey. arXiv preprint, arXiv:2406.04244.
- Tang, Y., Liang, K., Sun, L., & Zhang, Z. (2025). A survey on collaborating small and large language models for performance, cost-effectiveness, cloud-edge privacy, and trustworthiness. ACM Transactions on Intelligent Systems and Technology.
- Huang, J., Chen, X., Lin, Z., Wang, J., & Liu, X. (2026). The LLM data auditor: A metric-oriented survey on quality and trustworthiness in evaluating synthetic data. arXiv preprint, arXiv:2601.17717.
Will You Join Us at an Upcoming Event?
Check out our in-depth webinars, demo days, online events, and in-person conferences.




