Click to learn more about author Mike Brody.
Have you ever called about a real estate listing only to learn that the house has been taken off the market? Or had to pick up mail that should have been routed to your new home? Sometimes our records don’t reflect reality, and bitemporality exists to keep track of those moments. Even if you’ve never heard it, you’ve probably experienced bitemporality through situations like these.
More and more institutions, especially in the finance and healthcare sectors, are using Bitemporal Modeling in order to meet regulatory standards and learn from their operational histories. It’s a useful method for storing complex information, comparing data at points in time, and finding patterns.
Although some companies find bitemporality prohibitively complex and expensive to implement, others have successfully transitioned using the right tools and methodology. It is worth noting that there is some variation in how people refer to bitemporality. Some say “bi-temporal,” “bitemporal,” or simply “temporal.” We’ll be using “bitemporal.”
What Is Bitemporal Modeling?
Bitemporality is like version control for your data. It not only shows your records as they are now, but also as they were at any point in the past.
Martin Fowler explains Bitemporal Modeling with a beautifully simple scenario, so we’ll start there. Fowler is a self-described “loud-mouthed pundit on the topic of software development” who has written and published extensively on temporality. He says:
“Imagine we have a payroll system that knows that an employee has a rate of $100/day starting on Jan. 1. On Feb. 25, we run the payroll with this rate. On March 15, we learn that, effective on Feb. 15, the employee’s rate changed to $211/day. What should we answer when we are asked what the rate was for Feb. 25?”
Our answer to this question depends on what source we consider most authoritative: the record or reality? The fact that they disagree effectively splits this payroll event into two tracks of time, rendering neither source entirely accurate.
On one track, there’s what we thought was true — that the employee made $100 per day. On the other track, there’s truth itself — that the employee made $211 per day. When the employee complains on Feb. 25 about receiving the $100-per-day rate, we need to be aware of both tracks. With this information, we can also be made aware that somehow, somewhere, an important piece of information failed to reach the payroll office in a timely manner, resulting in further operational inefficiencies.
Bitemporal vs. Nontemporal Models
In order to understand what our record-keeping options are in this scenario, we have to begin with a nontemporal model. The only question a nontemporal model can answer is what a document’s state is now. So on March 14, the record would show the employee collecting $100 per day indefinitely (hence the null end date):

Nontemporal models show no historical data, so we have no record of the employee’s old rate or the payroll mistake. Old records are simply overwritten with changes.
The next level would be a unitemporal model, which can tell us two pieces of information: what the document’s state is now, and what its state was then as we understand it now. Using this model, the March 15 record would read:

Instead of overwriting the old state, we add a new record showing the new one. In this iteration, at least we have record of the employee’s original pay rate. Unfortunately, the record doesn’t explain why payroll sent him the wrong amount of money on Feb. 25. According to this, they knew how much he was owed and shortchanged him anyway, which we know to be factually false.
How Bitemporal Modeling Can Help Interpret Data vs. Reality
This is where Bitemporal Modeling comes in. To show the disparity between the record and the actual pay-effective dates, we need to record both tracks of time. Enter bitemporality. Let’s refer to the record track as System Time (sometimes called “transaction time” or “record time”) and the reality track as Valid Time:
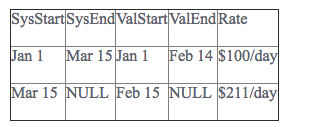
To read this table, we want to index using the System Time columns. We know that wherever the SysEnd value is null, the record is current. The second row has SysEnd equal to null, so we know that we currently believe the employee’s current pay rate of $211 per day to have begun on Feb. 15 and to persist with no specified end date. Because we’re keeping track of both System Time and Valid Time, though, we can now use this table to explain what happened on Feb. 25.
Again using the System Time columns to index, we see that Feb. 25 falls between the start and end dates for the first row, so we know to look there for an explanation. The System and Valid start times don’t differ, so there’s no information to be gleaned there, but there is a disagreement between the ValEnd and SysEnd values. We paid the employee the $100-per-day rate on Feb. 25, even though that rate expired on Feb. 14 (ValEnd) because we didn’t know it had expired until March 15 (SysEnd).
This type of bitemporal model is just one of many ways to structure metadata, but it illustrates the concept well.
Implementing bitemporality is no small feat. Adding four date values to every data point effectively quintuples the size of your database, and that’s just the tip of the iceberg. Nevertheless, large-scale enterprises with high transaction velocity and an inherent need for precise historical reporting will find it an invaluable asset to their Data Quality.


