Click to learn more about author Seth Deland.
Machine Learning seems to be the engineering industry’s latest buzzword – a technology with astonishing potential, yet one that many businesses struggle to understand, let alone embrace. Just last year, fewer than one-third (23%) of businesses had adopted any level of Machine Learning automation, and only 5% reported using it extensively. However, there’s been a recent surge in implementation across a variety of industries, from automotive to finance, as companies begin to grasp the sizable benefits Machine Learning can bring.
For businesses looking to adopt Machine Learning, a crucial first step is to ensure that decision-makers have a technological understanding of what exactly Machine Learning is, and the business potential that can be unlocked through this understanding.
At a base level, Machine Learning teaches computers to do what comes naturally to humans and animals: learn from experience. This involves the use of algorithms that can “learn” directly from data without relying on a predetermined equation as a model. The algorithms adaptively improve their performance as the number of available data samples increases. The ever-growing volume of data drives Machine Learning’s potential within business applications.
More Data, More Questions, Better Answers
Machine Learning algorithms find natural patterns in data and derive insights that lead to better predictions and decisions. These algorithms are used in medical diagnosis, stock trading, energy load forecasting, and more. Streaming sites like Netflix rely on Machine Learning to sift through millions of options to render movie recommendations. Additional applications include:
- Computational finance, for credit scoring, algorithmic trading, and sentiment analysis
- Image processing and computer vision, for face recognition, motion detection, and object detection
- Computational biology, for tumor detection, drug discovery, and DNA sequencing
- Automotive, aerospace, and manufacturing, for predictive maintenance
How Machine Learning Works
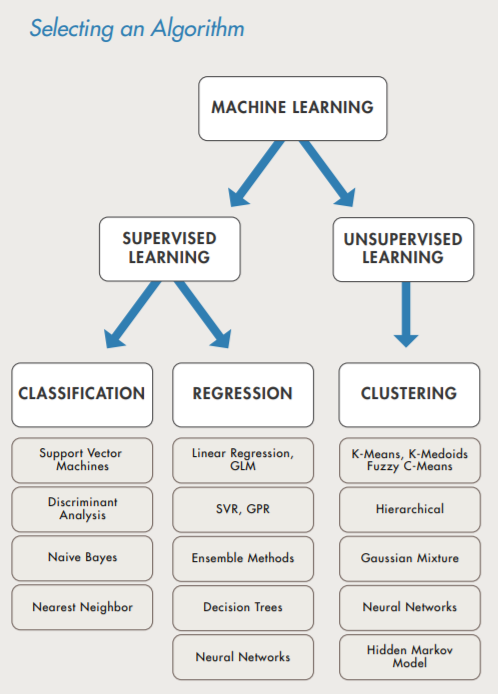
Machine Learning uses two types of techniques: supervised learning, which trains a model on known input and output data so it can predict future outputs, and unsupervised learning, which finds hidden patterns or intrinsic structures in input data.

- Supervised Learning
The aim of supervised Machine Learning is to build a model that makes predictions based on evidence in the presence of uncertainty. A supervised learning algorithm takes a known set of input data and known responses to the data (output) and trains a model to generate reasonable predictions for the response to new data.
These predictions are developed through classification and regression techniques.
- Classification techniques predict discrete responses—for example, whether an email is legitimate or spam, or whether a tumor is cancerous or benign. Classification models classify input data into categories. Typical applications include medical imaging, speech recognition, and credit scoring.
- Regression techniques predict continuous responses—for example, changes in temperature or fluctuations in power demand.
If applied correctly, the intuitive capabilities of supervised learning techniques are almost limitless. They have even been used by clinicians to closely predict whether a person is at risk of a heart attack by accessing data on previous patients, including age, weight, height, and blood pressure, and historical knowledge of those who have had heart attacks previously.
- Unsupervised Learning
Unsupervised learning is used to draw inferences from data sets consisting of input data without labeled responses.
Clustering is the most common unsupervised learning technique. It is used for exploratory data analysis to find hidden patterns or groupings in data. Applications for clustering include gene sequence analysis, market research, and object recognition in images.
Understanding which learning technique is best suited for a specific project or application, while important, is only the first step in enabling the capabilities of an integrated Machine Learning system. Choosing the correct learning algorithm and, finally, determining the best time to utilize the technology, round out the process.
Selecting the Appropriate Algorithm
Choosing the right algorithm can seem overwhelming — there are dozens of supervised and unsupervised Machine Learning algorithms, and each takes a different approach. There is no best method or one size fits all.
Finding the right algorithm is partly trial and error; even highly experienced data scientists can’t tell how well an algorithm will work without trying it out. Algorithm selection also depends on the size and type of data being collected and analyzed, the insights the data is meant to reveal, and how those insights will be used.
Fortunately, Machine Learning and software tools can optimize the algorithm selection process by allowing engineers to explore their data, apply many different models, and more accurately predict how the algorithm will interact with the complete system.
Implementing Machine Learning at the Right Time
After the team has established which algorithm is best suited for a function or project, it will need to consider when to implement the technology. It is best to leverage Machine Learning for problems involving large data sets with lots of variables, and where there is no existing formula or equation. Often, companies rush to select and integrate an algorithm and end up wasting time and resources on a task that does not require the complex technological capabilities of Machine Learning. Instead, Machine Learning should be considered in situations where:
- Handwritten rules and equations are too complex, as in face recognition and speech recognition.
- The rules of a task are constantly changing, as in fraud detection from transaction records.
- The nature of the data keeps changing, and the program needs to adapt, as in automated trading, energy demand forecasting, and predicting shopping trends.
Engineering teams will quickly understand and appreciate the power of Machine Learning if it is implemented correctly and within the right context, such as collecting and analyzing large dynamic data sets. The more complicated the task, the more likely businesses are to benefit.