Click to learn more about author Thomas Frisendal.
In the data space plenty of new terms are being coined (by marketing?) for handling data modeling, governance and quality issues: “data preparation”, “data wrangling”, “data catalogue” and “machine-based data harmonization” (™ of ClearStory Data).
Do we need stuff like this? Definitely so. Today we need to move fast, be agile and model as we go. Applying raw machine power (lots) and AI can do much of what Human Intelligence (applied as data modeling) has done over the years. But how much?
Are we facing yet another situation where we need something like a Turing test? How can we determine whether a data model is created by Robo, the Data Modeler, or by guys like myself?
I use this depiction of the lifecycle of Data Modeling:

Forward looking, design first, implement, evaluate and re-iterate. HI manages this well, but we are not the fastest fish in the ocean… And we are not good at changing our data models at the slightest whim of changing market conditions, for example. We can infer stuff from the data and the meta data that modelers before us created and kept running for umpteen years. Data profiling helps a lot in that situation, and it is part of the whole data preparation and wrangling trend of today. Sort of a first step in machine-assisted data modeling.
But in general, what could a “data modeling Turing test” look like for detecting a human influence?
What we are good at are several aspects of concept and Data Modeling, which need overview, business knowledge, abstract thinking, context awareness and even empathy with the business people, whom we serve.
Vocabulary. First there is the issue of terminology. Legacy databases tend to use technical jargon, abbreviations or downright obscure names of data items. Most of what we use Data Models for is Analytics, and Analytics speaks with the business folks. No “lost in translation,” please!
Functional dependencies. Many legacy databases have odd Data Models. Could be that the development framework generated some not quite normalized data structures. Or the programmers did. They just needed to dump some data from screen to disk. Check the dependencies! Physical Data Models are frequently out of sync with reality.
Event driven modeling. Good Data Models reflect the fact that businesses are driven by events that have certain relationships, which together make up a work flow. Data Models are like language. Subject-predicate-object is the basic building block. This is why denormalized event-driven star schemas are so successful in business intelligence. Stay close to the humans, talk their language, and model with intuition and context awareness.
3rd party Data Models are semantically peculiar. Much of the Big Data excitement is above new technologies machine generating data according to a, most likely, Data Model that the legacy systems do now know about. Integration is just as much about bridging the terminology differences (context descriptions) as it is about translating RFID data to something that can be matched with an existing customer database, for example.
Agility. Machine-generated Data Models should adapt over time. Changes happen to technologies, leading to changes in business models and economy models also change (hopefully) over time (sustainability, for example). Keeping track of what the semantics used to mean and comparing to what they should mean to day, is a challenge that Human Intelligence can handle (if we concentrate, that is). The problems with agility until now have not been modeling problems as such, but rather technical challenges with database restructuring and programs and reports refactoring.
Generalization. Generalization is one of the most productive tools available to Data Modelers. And we use it! What you see in data is subject to have been designed for a particular level of generalization (maybe for practical reasons or maybe because of lack of time to do a proper break down). Part of this discussion also relate to string-encoded repeating groups in flat records. Even subject aress have been generalized; when you look into them one level down, they do have a structure. So maybe the way forward is specialization. That is a business decision, facilitated by the good Data Modeler.
Data Quality. Data Quality is not as good as it could be. In my own experience from various contexts about 5 % of all transactions have more or less annoying data quality isssues. (Much of it in the context, not in the transaction itself). But this makes it hard to determine for instance proper relationships (functional dependencies). What if a candidate key only has a quality of 95 % percent? Who decides whether it is a real relationship or maybe just a non-sensical coincidence?
Region and culture. Even in the same context there are differences introduced by regional or cultural conventions. Coexistence is probably necessary. This applies to vocabulary as well as context.
So what do yo say, Robo Data Modeler? Big mouthful, yes, but undoable? Very likely the way forward for the next few years will be AI and HI working together in what could be called “machine-assisted data modeling”. Because we need the data modeling food chain to start at the time of “Implement Physical Data Model”.
This is a new process in the life-cycle of Data Modeling:
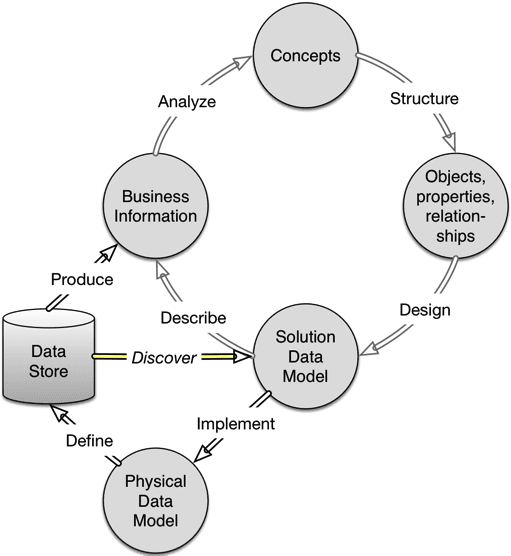
AI will discover and infer (some of) the solution level Data Model from the physical Data Store, contents as well as contextual information. There will be some additional HI for some years to come for the handling of the challenges outlined above. But it will be a whole lot more agile and also provide good quality.

Much of the above is certainly doable using AI today. Many vendors have good demos of some of the key capabilities of newly born Robo Data Modelers. Keep them coming!
My reservation at this point is that to mature out of infancy the Robo Data Modelers must address the harder, more reflective isssues described earlier in this post. This will take some time, and it will require a new generation of Agile Data Modeling tools with repositories / catalogues and more; having smooth facilities for AI and HI working together in harmony and efficiency in agile situations.
Exciting times to live in! Come on in, Robo Data Modelers, have a seat!



