
Click to learn more about author Dávid Szakallas.
In recent years, the size and complexity of our Identity Graph, a data lake containing identity information about people and businesses around the world, begged the addition of Big Data technologies in the ingestion process. We used Apache Pig initially, and then migrated to Apache Spark a couple of years ago. Here is a closer look at our journey and vital lessons we learned along the way.
Our team selected Apache Spark primarily because a large part of the ingestion process consists of convoluted business logic around resolving and merging new contact points and agents into the existing graph. Such rules are difficult to express in SQL-like languages, whereas with Spark it’s possible to utilize a full-fledged programming language, such as Scala, Java, Python or R. We settled on using Scala, which enabled us to write and easily extend the logic, which is important for rapidly integrating new providers.
This flexibility came at a cost, though. Due to its complexity, it’s almost impossible to apply tabular data related optimizations on custom Scala code. It also became apparent over time that using Scala closures incurs so high memory usage and so heavy CPU cycles spent on garbage collection and object serialization, that CPU and memory becomes the bottleneck of distributed parallel processing, instead of disk and network I/O. Fortunately, when these problems started surfacing in our ingestion pipeline, Apache Spark already included a managed SQL runtime, which resolved most of these shortcomings. We realized that we have to switch in order to maintain scalability in the face of the expected data size growth in the upcoming years.
Spark SQL to the Rescue
Our legacy code used the RDDs of plain Scala objects in combination with Scala closures to carry out all of the transformation logic.
The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel.
This was the most straightforward and advocated way to write Spark programs in Scala a few years ago. Moreover, the API closely resembles Scala’s own collection interface and borrows concepts and terminology from functional programming which was just becoming mainstream at the time. This programming style was easy to pick up with basic Scala knowledge, and found its followers among people aspiring to try out functional programming applied to Big Data use cases. Snippet 1. gives a glance at this style.

Snippet 1. Transitive closure over a directed graph using Spark RDDs
Over time, however, it became evident that programming our ingestion pipeline this way is far from ideal performance-wise. By this time, we had a monolith ingestion application that amounted to a perplexing 30 000 SLOC written purely with RDDs and Scala closures. We were struggling with increasing costs due to higher amounts of RAM and CPU usage, unreliability and correctness bugs.

Figure 1. Problems with our legacy code
The performance issues of using plain RDDs were already well-documented at the time. Furthermore, Spark SQL, an optimized API and runtime for semi-structured, tabular data had been stable for a year.
Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations.
Migrating such a large application to Spark SQL is not an easy effort, although we remain on the same platform, and the RDD and Spark SQL code can be mixed. This means the migration can take place incrementally, which is helpful, as it allows other work, such as developing features required by the business, to be interleaved into the refactoring process.

Snippet 2. Spark SQL version of the transitive closure algorithm, using the untyped DataFrame API. Notice that columns are referenced as strings.
Why is Spark SQL so Fast?
Several materials are available online on Spark SQL [1] [2], so I will only cover the most important facts here.
Spark SQL leverages a query optimizer (Catalyst), an optimized runtime and fast in-memory encoding (Tungsten) for semi-structured, tabular data. This enables optimizations that before were impossible. In addition to basic rule-based optimizations – e.g. moving filters before selections (often referred to as filter pushdown, a well-known optimization rule in relational query planners) – Catalyst collects statistics about the datasets to carry out cost-based optimizations, e.g. reordering joins to keep the intermediate size low or choosing the best possible strategy for individual joins.
Spark SQL compiles efficient code for the physical plan that directly manipulates raw binary data, evading garbage collections and lowering the memory footprint.
While the advantages Spark would eventually bring our Identity Graph were very clear early on, before moving forward we would need to confront the solution’s drawbacks.
A step back in ergonomy?
In our decision to move forward using Spark SQL, right out of the gate we knew we may be taking a step back in ergonomy. Here are some of the things we experienced at the onset:
- Lack of expressive power: Naturally, we expected that certain code parts could not be migrated, as SQL is less expressive than Scala. What’s more, we rely on a few external libraries written in Java. This didn’t strike us as a huge limitation, however, since RDD code can be mixed with SQL.
- Restricted set of data types: Spark SQL supports the most popular data types occurring in structured data. It suffices for most use cases, however representing and operating with arbitrary Java objects is a non-trivial matter.
- Losing compile-time type safety: Arguably, one of the most compelling features of the typed RDD API is being able to describe distributed computation similarly as if the code was working on local Scala collections. Its design ensures that most errors are caught compile time, and that IDEs and code editors can use the language’s type system to provide autocompletion and other insights. Unfortunately, Spark SQL may force us to give up on these benefits.
These last two limitations caused us to scratch our heads, hard, as they directly hindered two of our principal imperatives:
- To continue leveraging the type checker.
Our team is committed to using the best Scala can offer towards type safety. As I mentioned before, we were very pleased with the RDD API in this aspect. Unfortunately, recently we’ve seen less traction towards designing type safe APIs for data processing in Spark, which forces developers to write less idiomatic Scala code when working with Spark, considering the industry standard. This may be in part attributed to the shift of focus on Python, which boasts a larger user base especially among data scientists, and that Scala’s mechanisms for type safe programming are highly unconventional and idiosyncratic, which makes it hard to learn for developers arriving from different languages. - To reuse existing domain types and keep compatibility with existing schema.
We modeled our schema in the form of Scala case classes, most of which contained members with types outside of the supported range of Spark SQL. The most ubiquitous example is java.util.UUID, which we had all over the place. Getting rid of it would have involved changing every single domain class, and the alternative of using a String or tuple of Longs are actually semantically less meaningful. The second violator was scala.Enumeration. Although they bear some ill-repute, Scala enumerations provide a basic and lightweight way to express disjoint alternatives. We represented the values as integer ordinals in the serialized format.
A Tale of Two and a Half APIs
Spark offers two front ends for its SQL platform.
One is SQL strings. This was the initial front end for Spark SQL, included in Spark 1.0 as an alpha component. Needless to elaborate on how inconvenient and error prone it is to compose a non-trivial codebase as a series of steps formulated in strings, embedded into a programming language.
Dataset API is the other. The contributors, introduced the DataFrame API in Spark 1.3 similar to RDDs, but untyped. In Spark 1.6, they introduced a typed counterpart to it, which they named the Dataset API. In Spark 2.0, the two APIs were united under the Dataset name, which now provides functionalities of both flavors with opt-in typing. If the nomenclature wasn’t confusing enough, PySpark and SparkR APIs, where the typed Dataset does not exist, still refer to the untyped version as DataFrame, whereas in Java Dataset<Row> is used for the same concept.
There should be no debate on choosing between strings and the latter if you are writing anything more complex than some ad-hoc query in a notebook capable of accepting SQL directly. However, deliberating between the typed and untyped facade of the Dataset API is a lot less straightforward.
To get a clearer picture, let’s see how they work in action!
The first difference between the two flavors surfaces immediately when parallelizing a local collection.

Snippet 3. Example dataset of books
Oops, a compile time error. Note: you might not encounter this when running in a notebook environment, as those usually have the necessary import.
I’ll return to this in a minute but for now, let’s move on with a more realistic use case and read a Parquet file.

The only option is reading into a DataFrame, and using the as method with a type annotation to cast it to the specified schema. If we look up the method definitions, we discover that both methods require an implicit Encoder instance. Indeed, if we look at the other Dataset methods that return a Dataset[T], we can see that each requires an Encoder[T] in turn.
Encoders
The Encoder is the core concept of the typed API, responsible for converting between JVM objects and runtime representation. Spark SQL comes with Encoder implementations for a selected class of types. As the error message informs us, these can be brought into scope by importing spark.implicits._, and will make the error messages disappear in the above cases. Encoders are defined for JVM primitive types, their boxed versions, strings, a couple of time types under java.sql, java.math.BigDecimal, their products and sequences (see docs). Maps are also supported with certain limitations.
Suppose now, that we want to assign an International Standard Book Number (ISBN) to each book. After all, we are developing a digital system. A possible implementation stores the number in a single Long field and provides extractors for the parts.


Snippet 4. ISBN class and modified book examples. We won’t be able to get rid of the error easily here.
Running this code results in a runtime exception like in Snippet 5. ISBN is a custom Scala class, Spark is unable to encode it.

Snippet 5. Runtime error when encoding a product field with an unsupported type
The problem is easier to understand when we try to encode the class directly as in Snippet 6.

Snippet 6. Encoding an unsupported type
To resolve this situation, we have to write an encoder for ISBNs first, and make it available in the callsite’s scope. Spark provides some mechanism for this through their internally used ExpressionEncoder case class. Snippet 7 shows a basic implementation of the ISBN encoder using Spark’s ExpressionEncoder.

Snippet 7. Basic example of the ISBN Encoder
Using the ExpressionEncoder comes with major drawbacks. First, we still get the same error as in Snippet 6 when trying to serialize our books, i.e. we cannot embed the ISBN into an arbitrary product. This happens because the product encoder tries to match a closed set of alternatives when deriving schema for the fields, and does not consider our freshly defined ISBN encoder. Second, even if we were able to, we wouldn’t want to have the superfluous struct wrapper around our value (i.e., we want to handle top-level and field cases differently). We can’t do that without some additional context on where we are in the serialization tree.
At this point, things get a bit daunting, as it is clearly the case that the encoder framework wasn’t designed to be extended compile-time.
Frameless
Frameless is an excellent library that provides a more strongly typed Dataset API among other things. Frameless rolls their own compile-time extendable encoder framework, called TypedEncoder.
Frameless builds heavily on, and gets its name from, shapeless, a dependent type based generic programming library for Scala. Due to the complexity of the topic, an introduction to type-level generic programming is out of scope here. Fortunately, there are plenty of online materials at the interested reader’s disposal.
Without going into too much detail, the gist of the TypedEncoder framework is using compile-time implicit recursion to derive the Encoder for the T type. Frameless defines instances for primitive types such as Longs, Ints, and higher-level encoders, which use these as leaves, such as Option[T], Seq[T] or the recursive product, which relies on heavy type-level machinery to get the work done. The skeleton for this framework is shown in Snippet 8.

Snippet 8. TypedEncoder skeleton
The next step is writing our ISBN encoder using this framework. It handles nulls and top-level data for us, which serves to simplify our code (as shown in Snippet 9). Note: make sure our previous definition of Encoder[ISBN] is not in scope anymore, otherwise you’ll get an ambiguous implicit argument error.


Snippet 9
Let’s look at a second example, and add an enumeration signifying the format of the print. Enumerations are unsupported, so we’ll have to create an Encoder for them as well. This is shown in:

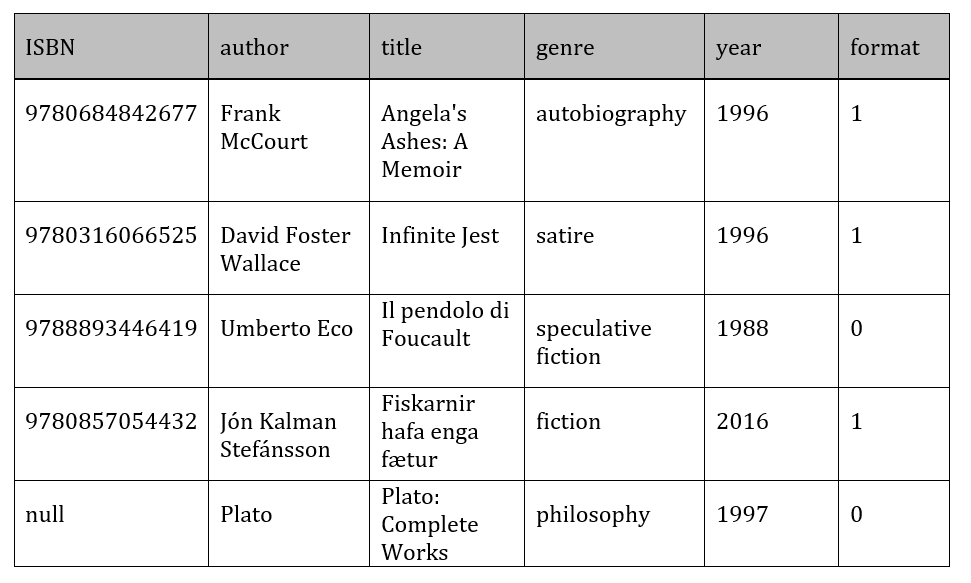
Snippet 10. An enumeration encoder
It works, but it isn’t generic. Each time a new enumeration is added, a new Encoder must be defined with the same behavior. Solving this problem requires a bit of shapeless magic. Enumeration types are represented as objects, thus we have to generate an Encoder for each separate Enumeration object. Sadly, the language doesn’t provide good mechanisms to retrieve the instance for the specified object type. We’d have to either modify the definitions by making them implicit objects, or assign them to implicit vals. The first requires us to change the definition site, the second adds boilerplate. The Witness type tool helps by extracting this information from the compiler, and generates the implicit ‘witness’ value for our singletons. Once again, make sure the previous definition is no longer available in the scope.

Snippet 11. Generalized enumeration encoder
Another, more type-safe way of representing enums is through the use of sealed traits. Creating Encoders for such enums – or more generally speaking, coproducts – involves digging into much more type-level programming than would be suitable for this post.
Conclusion
I hope you enjoyed this overview of the basics of Spark SQL and why it was necessary for my business to migrate to it despite its obvious limitations regarding type safety. What’s been your experience? Are you facing a similar challenge? Leave a note in the comments, I’d love to hear about it.



