
Many organizations have mapped out the systems and applications of their data landscape. Many have documented their most critical business processes. Many have modeled their data domains and key attributes. But only very few have succeeded in connecting the knowledge of these three efforts. The remainder of this point of view will explain why connecting the three spheres of Data Management – systems, models, and use cases – is so critical and how it can be done, by discussing the following:
- Explanation of the three spheres
- Examples of unlocked value
- Key implementation pitfalls
- Implementation approaches
- Solution architecture components
- Key roles across the three spheres
The Three Spheres of Data Management
As mentioned, very few organizations succeed in connecting the knowledge of the three spheres of physical systems, data modeling, and business processes. They fail to reach the center of the following figure and therefore to unlock the potential benefits that (meta-)data management can offer.

For each of the three spheres, information and metadata can be documented. They include the following:
I. Physical Systems: Capture and documentation of metadata for physical systems and applications, such as table descriptions, column names, technical metadata, data lineage, data flows, and access and editing log data.
II. Data Modeling: Conceptual and logical Data Modeling, covering and clarifying data elements, data domains, owners, and definitions. This often includes business glossaries and data dictionaries.
III. Business Processes and Use Cases: Inventory and description of the organization’s key current (and sometimes future) business processes and related use cases, often related to organizational divisions such as customer management, product or service delivery, marketing, finance, risk, and human resources.
Examples of Unlocked Value
Let’s take an example from the banking industry to understand why the three spheres mattes. I was recently part of an effort to ensure that data was fit for purpose for a bank’s anti-money laundering (AML) process. AML is a classic example of a business process that is fairly far “downstream,” heavily dependent on data from other “upstream” domains within the bank. Required input data included data on customer identification, source of funds, beneficial ownership, and transactions. Given that this process is located downstream, the lineage was followed back upstream, identifying the feeding systems and data producers.
Putting this all together, the AML process owner was enabled to very clearly articulate what data is needed (II), for what purpose (III), and through which systems (I). This was critical to convince regulators that the bank was compliant with AML regulations and standards. Additionally, the AML process owner could communicate clear requirements for the data in terms of completeness and accuracy to the upstream data and systems owners, securing its fitness for purpose.
In another example, a chief data officer in the retail sector initiated an effort to identify and activate data products. The first prioritized data products concerned marketing and customer service use cases that depended on various cuts of the customer data to enable segmentation and personalization. Considering these use cases (III), identifying the data (II), and enabling them through one prepared data asset (I) is where true value was created as the return on marketing investment increased and customer service was enhanced.
Pitfalls
Three scenarios exist wherein organizations have reached an area adjacent to the center, but still outside it, hence failing to unlock value. These scenarios correspond to the three pitfalls in the below figure:

Let me describe each of these pitfall scenarios:
- Pitfall Type 1 : Lacking Business Context. This is the most common pitfall, where physical systems are described, and so is the data that sits within them, but neither are matched to business processes. This can happen in organizations with a Data Governance program that is focused on creating data models as well as metadata related to data in physical systems. Without explicit links between data elements and physical systems on the one hand, and consuming business processes on the other, it is practically impossible to assess business impact, investment returns, Data Quality issue impact, and upstream data changes.
- Pitfall Type 2: Skipping Data Modeling. Data models drive understanding of data across systems and processes; you could take a specific logical data attribute, like customer name, and verify in what systems it lives and what business processes use it. Data models provide clear definitions and ensure that the right data (and only the right data) is used by the right consuming processes. Without Data Modeling rigor, data is bound to be used inconsistently, misunderstood, and improperly classified, leading to data and system duplication, and security, reputational, and regulatory risk. In this scenario, it might be known what systems are used for what business processes, but there is no standardized understanding of the data.
- Pitfall Type 3: Keeping It Theoretical. In this scenario, data domains and models are defined, and they are also linked to business processes or use cases, but the linkage to actual systems is missing. This can be the case in organizations where the systems landscape is particularly scattered or outdated, or where there is an established, historically strong IT organization that is set in its ways. Failure to relate business processes and data models to the physical landscape will imply that no value can be created because the real data can only be governed in actual, physical systems, where it is captured, stored, transformed, and used. Involving IT or system owners early on is therefore recommended.
Implementation Approaches
It is impossible to map all relevant (meta-)data across the three spheres in one single sweep. Several approaches can be used to get to the center of the figure for a given incremental scope, and three of them are highlighted in the below figure.

Paths to connect the three spheres and unlock true insights and value:
- Use Case-Driven: The AML example I provided earlier fits into this category. You take a given existing business process or use case as a starting point, and you identify the systems that are currently feeding it. With systems identified, you can identify and model the data within them. (For a new use case, you can swap the last two steps, first identifying the required data, and then drawing up the required solution architecture.)
- Domain-Driven: You first prioritize and identify the data domain, for example, customer data. You then identify the business processes and use cases, and finally, for each of those, the systems that are involved. This method is very much aligned with the recommendable best practice of domain-driven Data Governance, wherein data is governed based on a defined bounded context. Systems and use cases may change, but domains are more stable and are typically where data ownership should reside. However, this is also the messiest approach, as a domain is a more abstract starting point than a use case or system, which are more tangible.
- Physical systems: Start by selecting a system, next identify the data that it holds, and then identify the business processes that drive and consume from it. This is the most straightforward and easiest actionable approach, as a system is very “real” and easy to identify. However, there are risks. Domains and business processes are more comprehensive and stable – it is easier to compile a full list and to then prioritize them. With systems, selecting one system over another, in the absence of knowing what data they hold and what business processes use them (because remember, that’s the exercise here!), is a more or less random action. In some limited scenarios this can still be a useful approach, when it is known a priori that a system is particularly critical for the organization; for example, when considering an MDM hub or product master system.
In practice, organizations almost assuredly will see efforts along all three approaches, and that is entirely appropriate. The key here is to have a sound Data Governance and metadata management foundation wherein created knowledge can be documented and maintained for everyone to benefit from it. Such a foundation may have many parts, but I’d like to emphasize two major components of a corresponding solution architecture.
Solution Architecture
First, there is the enterprise metamodel. A metamodel is a data model for metadata, which describes the core metadata objects, along with their relationships and associated business rules. In our discussion here, it would outline how systems, data, and business processes are linked together. In a way, it provides the rules that dictate how a language can be spoken, before we start speaking it. With a metamodel in place, metadata can now be discovered and created through the use case-, domain-, and system-driven approaches.
Secondly, there is the metadata repository. Whenever metadata is captured through any of the three approaches, it should be stored in a central repository. This will drive consistency and prevent duplication. For example, say that a system-driven effort mapped out the metadata for a customer master system. Later, a use case-driven approach starting with a marketing use case identifies this customer master as a feeding system. Instead of creating a new, duplicate entry (and re-populating all of its metadata), the existing customer master system can just be referenced. A metadata repository can be instantiated through a combination of a data catalog, data dictionary, and business glossary.
Roles
To enable effective data management and to reach that plane where the three spheres interact, it helps to understand the people dimension, because in the end, specifically driving adoption, it’s all about people. The figure below presents a view of key roles and where they typically operate.
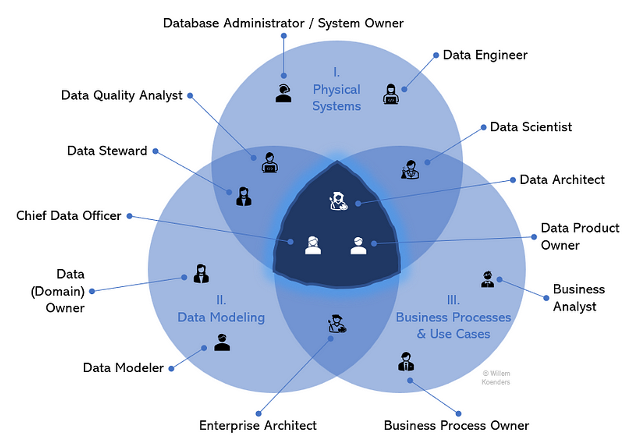
Instead of elaborating on each role, let me call out a few key insights:
- Three roles, by their very definition, should drive the bringing together of the three spheres more than any others: the chief data officer, data architect, and data product owner. The CDO does this at a strategic level — they have the power to articulate why it is critical to get to the center of the figure, educate leadership, and engage executives to drive change and a data-driven mindset. The data architect can do this at a more granular, solution-specific level. For new transformations, they can ensure that for given use cases, the right data is consumed from the right places. As for the data product owner, I will come back to this in a bit more detail further below.
- Several roles are predominantly operating in a single sphere. Examples are database engineers and business analysts. These roles are specifically important to consider, as they might not naturally venture outside of their respective spheres, yet they are critical for the overall framework to drive value. Taking business analysts as an example, they are critical to derive requirements for the data for respective use cases and to drive the ultimate value creation, as their analyses should be conducted on the right data from the right source.
- Like any model or figure, this is a simplification of reality. For example, technically, any (good) Data Quality analyst would not create Data Quality rules without considering the intended use of the data; after all, Data Quality is the evaluation of fitness of data for specific use cases. But in reality, they are mostly operating on the plane between Data Modeling (identifying data elements and creating corresponding business and Data Quality requirements) and systems (implementing for data in given systems).
Connection to Data Products
More than any other data concept, data products embody what it entails to get to the center of the figure where the three spheres overlap. A data product typically consists of a single system that contains data and insights for a given data domain, and it functions as a reusable data asset that has been designed to serve specifically identified consuming use cases. It is where systems, Data Modeling, and business processes come together.
This is why the data product owner was placed in the center of the figure, and why establishing an approach around these strategic data assets can accelerate an organization’s journey to unlock value.
Conclusion
In summary, effective (meta-)data management requires the integration of information from three spheres: physical systems, Data Modeling, and business processes and use cases. This unlocks the insights and value creation that Data Management can generate. For those organizations that have not sufficiently succeeded in connecting these spheres to access their potential benefits, utilizing a data product approach can kickstart the journey.



