
Click to learn more about author Thomas Frisendal.
At the DATAVERSITY® Graphorum Conference in Chicago in October I attended Dave McComb’s tutorial on “Data-Centric: Models and Architectures”. At the end, he ran a raffle for his 2018 book, Software Wasteland – How the Application-Centric Mindset is Hobbling our Enterprises (TechnicsPub). I was the lucky winner! I will get back to the data-centric discussion in a later blogpost. However, the Software Wasteland book, which I really recommend you to read, made me think about two important issues, being a data modeler:
- Why is it that data has had a hard time making it to the top of the development priorities?
- Is there a better way of modeling data than the engineering style, legacy crow’s feet?
One of Dave’s key observations is the sheer size of the IT industry (and the next few sentences are quotes from his book). IT is a $3.8 trillion industry – twice the size of the petroleum industry. Capital spending for IT in the US is now $700 billion per year. At 32 percent of the total capital spend, it exceeds construction and is closing in on equipment spending.
That is a lot of money. Dave argues that “At least half – and perhaps as much as 3/4 – of this spending is wasted,” mostly because of unnecessary, accumulated complexity. Which puts many, if not most, enterprises in a quagmire as time goes by. And it is very difficult to emerge on the other side of the quicksand.
I am not going to recap the whole of the book; you will have to read it yourself. But the quagmire is caused wholesale by application-centric approaches to large projects. Dave’s company has an online assessment test, where 5 times ‘Yes’ and 5 times ‘No’ will confirm that you are already deep into the quagmire.

The issues are: replacement of systems with yet another package, missing defined systems of record for major entities, “not reinventing the wheel”, data conversions, data sharing, data cleanups, consistent security / authorization schemes, spending more on integration than on new functionality, integration of structured and unstructured data. Take the test here: https://www.semanticarts.com/assessment/.
The book has plenty examples of “how to spend a billion dollars on a million-dollar system”. And it is certainly very harsh on some of the actors in the industry. Most, for several reasons, pile up complexity and “sincerely believe that they are executing these projects at the limit of their capability and they believe they are this hard”. Read the book.
I agree with Dave a lot. I have also seen immensely large projects, which in hindsight, maybe could have been handled more effectively. And I also conclude that application-centricity is a big monster in our industry. Being from Europe, I may miss some insight of the scale of the US problems.
But I do think that there is another perspective on the over-spending and overly complex projects:
We (us, the IT folks with grey to white hair color) started from scratch and built tools, techniques and procedures on the fly. So, for some of the things: Forgive us, because we did not really know what we were doing, mostly hoping we got it right… (You may call this Frisendal’s Second Law).
When the New Became the Legacy
Let us briefly recap the Data Modeling aspects of the history of IT as a little Pixie Book.
These are some of the most important buzzwords of Data Modeling over time:
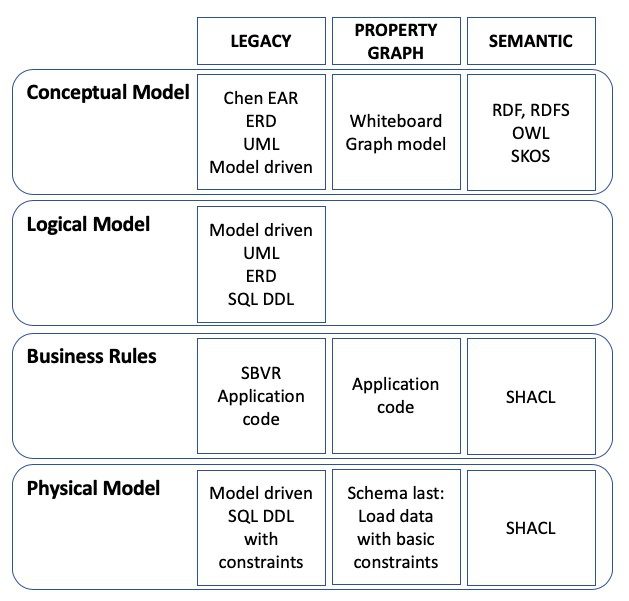
When legacy was new, we thought that the second time around was the holy grail. After networked data models came Chen’s Entity-Attribute-Relationship model, and that was good. Then relational happened and was quickly morphed into a tabular data model. Soon people started wondering about generating stuff from models, such as UML. Business rules (the grey area between data models and applications) have kept trying, and is still an option by way of using SBVR, which not too many people do.
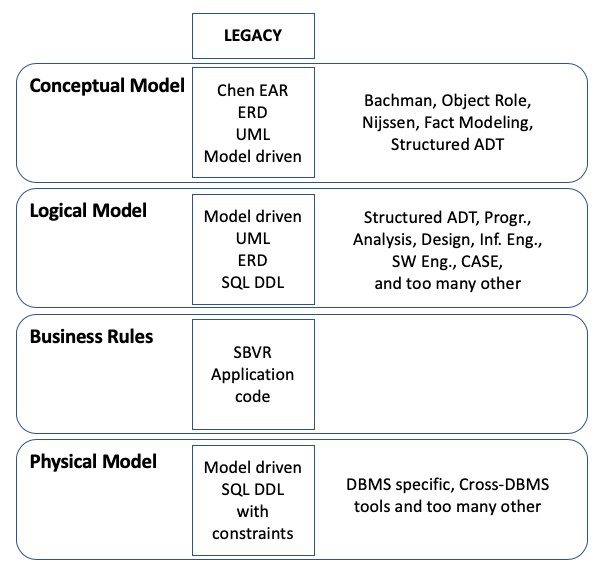
Not that we did not try other stuff, too – (bypassing OO and project management for simplicity):
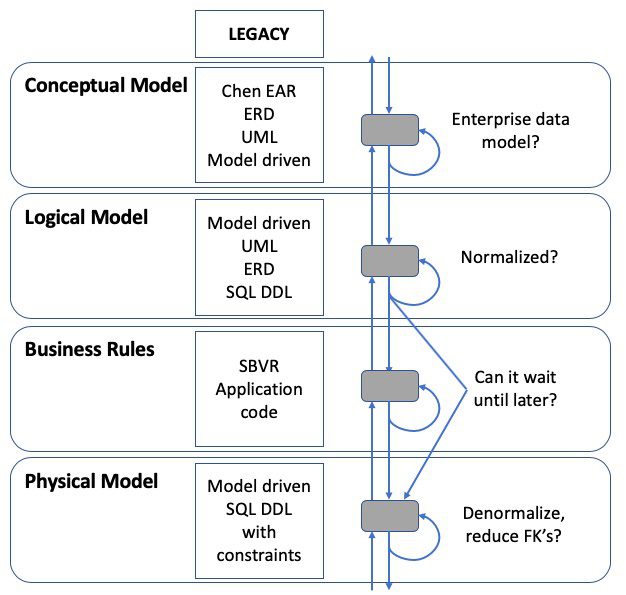
The general development flow pattern was rather complicated, which explains the exorbitant costs of large-scale waterfall development:
And many IT practitioners shrugged their shoulders and simplified the picture somewhat:
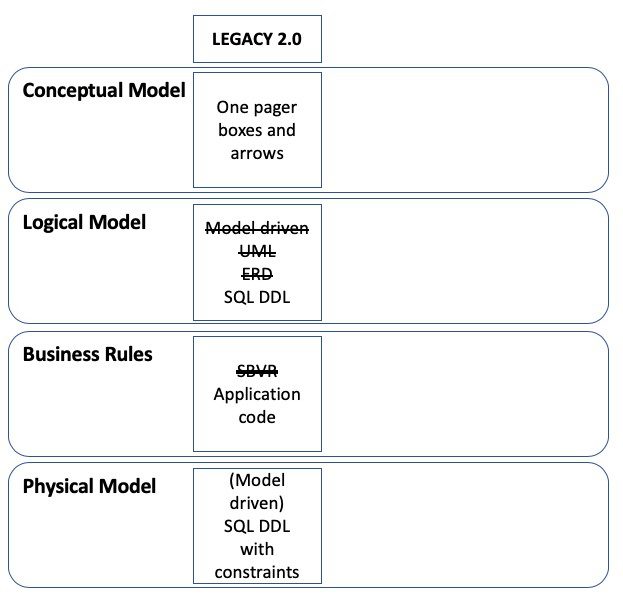
We are looking at a profession, which is still struggling to find the right tools of the trade, if you ask me.
Which Kinds of Data Modeling?
What is the role of the data model in this mesh of processes pointing in many directions?
Dave McComb actually also has a take on that. His company, Semantic Arts, comes out of the semantic technology sector (the W3C stack with OWL, RDF and XML). This community is about 20 years old and started being a “Semantic Web” project. Then it was focused on “Linked Open Data”, and today the mantra is “Knowledge Graph”. The most sophisticated representation of a semantic model is called an ontology. Dave McComb and his associates have been building ontologies for many years. I have been watching the area since around 2001.
In his experience “… an enterprise ontology is like an enterprise data model, but is typically 100 times simpler, and is far more flexible.”
And: “Received wisdom these days is that a data model is a conceptual model, a logical model, or a physical model. … This is mostly driven from the construction analogy… The need for three models is more closely tied to the state of tooling and technology decades ago, rather than what is possible now. Applications can now be built directly on top of a graph database. The graph database, when combined with the standard, SHACL, allows application builders to define minimum structure that will be enforced.”
Yes! I agree in a lot of the above, with a few moderations. Let us explore the “two-model approach (conceptual to physical)” in another Pixie book. Note that Dave McComb is talking about the heavy-duty semantic stuff (the W3C stack) as his preferred choice. Fair enough, it is the “Mercedes” of the semantic data space. He sees property graph as a step to his world. I see things slightly differently:

Property graphs also exhibit the conceptual to physical path really well. Property graphs do not enforce strict semantics, but in the real world, nothing is strictly logical. There are always logical irregularities, which are easy to handle in a property graph. But property graphs do express semantics, structure and meaning really well in simpler and more intuitive ways than the complex ontologies.
Property graph products are generally weak on constraints. Some see that as a strength because the absence of a strict schema combined with flexible ingestion schemes opens up for effective bottom-up designs.
SHACL is indeed interesting. It can be described as a constraints language. I will take a look at it in a later blogpost.
From a development process perspective a W3C-based setup is similar to a top down property graph setup:

So, who is the winner?
Investigating Semanticness
So far we have looked at legacy, property graph and semantic technologies. Here they are, aligned to each other:
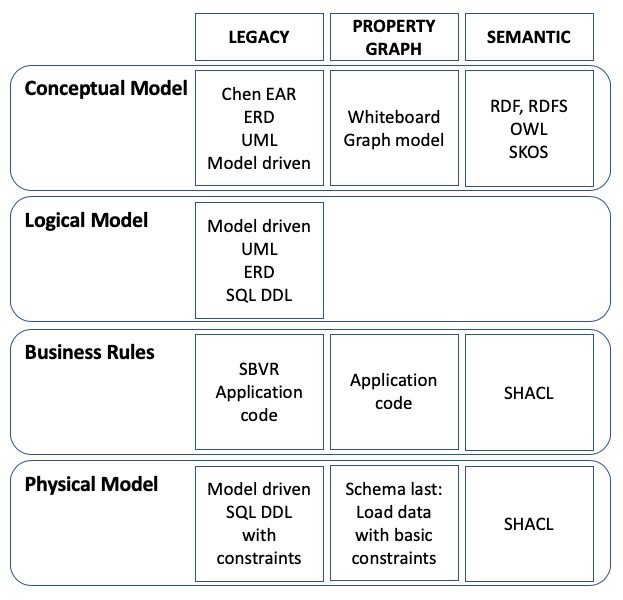
Legacy models are not very semantic. Except for Chen, which is not used that much these days. The weak point is the relationships (associations), which are, at best, secondary citizens. Relationships must be named in order to gain a good understanding of the semantics and the structure of it. Relationships in legacy crows’ feet diagrams or UML diagrams happen at the object-type / entity-type level supplemented with the business of foreign keys (SQL).
Both property graphs and RDF graphs directed graphs, and both can be modelled without “bundling properties” onto the object-types. Property graphs can also do properties on the relationships.
What has happened here? Which was first?
Actually object-role modeling, which today is mostly known as fact modeling, was first. It has roots back to the seventies. And it is still alive and popular in some parts of the world. This is a rather old style of fact diagramming, but you get the basic ideas:

Next came the W3C semantic web stack, which started around 1999 (RDF). Here is an instance diagram:

And here is a contemporary ontology diagram, just a small example:

using gra.fo, which is a commercial graph modeling tool from data.world.
What about property graphs, then? They started around 10 years ago within the then Swedish company Neo Technology (Neo4j). It quickly evolved into the labelled property graph model, which is state-of-the-art today.
The way I do Data Modeling for property graphs can be summarized in this, last Pixie book.
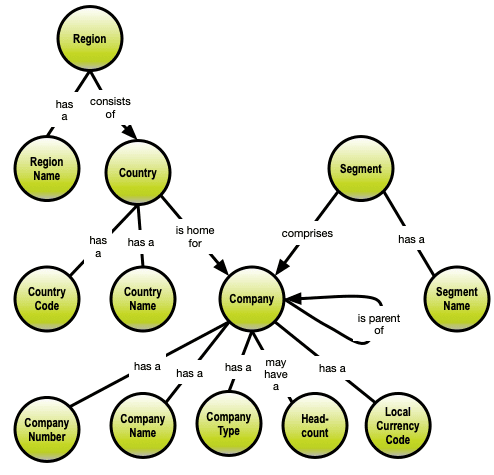
Here is a bunch of concepts:

Let us establish the relationships:

Notice that some of the relationships are described by action- / motion-oriented verbs. They are candidates for strong relationships between the node-types to be (the relationships with the arrowheads):
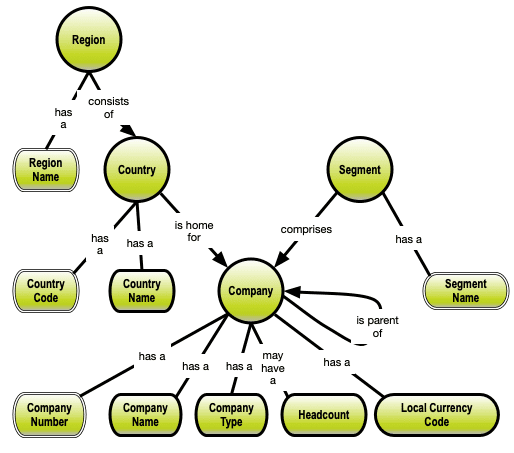
The remaining relationships are, what relational modelers call functional dependencies and they become the defining criteria for placing properties on node-types (and relationship types, if that comes in handy):
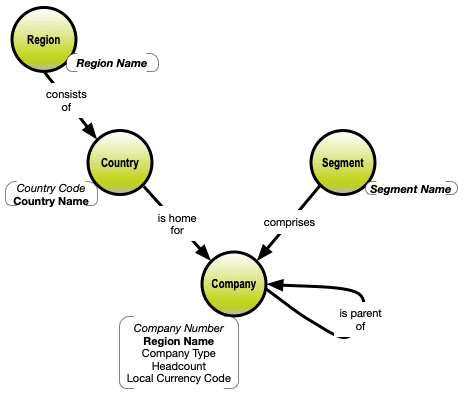
Folding the properties into the nodes, gives you this labelled property graph model:
You can learn more about graph Data Modeling for property graphs at DATAVERSITY’s Online Training Center.
Data Modeling is All About Semantics
We started out with the overview below. If we color the semantic parts green, we get this picture:
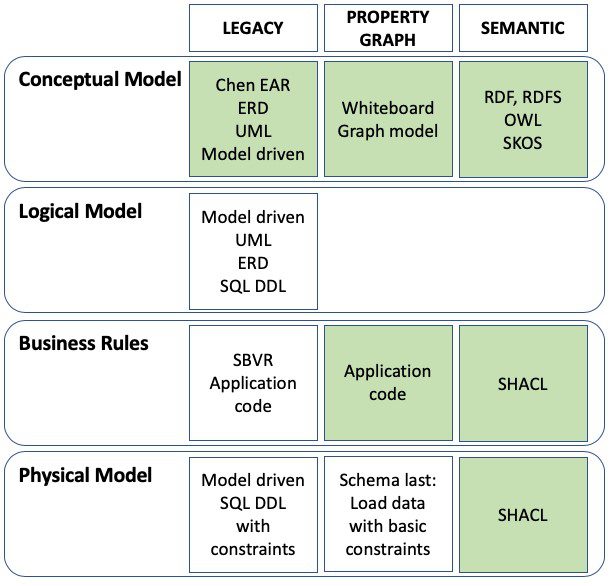
Note that legacy conceptual models are green, mostly because of Chen, and a little because of named relationships in UML.
Regardless of whether we go property graph or RDF graph, the inner structure is the same:
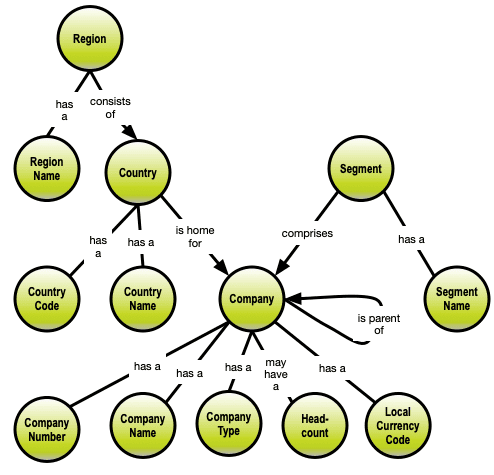
This is close to being a 6th normal form version of the data model. And this is the kernel from which everything else is derivable.
The “semanticness” varies, and the semantic models supplement each other well.
The plain concept models are indeed “semantics light”, but they carry structure and meaning well over to human recipients.
Neo4j’s Jesus Barassa has a good (albeit long) comparison of RDF with property graphs.
The RDF researcher Olaf Hartig has proposed RDF*, which brings RDF closer to property graphs (properties on relationships).
Fact models are so close to the other models that I hope the fact modeling community will do some bridging as well. Using fact models to model property graphs would be really cool.
Dave McComb recently published a comparision of property graphs vs. RDF, from his point of view. He is not wrong but I sincerely believe that we are not in a one size fits all world. Property graphs are true work horses of graph database, incl. many knowledge graphs. And concept models are just as good as whiteboards! Not everybody needs a Mercedes, and fact models carry a lot of heavy semantics in a relatively easy to understand manner.
Mix and match is also relevant. One good strategy of building a knowledge graph or some similar fabric across a set of silos (possibly including a DW), is to start with an industry standard ontology. And they are typically in the W3C sphere. So, interoperability between formal semantics and more agile architectures in property graph is certainly desirable.
The complete picture of state of the art of semantic modeling looks like this:

What a formidable toolbox for the Data Modeling trade onwards! Pick the right tool for the job!