
There are lots of numbers being thrown around about the potential of generative AI (GenAI). From trillions of dollars added to the global economy, to significant percentages of work being driven by GenAI, the big picture looks great. But turning this potential into reality is where the hard work starts.
Autonomous agents are software programs that carry out work on behalf of a user. At the simplest level, an autonomous agent leverages one or more large language models (LLMs) and wraps other services together with a text interface that can perform tasks like summarizing documents. The fact that LLMs can mimic how people think unlocks new possibilities for work that would have been difficult or impossible to implement in the past.
The Goal for Autonomous Agents
While LLMs are great at responding to user requests, they are not enough on their own to build GenAI services that differentiate a company from competitors. The real differentiation comes from domain expertise, insight into customer needs, and the ability to craft superior end user experiences. The companies that thrive as leaders in an era of commodity LLMs will be those that understand how to build engaging autonomous agents that effectively empower customers or employees.
Autonomous agents work on bigger problems than the simple ask/response chat that many of us are familiar with around GenAI. An agent can handle chained tasks that can be carried out one after another, and the agent can iterate or change goals with limited or even no human intervention based on the results. Most importantly, an agent can adapt its behavior based on complex and evolving patterns of activity.
As an example, an agent in a retail context could recognize fraudulent behavior and significantly reduce false positive results. This would ensure that the service could detect and prevent fraud in real-time and prevent false positive results for real transactions, by deciding which actions to execute. The end result of this is savings in both time and money related to preventing fraud.
How To Build Autonomous Agents
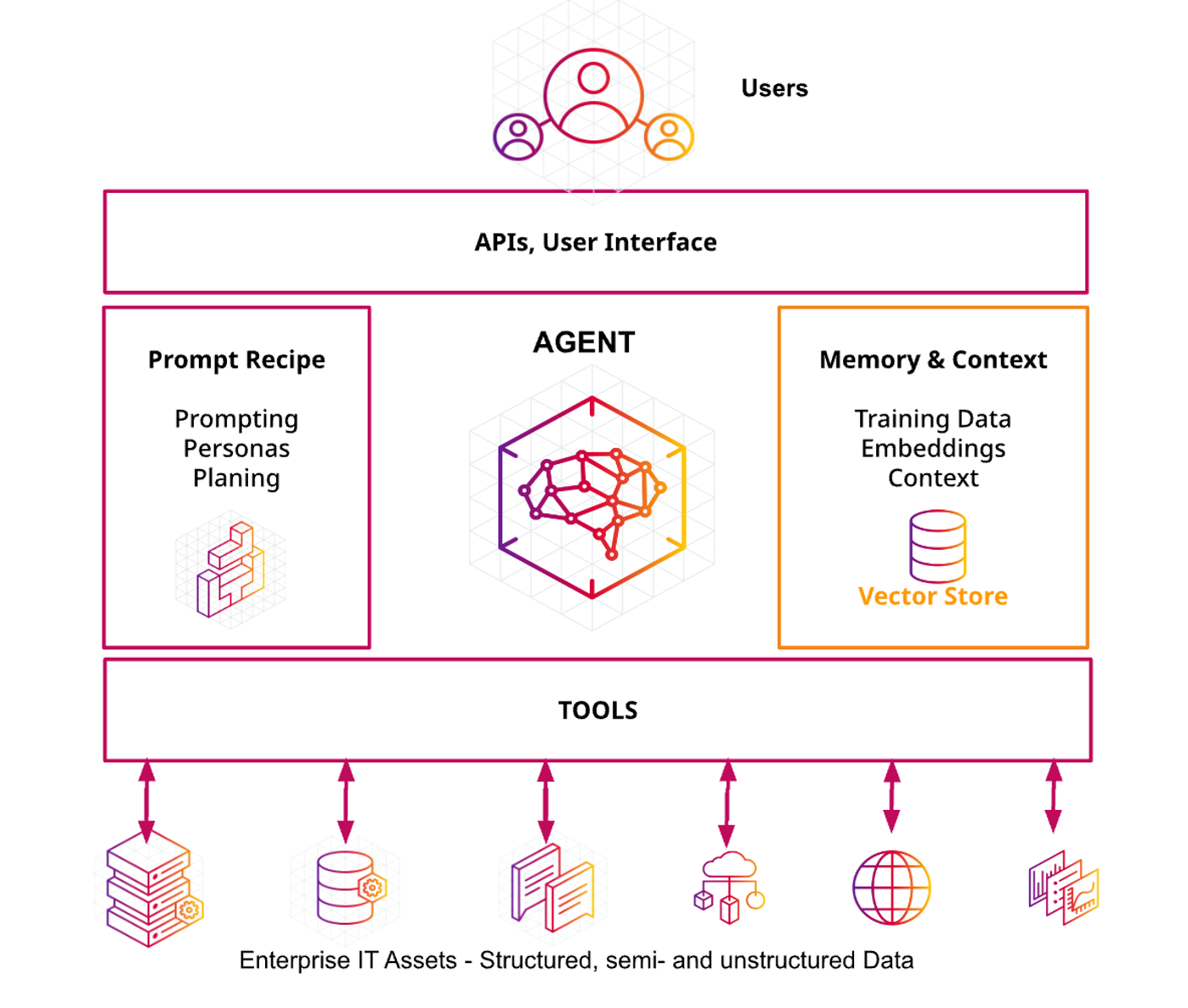
From a technology perspective, there are five elements that go into autonomous agent designs: the agent itself, for processing; tools, for interaction; prompt recipes, for prompting and planning; memory and context, for training and storing data; and APIs / user interfaces, for interaction.
The agent at the center of this infrastructure leverages one or more LLMs and the integrations with other services. You can build this integration framework yourself, or you can bring in one of the existing orchestration frameworks that have been created, such as LangChain or LlamaIndex. The framework should provide the low-level foundational model APIs that your service will support. It connects your agent to the resources that you will use as part of your overall agent, including everything from existing databases and external APIs, to other elements over time. It also has to take into account what use cases you intend to deliver with your agent, from chatbots to more complex autonomous tasks.
Existing orchestration frameworks can take care of a lot of the heavy lifting involved in managing LLMs, which makes it much easier and faster to build applications or services that use GenAI. For example, LangChain provides a popular open-source framework to build applications around LLMs by standardizing connections to other elements like prompt management, vector data stores, and other tools. Developers can build applications by chaining calls to LLMs with other tools, rather than having to develop and support each integration themselves, from scratch.
Integrating Your Tooling for GenAI
On the tools side, agents should not be limited to interacting only with LLMs. Instead, agents should be built to take advantage of other sets of data or applications. On the application side, this can range from a simple calculator to invoking an API for an external service or internal backend application. This integration with external services, like Google’s search API, can make adding more information to a response easy.
For example, OpenAI’s ChatGPT was trained using data up to March 2023, so any question from a user who asks for data after that point will not get a good response. Either the service would reply to say it does not have the right data to respond – or worse, it could create false information, known as a hallucination. Integrating a search request into the AI agent allows you to carry out a search request, then provide that information back to the LLM for it to be included in the response.
To implement this, we have to define the tool that will access the search API. Alongside this, we have to define a prompt template that will recognize the request, access the tool, and then load the response. For example, a search prompt template would tell the AI agent that triggering the search API is “useful for when you need to answer questions about current events.” Once this is put together, we can use the agent with Google search access to get answers that are relevant to requests that include current factual data, like, “How many people live in Canada as of today?”
This example shows that a GenAI system should understand that it needs to use “search” to get access to the “current” data, then execute the action using the “search” tool, and then share the observation back to the user. Alongside simple online searches using public data, AI agents can access internal enterprise data sources from operational data stores or vector stores. Using this company data can improve the accuracy of responses using retrieval augmented generation, or RAG.
When you want to add more specific domain context around your products or the industry in which your organization works, using an LLM on its own is not enough. However, you do not have to train your own model in order to address this gap. Instead, you can use RAG or add fine tuning to the model based on your domain context.
Combining these approaches – fine tuning and RAG – can provide better quality responses to users. Using RAG is also beneficial when you have strong data privacy requirements to meet and you do not want to store your company IP or customer PII in your LLM models.
Adding More Data to Your GenAI Service
Injecting data via RAG is the most efficient way to provide context information to your generative AI system that was not present in the model’s training data set. This is especially useful in cases when you have data that updates regularly and your users will want more recent data in their responses. This data for fine-tuning and RAG comes from your existing data sets, such as your databases, customer relationship management, enterprise resource planning, and knowledge management systems. However, it can also come from less structured sources like mail conversations, speech recordings of service calls, videos, images, and more.
To manage this data, AI agents will require a storage layer for their short-term and long-term memory. As AI agents are stateless, the short-term memory keeps a record of a conversation and uses that data to generate further responses. This acts like a memory stream with a large number of observations that are relevant to the agent’s current situation, including a log of previous questions and responses. One approach to efficiently support this is to use vector search to support retrieval. This also allows you to manage the history that is used as memory for the agent, have full control over the data lifecycle, and define any permissions or security rules.
How Autonomous Agents Build on GenAI
To build autonomous agents, we need to mimic human thinking patterns and proactively plan for task execution. During planning, you can create LLM agents and break down large and complex tasks into smaller, manageable steps. These agents have to be capable of learning from their past actions and tracking successful results against mistakes. This data helps the overarching autonomous agent to optimize its future steps and improve final results.

To create an autonomous agent for the user, you will implement a complex system of different agents that work together. At the start, you will have an observer agent that takes in information or requests, then adds relevant context to the request, and then either pushes this request to its memory or task store. Tasks are then pushed to execution agents that carry out the specific task required and create the response or action that the user wants.
Alongside this, you will have other agents that carry out additional tasks. To continue with the previously used fraud detection example: The observer agent looks at credit card transaction data and decides whether to send the task to an execution agent, an observer agent, or other agents that might interact with the transaction. While a single credit card transaction on its own doesn’t mean a lot, the same card being used twice within a short time in different locations hundreds of miles apart could be an example of fraud.
For the first transaction, the agent might store it in memory. However, when the same card gets used again so quickly, the agent would create a task to analyze the transaction for fraud based on the context of the first event. This is where a prioritization agent would be triggered to analyze the task and decide either to trigger an execution agent for fraud response or to send the transaction to be processed as normal.
The fraud response execution agent is only responsible for analyzing transactions for fraud. It can access more context data like historical transaction and credit card usage behavior using retrieval augmented generation and external services like Google Maps API to understand travel and distance information for the places the cards were used. It could even interact with the customer via an app, text message, or call to assist in the analysis.
Based on these interactions, the service can decide on how to respond effectively based on the context of data around these transactions. Autonomous agents use multiple components to create the final response that the user wants to see, or that the business will use to create value for its operations. This is exciting, because it does not revolve around a static process and workflow that has to be defined again and again as new services are built. Instead, the service can react to and use new services as they are developed.
How Autonomous Agents Compare to Previous Approaches
To achieve an automated response to a user request in the past, you might have leveraged a process execution engine that would work through a set of predefined steps for you. However, this approach would have required explicit models that defined the different steps required from beginning to end. This approach was more inflexible, as the system was complex to implement and would need to be updated any time there was a change. Any incident that fell outside the expected parameters would then need to be handled separately, and the model would need to be updated to reflect that new behavior.
Autonomous agents are able to handle more complex environments and use contextual data to respond to new experiences and patterns. Rather than needing specific manual updates to the model, the agent can use the tools it has available to get more relevant and real-time data. The problems may still be hard, but agents can make working on them easier and more accessible.
LLMs have huge potential for applications, but they are not the only components that are needed within generative AI services like autonomous agents. These agents use a combination of LLMs and other tools to unlock more advanced capabilities, from basic tasks like document summaries to complex “agent orchestrations” that mimic human work. As these agents are put together, they can create more value for businesses and satisfy customer demands. For developers, combining LLMs and data with other tools and services will require more integration, but it will provide the opportunity to build more innovative applications and collaborate with business teams.

