Click to learn more about author John Singer.
IT Metadata Management – that quirky corner of IT recognized as a “critical success factor” yet the most under-funded aspect of any initiative. Historically, each new wave of IT technical innovation brings with it a call for better Metadata Management. The new innovation disrupts the current status quo with respect to IT operational readiness – in other words, we can’t manage what we don’t understand.
So what is this age’s disruptive force crashing down on the IT landscape, upsetting our five 9’s and generally challenging IT operational efficiency? Why of course it’s BIG DATA and the Internet Of Things (IOT). After all, how are you going to keep that Data Lake from turning into a data sewer? (hint – you must manage the metadata). The term metadata means many things to many people, “IT Metadata” refers to the repositories maintained by Data Architecture (data assets), Enterprise Architecture (business process, service models, architectural blueprints) and ITIL CMDB’s (IT system components). For today’s systems however, metadata can no longer be managed as an after the fact artifact of systems development.
It must be part and parcel of the overall business solution. A new approach known as “Knowledge Maps” combines traditional IT Metadata Management ideas with newer technology and applies them to any business problem. See my previous posts on Knowledge Maps: Knowledge Maps – What is the Problem We are Trying to Solve? And Knowledge Maps – Connecting the Dots to get a more defined understanding of Knowledge Maps.
Today’s Approach Using Relational Database
Traditional Metadata Management and CMDB tools use relational databases to store their data. This requires a relational design that falls into one of two categories:
- Domain Specific Model: In this case, the world being managed is modeled using traditional entity relationship modeling techniques (i.e. normalization) resulting in a table for every entity type needed. In other words, the database design directly matches the real world and will probably have hundreds of tables. The advantage of having all the data directly represented by appropriate table and column name is quickly over-run by the cost of maintaining the schema and the queries.
- Generic Abstract Model: The abstract model provides a physical schema that will store information about any entity type. The model below illustrates such an approach.
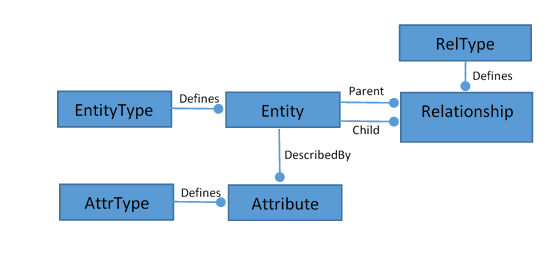
The entity table has a row for every “object” in the system and is defined by the EntityType. Each entity can have as many attributes as desired defined by an attribute type (AttrType). Finally, any parent/child relationship between two entities can be defined in the Relationship table with each relationship defined by the RelType entity.
Perfect – the generic abstract model solves the complexity problem of the domain model and allows the user to manage data for any set of entities and their relationships with no schema changes needed (one does have to predefine the entity, attribute, and relationship “types” before using them but that is pretty trivial). This approach works and is the basis of every traditional Metadata Management and ITIL CMDB (configuration management database) tool.
The problems start when you begin developing queries against this database. This can be quickly summarized as “too many self joins”:
- Long chains of relationships require joining the Relationship table to itself many times. Each one of these joins requires a join back to the Entity table and the EntityType table to verify only valid entity types are being selected. While you can tune this structure and the queries for good performance, eventually you will hit a wall.
- Each attribute is another join. This only compounds the too many joins issue.
- It is not uncommon to have more than one path through the relationships to connect two different entity types together. Each different relationship path must be written as a different select statement with the results union’ed together.
Finally – there are query types that are simply not possible with SQL. If you can’t predict the number of “hops” between two different entities in the database then you can’t write an SQL statement to do the joins. Imagine a metadata system that tracks data lineage in a complex OLTP/ETL/DW environment. For every data element in the Data Warehouse, the system tracks the number of systems it flows through to get there. The problem is you don’t know how many “hops” the data element took, so how do you query the generic structure to find the originating system (each hop requires a join)?
Graph Database Provides the Solution
Knowledge Maps are built on graph databases. More specifically a form of graph database called the “property graph”. A property graph database stores data in two fundamental structures – the node and the relationship. Neo4j is an example of a property graph database and will be used for examples in this article (other property graph databases may work differently). A Node is a unit of data storage and can contain properties (much the same way a row in a relational database has columns) and are depicted using bubbles:

The node above represents a “Person” with an attribute called “Name” equal to “John”. In Neo4j the “Person” value is called a label and is used to denote the type of node (think object class or entity type). A node can have any mix of labels and attributes or none at all. The node structure is “schema-less”, but what that really means is the node structure does not have to be defined ahead of time (as opposed to a relational DBMS where the table must be defined before data can be inserted).
Relationships connect two nodes together with direction meaning the relationship “goes” from the starting node to the ending node. A relationship cannot exist without two nodes to connect together. A Relationship must have a name which identifies the type of relationship and may contain properties as well, just like a Node. Relationships are shown as arrows between two Nodes:

Now we have two “Person” nodes (John and Bob) and a relationship between them called “knows” representing the fact that “John knows Bob”. Can it be said that “Bob knows John”? Relationships are directed, i.e. they have a start node and an end node, but there is no ability to define additional semantics such the relationship being transitive (i.e. if John knows Bob then Bob knows John). Relationships are “schema-less” (like Nodes) in that you can define relationship names and properties at runtime. Finally, nodes can be connected together by relationships in an endless chain as shown below:
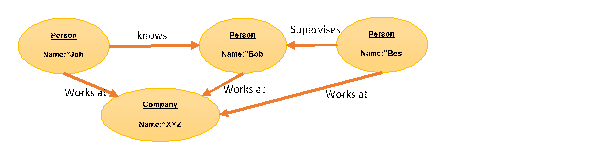
While this is a very basic explanation of the property graph model it illustrates several important advantages over traditional RDBMS solutions for Metadata Repositories.
- The “schema” is defined at run-time. You can add new node and relationship types or new properties at runtime without any prior schema changes. Traditional Metadata Management tools need to define generic table structures (see above) to allow you to model any type of data object. With the graph model, the data objects are represented directly with node labels and relationship names.
- Relationships are now first class citizens. The importance of this cannot be overstated. Each relationship is stored directly in the database which means:
- Relationships can be queried directly by name (how many friends are in the system?)
- Relationships can be counted (how many friends does XYZ have?)
- Nodes can be filtered by the types of relationships they have or don’t have (find people with no friends)
- “Distance” can be calculated (how many friend of a friend relationships are between person A and person B?)
- Relationships can have their own properties (when did A become a friend of B?)
- The combination of two nodes and a relationship can represent a “fact” in the simple form of subject-predicate-object. So in the graph above we can state the fact that “Bob works at XYZ Corp” and the fact that “Boss supervises Bob”. In the first fact Bob is the subject but in the second fact Bob is the object. This ability to chain fact statements together indefinitely creates a powerful ability to merge data from many systems into one query-able structure – the Knowledge Map. These simple fact statements are referred to as “triples” in the RDF semantic web world.
The graph model is a better way of representing IT Metadata. It more closely aligns with the typical metadata query use cases (impact analysis, where used, data lineage). It enables queries that would be tortuous if not impossible in relational systems. All metadata and ITIL CMDB vendors will be migrating to this model in their next generation tools.