Click to learn more about author Thomas Frisendal.
Many of us have a lot to do. And we have short delivery cycles, sprints, and a lot of peers to share data models with. In search of something lightweight, which is quick and easy, and may be produced (or consumed) by other programs?
Stay with us on a short, but inspiring, sprint through just such a tool.
It is open source, it is based on a GPL (GNU) license or also LGPL, Apache, Eclipse, and MIT. There is a free online server, and/or you can download and install to your happenstance operating system. (If you need to do large diagrams, do it offline.)
The name is PlantUML. But do not let that mislead you. You can use it without thinking in UML Class diagrams. Phew! It supports a lot of UML: Sequence, Usecase, Class, Object, Activity, Component, Deployment, State, and Timing. And it also does: JSON data (yes!), YAML data (yes), Network diagram (nwdiag), Wireframe, Archimate diagram, SDL, Ditaa, Gantt, MindMap, WBS, AsciiMath and JLaTecMath and IE/ER, and more … most of it is intuitively easy.
Freestyling in the Data Model Reality of Today
Instead of following a specific data model diagram paradigm, you can also “freestyle” and piggyback and mix/match from across the board, including formatting, HTML markup, and more. I do exactly that (freestyling) and that is what I am going to show you – based on real-life experiences from real-life use cases.
Your models are stored as simple text files rather than in a proprietary repository. Numerous integrations exist, and Git works fine together with PlantUML.
Designing a Shopping Cart Data Model
Imagine a very simple shopping cart application on a webshop. Concept-model-wise, it looks something like this:
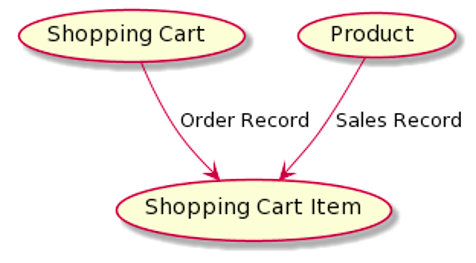
The input source of your concept model looks like this:

That’s it! I took the generated diagram and saved it as PNG file. Really nice and simple. But you also will get a generated HTML invocation, which in this case is this.
Go to the PlantUML online server, paste the http-command above into the field between the input and the result, and you will get the input back again (plus the diagram). The input is encrypted in the URL!
Verbose Concept Models
OK, now we have a concept model. At this stage you might want to be more verbose. In a brainstorming session, possibly. So you could consider this piggybacking of the “Usecase” pattern:
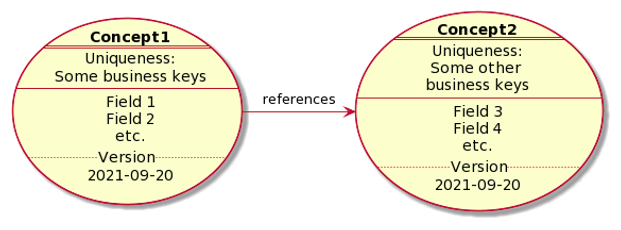
The input, which gives you the above, looks like this:

Adding Properties to the Concept Model
Which additional concepts contribute to the conceptual narrative about this context? Well:
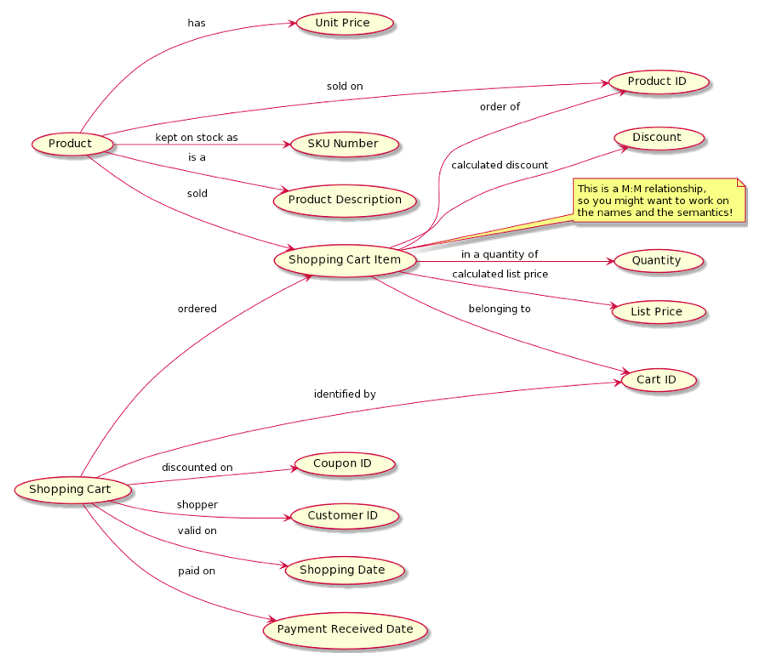
And the input looks like this (note the note):

Doing the Data Model
Once you have understood the full semantics (of the functional dependencies, by looking at them), you can do your data model. We will “clone” the object diagram type of PlantUML for this.
Unsurprisingly, it looks like this (with a nice diagram title box added to it):
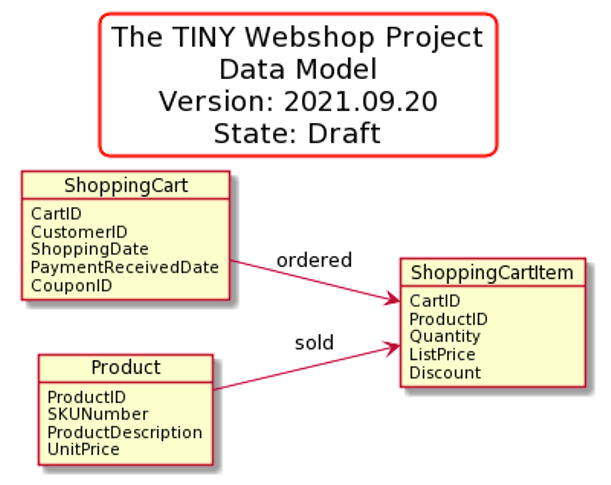
The input for that looks like this:

Useable stuff and fast to produce – and they read nicely. But, you might say, all you have done is drawing data model diagrams! Yes, can we anything to automate even more?
Automation of Data Model Generation
Many “data models” in spe reside in some tabular form. And there is only one thing more tabular than SQL: Excel! Copy/pasting table content into Excel is very, very easy.
Assuming you have a tabular representation of the types in your data model, here is all it takes to generate input that you can copy and paste into PlantUML:
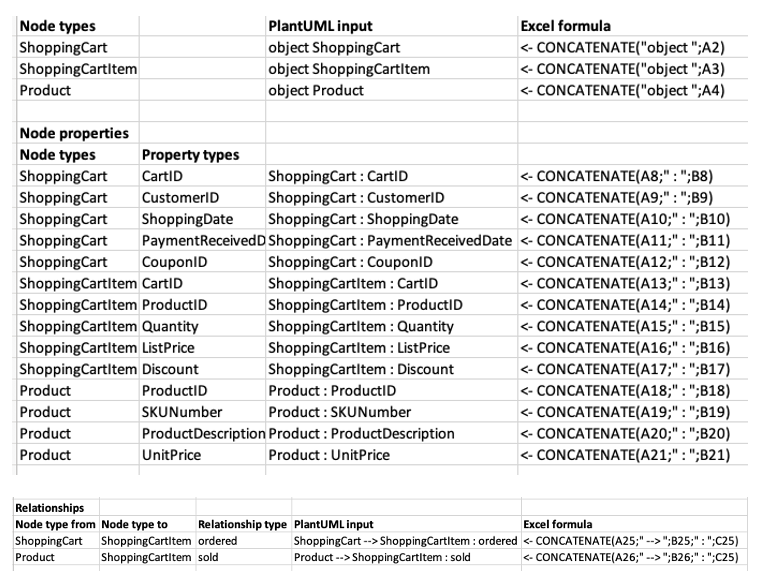
What then about the worst usecase of all – the schema-less production database, which needs to be refactored? No DDL exists, so what?
Reengineering a “Schema-less” Neo4j Database
As of today Neo4j does not contain a DDL-style schema, but there are ways. We are going to use the Excel approach described just above, but we need to generate the Excel sheet. And for that, we can use a few Cypher commands (if your database is not too large).
Getting the list of nodetypes can be done with this query:

Export the result as a CSV file, and you have the first part of the target Excel sheet.
Going after the (node) properties can be done like this:

The result is a list of the nodetypes with their properties. Export the result as a CSV file, and you have the second part of the target Excel sheet.
Next, for the relationships, we can do a cypher query like this:

That will give you a table of the relationships with from and to labels as well as the relationship names. Export the result as a CSV file, and you have the third part of the target Excel sheet.
Now you can consolidate in the Excel sheet and generate a PlantUML data model representation.
Generating a Schema from the Data Model?
I would say that having the data model in a tabular representation will open the doors to many SQL RDBMS’s tools for DDL creation or direct table creation. If your database does not support such DDL transformations, try creating the DDL commands from your tabular representations – not that difficult once you learn to use Excel as a text transformation tool.
For Neo4j the situation is a bit worse. As said, Neo4j as of today has no DDL. But you could do what the Neo4j Arrows tool does for forward engineering: Generate Cypher or LOAD CSV templates and populate the database that way. You don’t really need much more than what is in the tabular representations, which I described in Excel above. (Neo4j is forgiving about missing datatype specifications.)
Simple, Text-File-Based Data Modeling?
Is this really a way forward?
You will find that PlantUML is full of few, but nice, surprises. There are almost no limits to how you can design and format your diagram, integrate with other open-source tools, etc. The only thing I am not going to reuse in any context is crows feet. That is a solemn promise!
Text files can be useful, also for the data modeler, including the occasional ones. They are not an integrated thing like one of the big data modeling tools. But text files are handled really well in Github and Gitlab, and they fit the development paradigms there as a hand in the glove.
And text files are handled well by data catalogs, mind you! (Aside: I also like the support for JSON and YAML in PlantUML – kind of cool!)
A big hand to the good people behind PlantUML! You have created a true Swiss army knife for Data Modeling!



