
“You must unlearn what you have learned” (Master Yoda)
The “conceptual” level of Data Modeling has been a stepchild for many years and is mostly forgotten in fast-paced delivery projects today. Since the mid-nineties the legacy toolbox basically offered software-engineering inspired diagramming tools, and they did not communicate well on the business level.
Fortunately, a few paradigms survived in devoted communities. And listen: There are now strong signals of returning emphasis on this important, business-facing analysis, design and modeling activity. First, a brief look back (PIXIE-style). Afer that, taking a dive into what is happening these days we will. Unlearning classic conceptual modeling.
And please don’t call me Yoda!
Legacy Conceptual Models
Here is a “conceptual data model” for a publishing system diagrammed in the QDesigner CASE tool around 1999:

Image Credit: Online training material by RMIT University
The diagram above could just as well be called a logical data model, but what was happening at that time was that “logical” became “table diagrams” having primary, where people then added foreign keys and indices to arrive at the physical model. Structurally there were not many differences between logical and physical – with exceptions made for denormalization.
And here is another school:

It is a very small part of the Inspire Land Cover Data Model for the EU-project called EAGLE, which was planned from 1998, and which went operational in 2008.
Yet another classic set of UML class diagrams, which is a practice that has been used in many public sector projects all over the world. But, potential readers of UML diagrams are mostly software developers and other IT specialists.
Oldies but Goodies
Quite a few paradigms and associated technologies have been around for at least similar time-frames as UML, and also continue to be used in relatively small communities.
Let’s just briefly mention the most important.
Chen’s E-R
Envisioned by Peter Chen in 1976, his Entity-Relationship diagrams continue to communicate well:
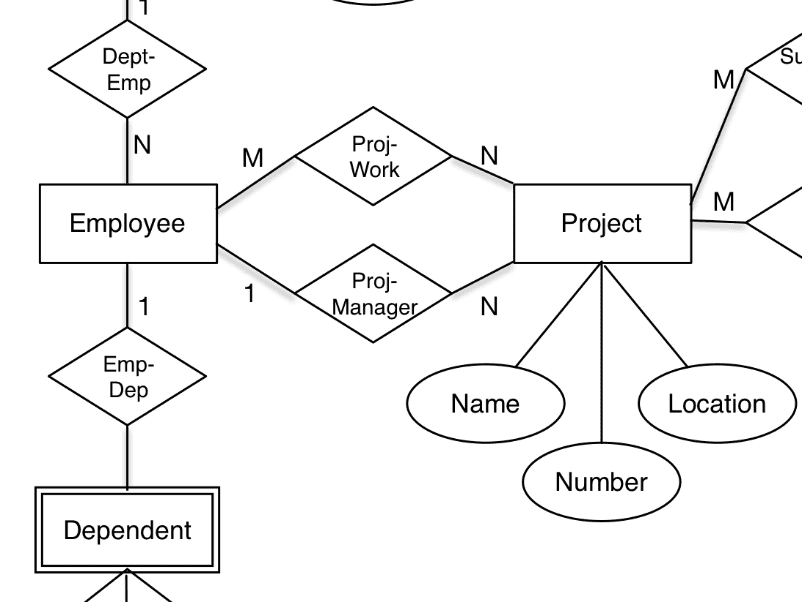
I have a strong suspicion that Chen E-R inspired the property graph inventors around 10 years ago. Without doubt, a Chen E-R model is indeed a graph. And it is also about concepts and relationships.
Binary Relationship Models, ORM, and Fact Modeling
Peter Chen was not the only one thinking about relationships as binary constructs between concepts. People like Eckhard Falkenberg, Sjir Nijssen and Bracchi et al worked on “Binary Relationship Models” in the seventies. I believe that Sjir Nijssen even had an implementation running on CDC computers back then (in Brussels).
A branch of this work was continued by Terry Halpin, and led to the “Object-Role Model”, which looks like this:

Terry Halpin worked for Microsoft for a period and ORM made it’s way into Microsoft Visio, and was quite popular there for some years.
Sjir Nijssen also continued his work developing NIAM (“Natural language Information Analysis Methodology”). Today this, via “Fact Modeling” has developed into “Fully Communication Oriented Information Modeling”, of which you have an example here:

In essence, FCO-IM is a combination of semantics, binary relationships and specialized graph visualization (cf. above). It is a very powerful toolbox, the only restriction that I have is that it is not something you learn in an afternoon.
“Knowledge Graphs” aka Linked Open Data aka Semantic Web
Talking about semantics: Another long-timer is the semantic community, which has strongholds in complex businesses such as government and public administration, healthcare, R&D and somewhat in finance. It started out as part of the Internet revolution driven from CERN in the late nineties. Based on the XML standard, standards like RDF (Resource Definition Framework) etc. emerged in 1999 as vehicles for connecting websites together in a searchable mesh. (Also a graph). Here is an example of a graph representation of (parts of) the Internet Movie Database:

The distance to binary relationship thinking almost non-existent.
Concept Mapping for Data Models
Shortly after I learned about RDF, I discovered concept mapping and the tool CmapTools. I started using it in brainstorming sessions when designing data models for data warehouses. It went extremely well and in 2012 I wrote a book about it – you can find it on Amazon.
Concept mapping comes from learning psychology and has been proven to be a tool well suited by students as well as business people (look up researchers like Moon, Hoffman, Novak, Canas, and yours truly). It deals with people, language and meaning, not engineering. Learning from the business what the business is doing, and where it wants to go is a people issue. It involves brainstorming workshops, mapping the language of the business and getting the meanings right. See for yourself in this early stage data model:

The diagram is a concept map, and it really speaks for itself, which is the whole idea. Notice that you can read little sentences like “Customer issues Booking” and “Car Group has a Rate” and so forth. The sentences are visual, they are the connecting lines between the concepts. Concept maps can be drawn easily in brainstorming style workshops and they are easy to maintain, also for non-technical users. Subsequently you refine them into business objects, properties and relationships.
Common Ingredients
Across the Board, there are some common ingredients:
- Concepts
- Properties
- Relationships
- The Triple (subject – predicate – object)
- Occasional elements of semantic sugar such as cardinalities, class systems and various other abstractions.
The terminology varies quite a lot, but the basics are the same. The graphy nature of data models manages to shine through.
More Recent Developments
Concept Models, SBVR
In the Business Rules community people had been using earlier versions of fact modeling for quite some time (based on Sjur Nijssens NIAM approach). That included a structured English in a variety called RuleSpeak.
The Object Management Group (OMG) had in 2008 published the SBVR (Semantics of Business Vocabulary and Business Rules) standard. It was essentially the Rulespeak approach. Version 1.2 of SBVR was published in 2013 and included a visual representation of “Concept Models”. The newesrt version of that can be seen here. Here is an early version based on “ConceptSpeak”:
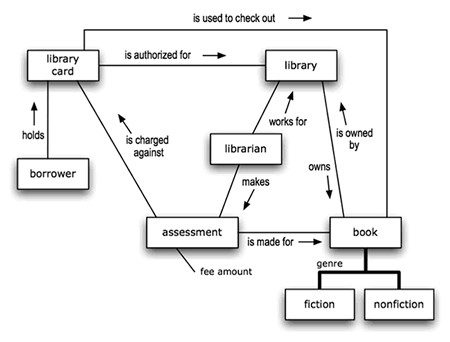
Diagram is borrowed from Ron Ross’ 4th edition of his book, Business Rule Concepts, and it was used in the Business Rules Journal in 2013 in an article by yours truly
It is actually interesting to see the evolution from conceptual to concepts in the business rules community. They were leading the way of moving Data Modeling forward. Thanks, Ron Ross.
Ron recently published a 2nd edition of his latest book Business Knowledge Blueprints – Enabling Your Data to Speak the Language of the Business – About Vocabulary & Concept Models. See more here. I am sure that many data modelers can find good inspiration in it. Fact Modeling meets Semantics meet Concept Models. The crossover between business rules and data models is good for us!
The Business Term Model
Interestingly enough, Data Modeling Rockstar Steve Hoberman recently published a practical and non-technical guide to handling “Common Business Language” across different use cases and technologies. This happens in his book titled The Rosedata Stone – Achieving a Common Business Language using the Business Terms Model. The Rosetta Stone is an antique artefact (stele), which has a text written out in 3 versions: Hieroglyphs, ancient Egyptian (Demotic) and ancient Greek.

By Ptolemy V Epiphanes – The website of the European Space Agency (ESA) [1], Public Domain, https://commons.wikimedia.org/w/index.php?curid=2819693
I completely agree with the need for a “Common Business Language”, and that was indeed the major concept of the Conceptual Model in the early days. Steve’s book covers both process and content is written for both business folks and analysts/modelers. About time, I would say, that this important exploratory phase of business development is confronted with the reality of today.
It is also good to be reminded of (by Steve) of William Kent’s 1978 book called Data and Reality. It is still highly relevant.
Steve’s new book has a lot of sound advice for the tasks necessary to build a Business Term Model, and it is worth reading for that reason. It also reminds me of Malcom Chisholm’s must-read book “Definitions in Information Management” (2010).
It also reminds me of my own book from 2012: Design Thinking Business Analysis – Business Concept Mapping Applied. The emphasis of using the process of establishing a Business Term Model for understanding semantics, clarifying it and mapping it to different contexts is vital to the success of the whole thing.
Oh, one more thing: Very similar to the SBVR (Semantics of Business Vocabulary and Business Rules), standard from OMG, structured language can be used to represent the model, like this: Each Supplier may receive many Purchase Orders, Each Purchase Order must be received by one
Supplier, etc. The bold terms signify Concepts (the term is used by SBVR and also by yours truly).
This is where semantics and Data Modeling are on level terms, for good reasons. Basically, it is triples (assertions) with cardinalities, subtypes and some other details, and you are good to go.
Steve also favors visual representations. And he defaults to using a combination of simple E-R (the original Chen scope) combined with crows’ feet from the more technical, software engineering ER approaches. If you, like me, feel that it can be done better than that, Steve points you in the directions of Fact Modeling (FCO-IM, the Casetalk way) and Hackolade, which can do a “document” style representation as well as a property graph representation of the very same business term model.
Alas, The Rosedata Stone is a very timely book for everybody moving around in the difficult zones between business and technology. It precisely expresses the growing consensus that the level of consideration previously called conceptual modeling is highly relevant today, also if you want fast time to delivery. The major reasons for such new opportunities are simplification (simply concepts, not a conceptual stance), thinking about semantics a lot more and using NoSQL (documents and/or graphs) paradigms, where appropriate.
Highly recommended!
Futures
There is another modeling book on its’ way: Semantic Modeling for Data by Panos Alexopoulos. It is planned for release in November 2020.
I have had the privilege of doing an early review. And it is a very important book in my opinion. Panos really covers most of the ground of modeling concerns and he really means “for Data”. The book will sort of close the gap between old school semantics and old school Data Modeling. It will apply to graph data models and also to other contexts. Also a very timely book.
You can see an early release here (login required).
Graph Query Language Standard
Finally, there are lots of things happening with the creation of the new standard for a graph query language, GQL. I participate in the work being the Danish expert to the ISO IEC/JTC1/SC32/WG3 committee. As some will now, this is the renowned SQL-committee, so graph Data Modeling meets SQL Data Modeling. And I sincerely hope that GQL over time also can federate not only graph and SQL, but also the semantic graph standards and the property graph languages. I will do my best.
Concepts are the Way Forward
The conclusion is that concepts is the unifying thing that, as you have seen above, makes data models more and more similar. Concepts, properties, relationships and graph representations.
So: Through the Concept Force You will see. Other places. The future … the past. Return of the Concepts it is.
You may call me Yoda now!