
This article provides a brief explanation of the SVM classification method of analytics.
What Is SVM Classification Analysis?
SVM classification is based on the idea of finding a hyperplane that best divides a dataset into predefined classes. The goal is to choose a hyperplane with the greatest possible margin between the hyperplane and any point within the training set, giving a greater chance of new data being classified correctly.
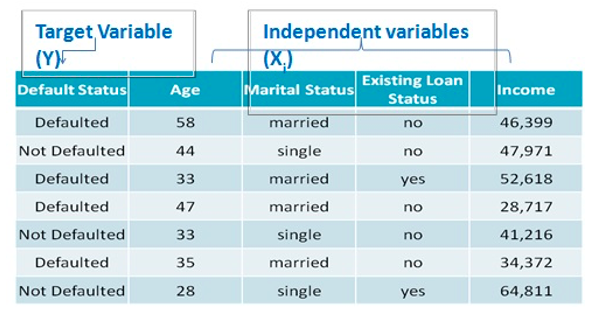
To explore this technique further, let’s conduct the SVM classification using the following variables:
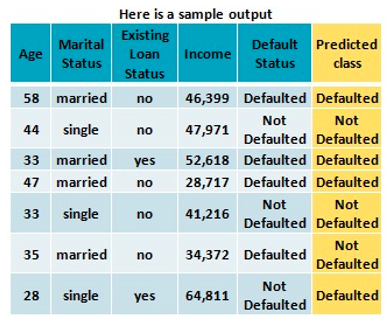
Here we see a sample output for the actual versus predicted outcome.
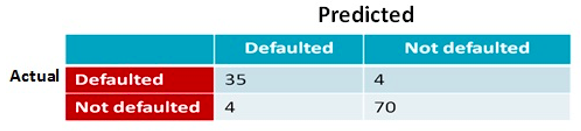
Classification Accuracy (35+ 70) / (35+70+4+4) = 92%. The prediction accuracy is useful criterion for assessing the model performance. Model with prediction accuracy >= 70% is useful.
Classification Error = 100- Accuracy = 8%. There is 8% chance of error in classification.
SVM Classification Analysis can be used for many analytical tasks:
- Credit/Loan Approval Analysis – Given a list of client transactional attributes, a business can predict whether a client will default on a loan.
- Medical Diagnosis – Given a list of symptoms, a doctor can predict if a patient has a particular disease.
- Weather Forecasting – Based on temperature, humidity, pressure etc., the organization can predict precipitation.
- Treatment Effectiveness Analysis – Based on the body attributes of a patient (e.g., blood pressure, blood sugar, hemoglobin, prescription medication, and previous treatment methods), a doctor can determine the likelihood of treatment success.
- Fraud Analysis – Based on various bills submitted for employee reimbursement for food, travel, medical expenses etc., the organization can predict the likelihood of an employee submitting fraudulent expenses.
How Can SVM Classification Analysis Benefit Business Analytics?
Let’s examine two business use cases where SVM classification can benefit the organization.
Use Case No. 1
Business Problem: A bank loan officer wants to predict if the loan applicant will default on a loan, based on attributes such as loan amount, monthly payment installments, employment tenure, number of times delinquent, annual income, debt to income ratio, etc. The target variable would be “past default status” and the predicted class would contain values “yes or no” representing “whether the applicant is likely to default/unlikely to default.”
Business Benefit: Once classes are assigned, the bank will have a loan applicant dataset with each applicant labeled as “likely/unlikely to default.” Based on these labels, the bank can easily make a decision on whether to give loan to an applicant and how much credit to extend, as well as the interest rate each applicant is eligible for based on the amount of risk involved.
Use Case No. 2
Business Problem: A doctor wants to predict the likelihood of successful treatment of a patient illness based on various attributes such as blood pressure, hemoglobin level, blood sugar, prescription medications, and current and previous treatments. The target variable would be “past cure status” and predicted class would contain values “yes or no” meaning “prone to cure/not prone to cure,” respectively.
Business Benefit: Given the patient profile, and current and previous treatments and medications, the doctor can establish a probability of success and make changes in treatments/medications.
SVM classification analysis can help organizations to predict outcomes, based on attributes and variables in the profile of a customer, a patient, a product, or other subjects or targets that are crucial to enterprise success.