Click to learn more about author Will Ochandarena.
The conversation about IoT and edge processing traditionally centers around remote operations, like oil rigs, factories, mines, and farms. This isn’t just because drones are fun to write about; it’s because these environments are the most likely to have all of the ingredients needed to be an interesting edge processing use case. First, they produce a vast amount of data, not only from traditional sensors, like temperature, pressure, and humidity, but also from new uber-sensors, like video. Next, the network connectivity in these environments isn’t sufficient to send all of the collected data to a central site. Last, and most importantly, these environments benefit from taking action based on data in the moment, like giving a machine a break before it fails or optimizing the path of a drill. Combined, these factors necessitate local computing resources that run Machine Learning models to make sense of the data being created in the moment, tightly coupled with local applications that can take appropriate actions.
However, far-flung operations aren’t the only situations that combine a data imbalance with time sensitivity. Imagine a financial institution data center with tens of thousands of servers divided among hundreds of racks. A data center rack network switch can easily pass more than 100 Gbps (gigabits per second) between servers at any given time, while only having 40 Gbps of bandwidth available for data leaving the rack. Bandwidth imbalance – check. However, historically that hasn’t been an issue, because the applications are typically architected to keep as much network traffic within a rack as possible, since bandwidth is plentiful and latency is minimal.
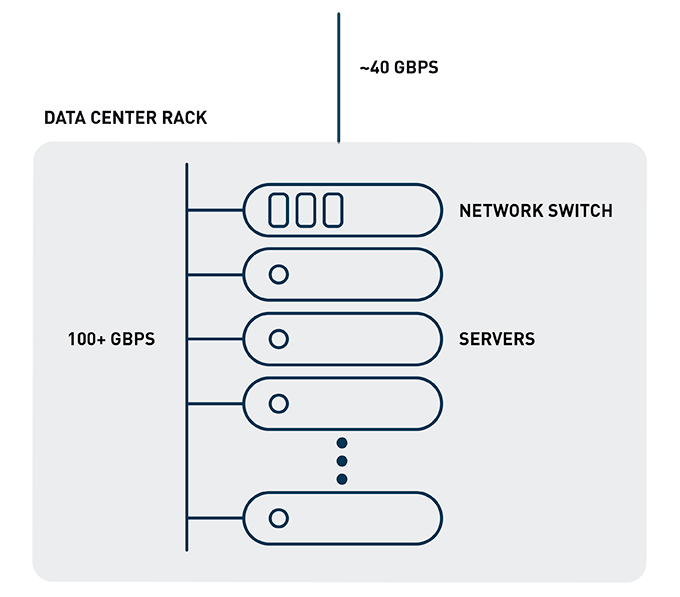
Figure 1: Imbalance of network bandwidth within and outside of rack
What has changed is that new cybersecurity threats have emerged that aim to infiltrate a single server within a data center, then surreptitiously work on infecting nearby servers, eventually overtaking an entire data center. To effectively protect against this type of threat, network security applications can’t just process the 10s of Gbps passing through data center ingress/egress points; they need to process the 100s of Gbps generated in each rack, detecting threats instantly before they can spread or leak sensitive data. This adds the third ingredient of an edge processing use case – time sensitivity.
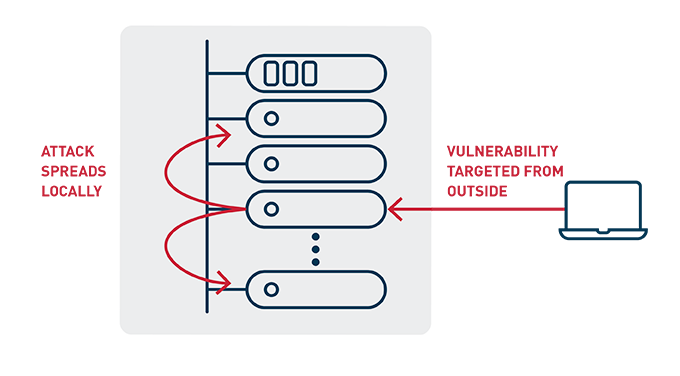
Figure 2: Spread of modern cybersecurity threat
To solve the challenge of analyzing terabits per second of network traffic and detecting threats in real time, companies need to adopt architectures that look a lot like those in oil and gas, mining, and factory. A common architectural principle in these environment is named “act locally, learn globally” and involves building machine learning models centrally, then shipping those models to many edge processing locations for local classification action. Using this architectural approach, companies can detect cybersecurity threats in the moment while avoiding the astronomical costs associated with funneling all network data to a central location or investing in commercial security appliances in every rack.

Figure 3: Local threat detection using edge processing