Click to learn more about author Michael Blaha.
We favor the offloading of application logic to SQL queries. Developers can save time, effort, and reduce mistakes by substituting SQL for programming code. This leads to lengthy and complex SQL that must be debugged.
It is common to write a SQL query that initially fails to execute. By misspelling a name. By omitting a keyword. By being inconsistent with table aliases. Or by using an illegal function. Database error messages indicate that something is wrong but often do not pinpoint the precise problems. We can inspect the query but often fail to notice errors as we see what is intended, rather than what is written. Here are techniques for debugging SQL.
The General Process
The first step is to unravel SQL code. Select queries (as well as insert, delete, and update statements) can be nested. We separate the levels of nesting, testing logic from the inside out. We substitute representative values into correlated sub queries so that they can execute on their own. Our subsequent debugging steps deal with one query at a time.
Once we have flat queries, the next focus is join logic. We strip away the where predicates and replace all the select attributes with a *. It’s easy to run afoul of joins so we check to make sure that we’re not accidentally losing records. An inner join across an optional relationship can cause an unintended loss of records. Sometimes an inner join should be restated as an outer join.
Next we restore the where predicates and run the query again. If the query fails, there is clearly something wrong with one or more predicates. At this point careful reading will sometimes find the errors. If we still can’t see the errors, we step back and restore a few predicates at a time. Eventually, with a narrow focus the errors become obvious.
Once the joins and where predicates are correct, we look at select attributes. We introduce groups of attributes, a few at a time and make sure the results remain correct.
The final step is to put nested queries back together to form the full initial SQL statement. We test the SQL statement to ensure that it runs correctly.
An Example
Here’s a sample data model and query for a data warehouse. It’s not unusual for a warehouse query to cover multiple pages.
In the data model there are Order Facts for Customer, Date, Time, Location, and other dimensions not shown.
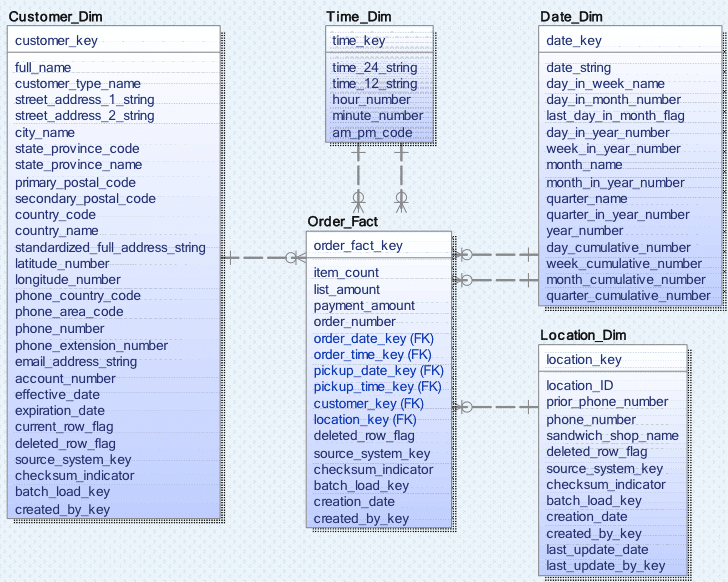
The SQL statement finds customer postal codes with the most orders in a year for each store location. The Q2 query gets the max count by year and store location. The outermost query adds the postal code matching the max count.
SELECT Q2.year, Q2.loc_phone_number, Q3.primary_postal_code,
Q2.max_order_count
FROM (
SELECT Q1.year, Q1.loc_phone_number, MAX(order_count) AS max_order_count
FROM (
SELECT CD.primary_postal_code, substring (DD.date_string,1,4) AS year,
LD.phone_number AS loc_phone_number, COUNT(*) AS order_count
FROM Order_Fact OrdF
JOIN Date_Dim DD ON OrdF.order_date_key = DD.date_key
JOIN Customer_Dim CD ON OrdF.customer_key = CD.customer_key
JOIN Location_Dim LD ON OrdF.location_key = LD.location_key
GROUP BY CD.primary_postal_code, substring (DD.date_string,1,4),
LD.phone_number) AS Q1
GROUP BY Q1.year, Q1.loc_phone_number ) AS Q2
JOIN (
SELECT CD.primary_postal_code, substring (DD.date_string,1,4) AS year,
LD.phone_number AS loc_phone_number, COUNT(*) AS order_count
FROM Order_Fact OrdF
JOIN Date_Dim DD ON OrdF.order_date_key = DD.date_key
JOIN Customer_Dim CD ON OrdF.customer_key = CD.customer_key
JOIN Location_Dim LD ON OrdF.location_key = LD.location_key
GROUP BY CD.primary_postal_code, substring (DD.date_string,1,4),
LD.phone_number ) AS Q3
ON Q2.year = Q3.year AND Q2.loc_phone_number = Q3.loc_phone_number AND
Q2.max_order_count = Q3.order_count;
Applying the Debugging Process
- Unravel SQL code. This results in four queries – Q1, Q2, Q3, and the overall query. The Q1 and Q3 queries are the same.
- Join logic. All the relationships are to mandatory dimensions, so we will not accidentally drop any records. Typically, all data warehouse dimensions are mandatory. Dimensions have special records for “not known” or “not applicable”. However in prototyping, we sometimes access source operational data and there we sometimes encounter optional relationships that can cause inadvertent dropping of records.
- Where predicates. The example has no WHERE clauses, so we can skip this step.
- Select attributes. The attributes are straightforward but there are GROUP BY clauses. So we test run the queries with and without the grouping logic to make sure they are correct.
- Final step. And then finally we put the query back together and see that it has valid SQL and yields a correct answer. This query happened to be correct from the start, so checking of the query was simple.
In Conclusion
We’ve seen developers become frustrated when a complex SQL statement fails to execute. A straightforward approach of pulling the statement apart along with careful reading and testing of the pieces will usually find the errors. In practice, we find that SQL code is much easier to debug than programming code. SQL code is declarative and generally readable. Also SQL code is easy to break down into constituent pieces for testing.



