Click to learn more about author Thomas Frisendal.
Machine Generated
Looking at machine generated data makes you wonder about the Data Modeling of such. Whodunnit?
Actually, the whole Big Data tsunami was caused by ‘machine generated’ data coming in in great numbers. Unstoppable.

We all know that ‘machine generated’ is not really a proper description of what is going on. Yes, the “thing” (an embedded computer at the edge of the Internet) is transmitting the data, but that is not new. For most of my long career the same has been true of invoices and many other things. And IT generated stuff is carefully curated, right? The term to use is “modeled”. This has been so for a number of years.
The software engineers worked together with the Data Modeler and together they crafted a very nice model of an invoice. At the same time the Information Scientist (don’t call them librarians, please), helped out engineers and scientist in the manufacturing, chemical, pharmaceutical and public organizations to develop and maintain rock solid, precise business vocabularies (ontologies and the like). What then happened was that the software engineers, working on tight schedules, eased down on the support from the Data Modelers. And the information scientists got more and more of machine assistance from text mining of categories, entities, themes and so forth.
Enter the Data Scientists facing the tsunami of generated data. Since much of the data they receive is “not designed here”, they have a hard time figuring out, what they hold in their hands.
Data Scientists were followed by a new waive of machine assistance called for example “Data Discovery”, which also includes Data Profiling and Domain Discovery. So, the Data Scientists are, among other things, also building models of data – albeit data models in statistics are not quite the same as a data model in a text book by Chris Date.
Who are the Actors on the Data Modeling Scene?
Today, we have at least these categories of people doing, what 30 years ago was only done by Data Modelers:
- Data Modelers
- Software developers in IT systems or in embedded systems
- some with Computer Science background and
- other with an Engineering or Business Management degree.
- Information Scientists
- Data Scientists
Most of these good people have academic degrees. Both Information Science and Data Science have good offerings of bachelor and/or master degrees of 2-3 years and 1-2 years of durance, respectively. Modeling in some form or shape is a good part of the education.
When it comes to Data Modelers (full time people, I mean), there is no Science of Data Modeling with its own bachelor or masters degrees. Many Data Modelers have computer science background, and in those curricula Data Modeling is typically a one-semester course. Most Data Modelers, therefore, rely on additional education:
- Database vendors and,
- Independent providers such as, not least, DATAVERSITY®!
The engineers, who know how to program (most of them have been exposed to it) might not have had training worth mentioning in Data Modeling. Add to that that they also see the sensor (or whatever) data from inside a technical bell jar.
What can we do to help those in need of Data Modeling skills?
Which are the Skill Sets?
If we want to improve on this situation, and we do, we need to understand the sets of skills required across these different perspectives on data and information management. In particular, it would be interesting to see the skills, which are shared among the sets:

Consequently, I did some simple text analytics based on Wikipedia. I was using an online demo facility from a vendor (Lexalytics), where you can paste in a URL and you will get some text analytics returned. I was interested in the themes contained in the three Wikipedia articles about Data Modeling, Data Science and Information Science. I copy/pasted them into an Excel sheet and applied some data preparation of my own (filtered out some verbose or arcane themes and added some of my own, which in my experience should have been in there).
I added a fourth “science” theme set called “Future Modeling” picking from the other 3 and adding what I think is essential for Data Modeling in the future (which starts today).
I then loaded the theme lists into a Neo4j Graph Database, and here is what I got in return:

The above is just to give you a sense of the size of the graph – don’t look after your looking glass! You can see, however, (towards the outer parts of the graph) that some themes are local to a “science”. That was expected. Data Scientists are math and statistics savvy, and information scientists are terminology savvy, for example.
But what is shared between them?
Shared Skills
Let us look at the skills, which are shared between two or more of the classic “sciences”:
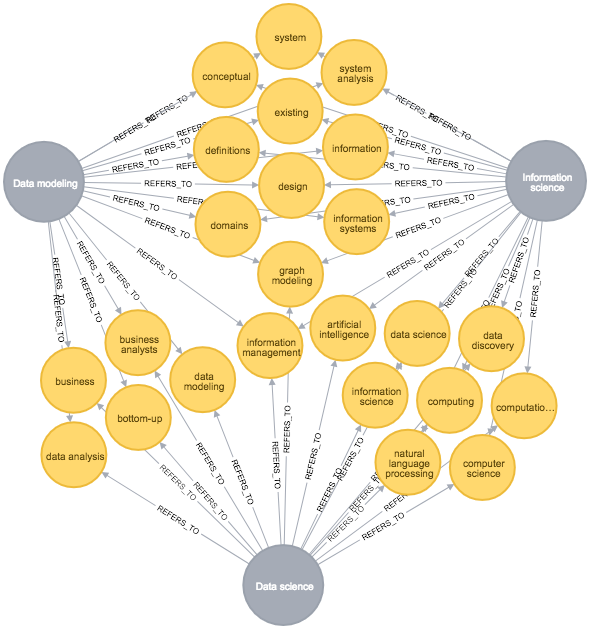
Here you can see that some of the skills are very generic (like “computing”) and other are more specific. I actually added a few, which I believe already today are part of the reality: Information management, natural language processing and data discovery.
What is interesting to see is that Data Modeling and information science actually share 11 themes. The information scientists have, mind you, had up to 5 years of academic training. I do believe that Data Modelers must hang on to the railing and sail along, because the information scientists have some strong skills to offer. They may not be experts in 5th normal form, but maybe that is not the hottest issue today?
It is also interesting to see that Information Science and Data Science have considerable overlap on the automation side.
The overlap between Data Modelers and Data Scientists are on core Data Modeling skills, which also should make us think.
What about the immediate future?
Data Modeling from Now On
If I select the sub-graph, where the “Data Modeling science” is replaced by the “Future Modeling science”, the graph looks like this:
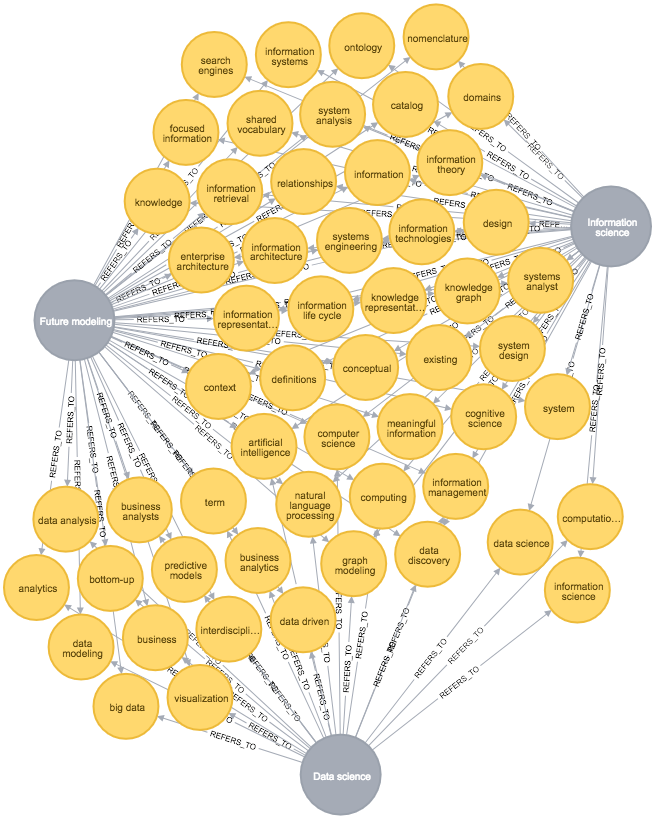
(The full skill set of “Future Modeling” can be seen at the end of this post.)
Again, you are not expected to read all the details, but the overlap between “Future Modeling” and “Information Science” has increased. The best example is the Knowledge Graph opportunity for being used for data integration purposes. Graph Data Modeling is also a good example of a generally useful skill.
Are we seeing a race starting between Data Modelers and Information Scientists, where the best women and men win? I think so.
On a smaller scale, the number of the collegial similarities between future Data Modelers and data scientists are also growing in numbers and complexity; see for example visualization and knowledge about how to model for predictive analytics.
To make it easier, I have extracted the sub-graph of the shared themes (skills) between all three of them, forward looking:
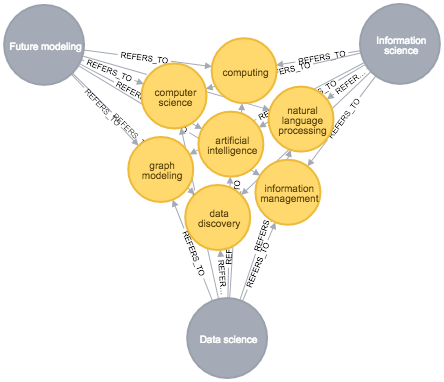
A few things can be inferred from the graph above:
- The Data Modelers should work from a business continuity perspective, making sure that database and application content is governed and that
- The Information Scientists should work from a business quality perspective, and their findings (ontologies, vocabularies and so forth) should find their ways into the operational systems and data models, whereas
- The Data Scientists should work from a business opportunity perspective trying to incorporate generated data from external sources, the internet of things and other places, and try to fit them in with the terminology and data models maintained by the Data Modelers and the Information Scientists, meaning that,
- The 3 types of actors could benefit immensely from a common platform, and
- Knowledge Graphs will be a key part of fitting all this together.
The universities should offer inter-disciplinary courses as much as possible – that will create a lot of business benefits in the organizations, where the candidates are going to work.
The education and training providers have a great amount of work ahead and some great opportunities for re-thinking and retro-fitting their offerings. I think that DATAVERSITY is aware of these dynamics.
I strongly encourage vendors of modeling tools, metadata repositories and data catalogs etc. to broaden the perspectives and take a holistic approach to all of it. I will be happy to share my thoughts with them.
Interesting times!
I have provided all data and high-resolution graph displays.
The mostly complete list of themes (“skills”) for future Data Modelers is this:
- Analytics, Artificial Intelligence, Big Data, Business Analytics, Business Intelligence, business needs and processes.
- Cognitive Science, Computer Science, Data Analysis, Data Discovery, data elements, Data Modeling, data requirements, data sharing, data structures, Data Warehouses, Database Management, database design, data definitions, and data domains.
- Enterprise Architecture, enterprise perspective, entity-relationship models, entity types, Graph Modeling, Information Architecture, information engineering, Information Lifecycle Management, Information Management, information representation, information retrieval, information systems, and information technologies.
- Knowledge Graphs, knowledge representation, logical design, logical data models, meta models, Natural Language Processing, nomenclature, ontology.
- Physical data models, physical data stores, predictive models, relation types, relational concepts, relational databases, and relationships.
- Schema, search engines, Semantic Data Modeling, shared vocabulary, storage technologies, subject areas, system analysis, system design, systems engineering, vault modeling, and visualization.