
Natural Language Processing (NLP) unlocks the ability of machines to read text, hear speech, and interpret words, and NLP has advanced greatly in the last five years.
NLP improves data analytics, detects malware, and fights fake news. For example, using NLP the Citation-Informed Estimated Truth (CIET) software program identifies authentic news with a 78 percent to 85 percent improvement over the Make News Credible Again (MNCA) Machine Learning algorithm. This CIET accomplishment should not go understated. “Language is everywhere but it is hard,” Joachim Rahmfeld, Ph.D. – a lecturer at UC Berkeley – said during a September 2019 DAMA Portland meetup on recent NLP advances. Human languages contain ambiguities, different language structures, and uncertainties. That a machine can generate human text and identify sources influencing it is impressive.
Further NLP innovations in the last year have driven it to be much more efficient through focused attention. Rahmfeld spoke about how NLP has evolved and why some machine learning programs have more capabilities than others to comprehend text with “greater accuracy and speed.” His presentation also showed how deep learning, a type of machine learning, has changed, making sense of tons of text and business use cases. Rahmfeld’s talk addressed the following advances:
- Over the summer of 2019, NLP has made big strides that will impact machine learning quality solutions down the road. Capabilities today are a shadow of what is yet to come.
- Improvements in NLP technologies have changed how artificial intelligence (AI) learns. Scientists still do not know step-by-step exactly what AI learns, but researchers know how to make it learn faster and better.
- Businesses can control inputs and direct algorithms toward desired outcomes but cannot control each step of the machine learning process. The type of NLP also makes a difference in terms of desired goals.
Neural Nets: Making NLP Practical?
To get a sense of how far NLP has come, Rahmfeld started by giving a history of it. Before the 2000s, NLP was cumbersome. Programmers used complex handwritten rules to make sense of text. This approach became slow and costly. The code was just too complex and unwieldy. There were too many details for programmers to track, the methodology too impractical. Scientists needed a different model.
In the 1990s, scientists switched to training algorithms based on probabilities and statistics. Computer programs in this practice embed words with numbers to make sense of inputs and choose outcomes based on calculating the best pattern match, given program parameters. So, data sets feed to AI, and it infers the result, statistically. Machine behaviors closest to picking the right pattern are reinforced in its algorithms. The training is tried again multiple times. This statistical approach exceeded the rules-based approach with better results, greater speed, and more robustness. Researchers continue to use statistical models today in evaluating machine learning and NLP.
In the mid-2000s, Rahmfeld noted, NLP experienced “dramatic progress.” He attributed it to three trends:
- Massive increases in and availability of training data from the web.
- Great advances in computing power, such as Graphic Processing Units (GPUs).
- Dramatic progress in algorithms, such as a “large-scale unsupervised model” called GPT-2 that advanced the machine’s reading comprehension.
Scientists took these three advantages and developed modern neural net architecture. Neural nets describe AI based on the human brain framework, where processing layers or neurons connect together to get from an input to a result. Essentially, computer neurons, in a hidden layer, combine data inputs (think a grid of numbers). Neural nets calculate weights (data importance) and biases (parameters used to make it more meaningful based on the information given). These calculations guide the algorithms to adjust the selection output match. In the diagram below, neural nets appear as green circles.
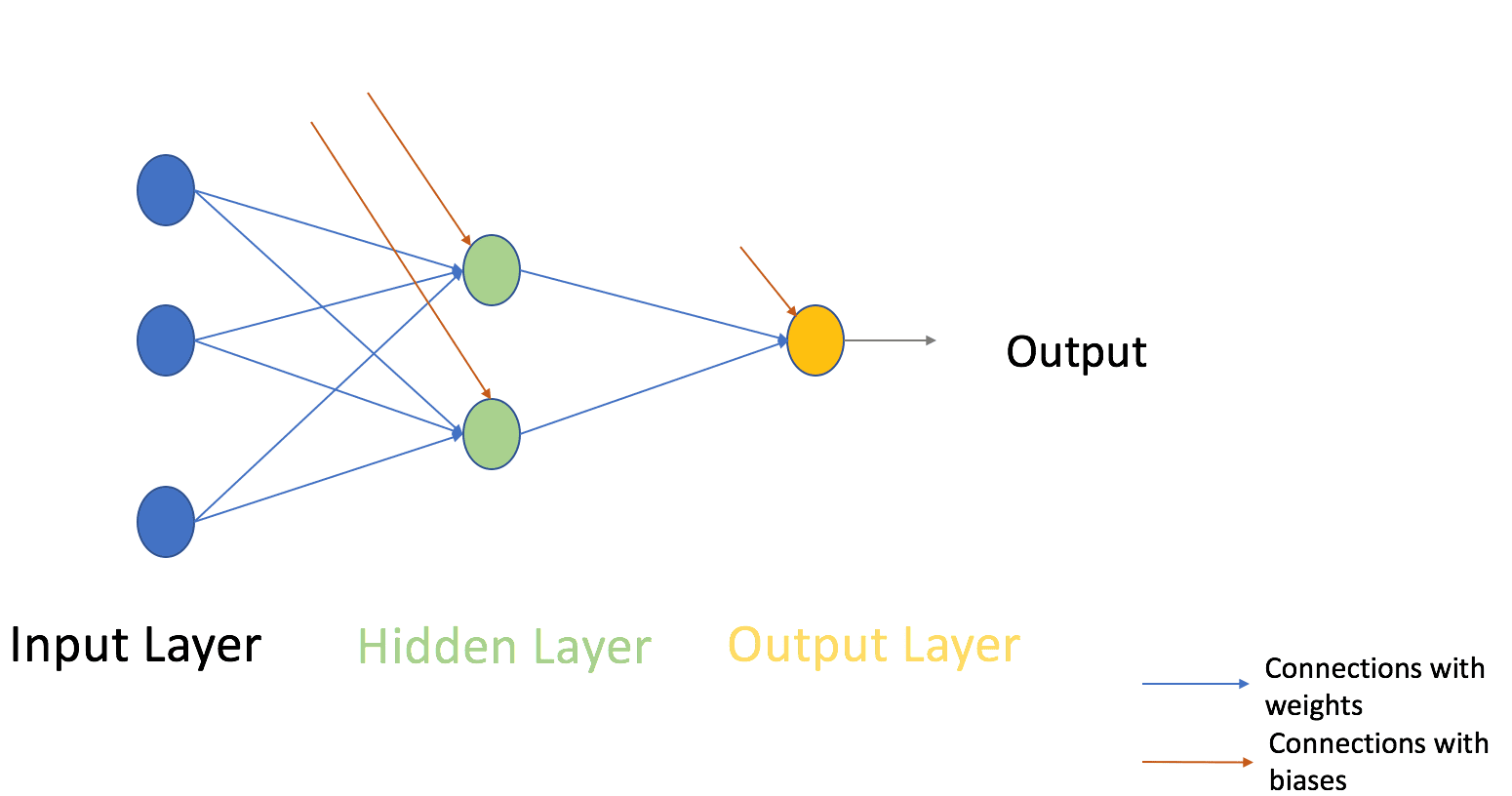
Neural net technology advanced NLP to where machines could infer gender, verb tense, and capitals of country by matching numbers. For example, AI matched a king as male gender.
But, as Rahmfeld pointed out, NLP reached limitations in only using this approach. For example, neural nets would process “bank” to mean the same in the following: riverbank, money in the bank, and bank into a turn. This is not helpful if you are putting money into a bank account. Neural nets needed to be improved so they could filter outputs and come up with better word matching. It turns out, Rahmfeld said, NLP has taken direction from image processing to do this.
Deep Learning and Language Refinement
Neural nets have been successful using deep learning and refining outputs to better identify images. In this system:
- The algorithms take a general to a task-specific approach in fine-tuning a match.
- Programs have some sort of short-term memory to recall the preceding output and calibrate it closer to the pattern match desired.
- Lower neural network layers identify features and edges, “while higher layers model higher-level concepts such as patterns and entire parts or objects,” he said.
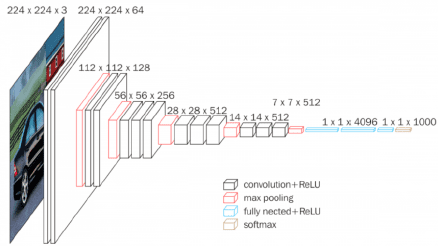
Rahmfeld described each rectangle in the above image as a web of neural nets calculating features of an image and outputting more precise target values. These calculations then get sent to the next neural net web, which calibrates the outputs, and so forth until the deep neural networks as a whole or the ImageNet labels the picture correctly. This ImageNet model, working around 2013, also applies to NLP through:
- Convolutional Neural Networks (CNN): Layers with filters applied and reapplied to the input grid, that successively narrow down and fine-tune the output. CNN, as Rahmfeld talked about, “searches for word features independent of a sentence location.” For example, the “sentiment or tone” of the entire text. CNN does this by chunking all the inputs. (See the image below.)
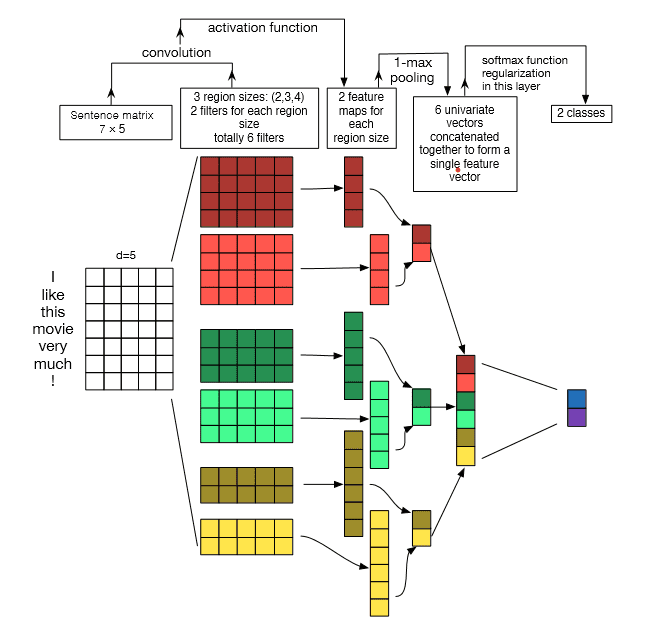
As a result, CNN’s can process lots of languages faster because it focuses on only the relevant inputs.
- Recurrent Neural Networks (RNN): Rahmfeld describes these as “networks with loops in them allowing information to persist.” In the diagram below, each blue dot is an input and the purple dot is an output.
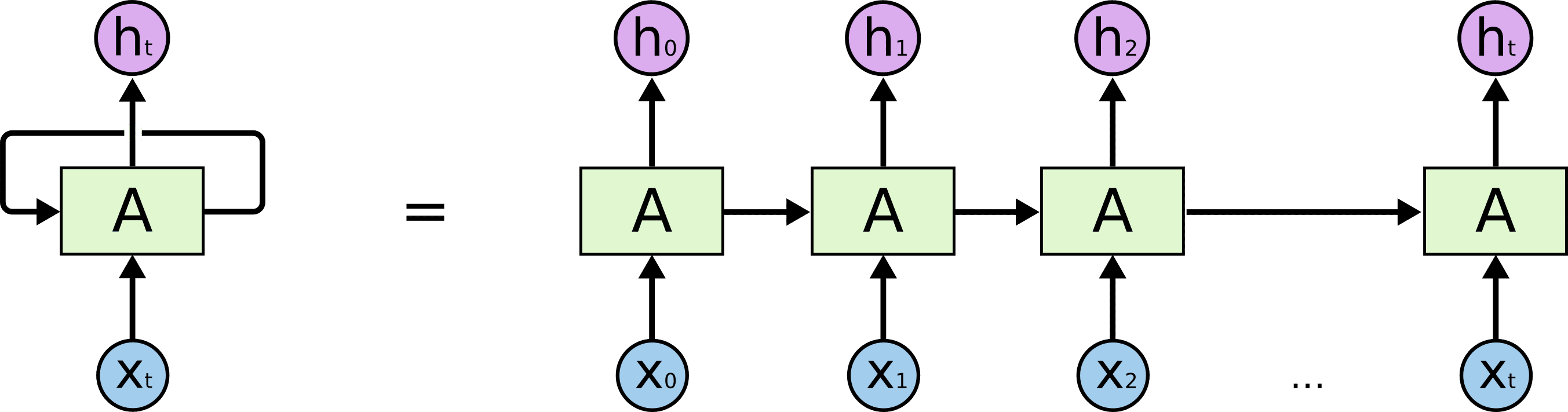
Image Credit: Christopher Olah [An unrolled recurrent neural network]
RNN remembers the direction and time of these inputs and outputs, an important feature to language, Rahmfeld noted. RNN takes a body of text and processes prior words to predict the next word, like an encoder and decoder. Rahmfeld says that this kind of approach does work well – however, the NLP quality goes down with longer sentences and this kind of technology can be rather slow by having to handle all the inputs.
All neural nets in the models described above, use filter-based systems over all the inputs to refine and statistically choose the best output.
Giving NLP Attention and BERT
Rahmfeld excitedly talked about new NLP technology – available within the last year. Neural nets now do not have to look at all the inputs. They can decide what is most important in a paragraph and translate (PDF) it at the same time, with Self-Attention (PDF). He argued that this NLP technology replaces RNN architecture because of three functions:
- As these neural nets encode text, they use attention where words compare themselves with other words in the sentence.
- The neural nets compare final outputs to the relevant inputs and outputs, not just the calculations at the output.
- The NLP handles inputs and outputs in parallel or simultaneously.
In this approach, NLP is moving faster (PDF) while being more accurate.
This schema has further been improved, as Rahmfeld noted, by a Bidirectional Encoder Representations from Transformer (BERT). BERT can process text both left to right and right to left throughout NLP in accomplishing specific tasks. BERT’s beauty is that its machine learning needs less training data and time to learn than other models.

Anyone can download and use BERT at no cost, as it is open-source code. Already software developers and researchers have taken advantage of this and created machine learning programs from BERT that translate fifty-three languages. BERT usage continues to be experimental, and practical applications need to be determined. However, the results could very well overtake current Machine Learning NLP solutions and should be watched.
Conclusion
NLP programming has come a long way through multiple approaches, as described by Rahmfeld. While NLP and machine learning have become more sophisticated, this is just the beginning. From Rahmfeld’s talk, companies need to understand that NLP and machine learning describe a variety of statistical models and approaches that will advance further and faster. Any business using NLP needs to assess the strengths and weaknesses of the technology in use. That, along with focused, quality data inputs and clear NLP outputs will make the difference in successfully applying advanced NLP.
Image used under license from Shutterstock.com

