
In today’s fast-paced world, the concept of patience as a virtue seems to be fading away, as people no longer want to wait for anything. If Netflix takes too long to load or the nearest Lyft is too far, users are quick to switch to alternative options. The demand for instant results is not limited to consumer services like video-streaming and ride-sharing; it extends to the realm of data analytics, particularly when serving users at scale and automated decisioning workflows. The ability to provide timely insights, make informed decisions, and take immediate action based on real-time data is becoming increasingly crucial. Companies such as Confluent, Target, and numerous others are industry leaders because they leverage real-time analytics and data architectures that facilitate analytics-driven operations. This capability allows them to stay ahead in their respective industries.
This blog post delves into the concept of real-time analytics for data architects who are beginning to explore design patterns, providing insights into its definition and the preferred building blocks and data architecture commonly employed in this domain.
What Exactly Constitutes Real-Time Analytics?
Real-time analytics are characterized by two fundamental qualities: up-to-date data and rapid insights. They are employed in time-sensitive applications where the speed at which new events are transformed into actionable insights is a matter of seconds.

On the other hand, traditional analytics, commonly known as business intelligence, refer to static representations of business data primarily utilized for reporting objectives. These analytics rely on data warehouses like Snowflake and Amazon Redshift and are visualized through business intelligence tools such as Tableau or PowerBI.
Unlike traditional analytics, which rely on historical data that can be days or weeks old, real-time analytics leverage fresh data and are employed in operational workflows that require rapid responses to potentially intricate inquiries.

For instance, consider a supply chain executive who seeks historical trends in monthly inventory changes. In this scenario, traditional analytics is the ideal choice as the executive can afford to wait a few additional minutes for the report to process. On the other hand, a security operations team aims to detect and diagnose anomalies in network traffic. This is where real-time analytics comes into play, as the SecOps team requires rapid analysis of thousands to millions of real-time log entries in sub-second intervals to identify patterns and investigate abnormal behavior.
Is the Choice of Architecture Significant?
Many database vendors claim to be suitable for real-time analytics, and they do have some capabilities in that regard. For instance, consider the scenario of weather monitoring, where temperature readings need to be sampled every second from thousands of weather stations, and queries involve threshold-based alerts and trend analysis. SingleStore, InfluxDB, MongoDB, and even PostgreSQL can handle this with ease. By creating a push API to send the metrics directly to the database and executing a simple query, real-time analytics can be achieved.
So, when does the complexity of real-time analytics increase? In the mentioned example, the data set is relatively small and the analytics involved are simple. With only one temperature event generated per second and a straightforward SELECT query with a WHERE statement to retrieve the latest events, minimal processing power is required, making it manageable for any time-series or OLTP database.
The real challenges arise and databases are pushed to their limits when the volume of ingested events increases, queries become more complex with numerous dimensions, and data sets reach terabytes or even petabytes in size. While Apache Cassandra is often considered for high throughput ingestion, its analytics performance may not meet expectations. In cases where the analytics use case requires joining multiple real-time data sources at scale, alternative solutions need to be explored.
Here are some factors to consider that will assist in determining the necessary specifications for the appropriate architecture:
- Are you working with high events per second, from thousands to millions?
- Is it important to minimize latency between events created to when they can be queried?
- Is your total dataset large, and not just a few GB?
- How important is query performance – sub-second or minutes per query?
- How complicated are the queries, exporting a few rows or large-scale aggregations?
- Is avoiding downtime of the data stream and analytics engine important?
- Are you trying to join multiple event streams for analysis?
- Do you need to place real-time data in context with historical data?
- Do you anticipate many concurrent queries?
If any of these aspects are relevant, let’s discuss the characteristics of the ideal architecture.
Building Blocks
Real-time analytics requires more than just a proficient database. It begins with the necessity to establish connections, transmit, and handle real-time data, leading us to the initial foundational element: event streaming.
1. Event streaming
In situations where real-time is of utmost importance, conventional batch-based data pipelines tend to be too late, giving rise to the emergence of messaging queues. In the past, message delivery relied on tools like ActiveMQ, RabbitMQ, and TIBCO. However, the contemporary approach involves event streaming with technologies such as Apache Kafka and Amazon Kinesis.
Apache Kafka and Amazon Kinesis address the scalability limitations often encountered with traditional messaging queues, empowering high-throughput publish/subscribe mechanisms to efficiently gather and distribute extensive streams of event data from diverse sources (referred to as producers in Amazon terminology) to various destinations (referred to as consumers in Amazon terminology) in real time.

These systems seamlessly acquire real-time data from a range of sources such as databases, sensors, and cloud services, encapsulating them as event streams and facilitating their transmission to other applications, databases, and services.
Given their impressive scalability (as exemplified by Apache Kafka’s support of over seven trillion messages per day at LinkedIn) and ability to accommodate numerous simultaneous data sources, event streaming has emerged as the prevailing mechanism for delivering real-time data in applications.
Now that we have the capability to capture real-time data, the next step is to explore how we can analyze it in real-time.
2. Real-time analytics database
Real-time analytics require a specialized database that can fully leverage streaming data from Apache Kafka and Amazon Kinesis, providing real-time insights. Apache Druid is precisely that database.
Apache Druid has emerged as the preferred database for real-time analytics applications due to its high performance and ability to handle streaming data. With its support for true stream ingestion and efficient processing of large data volumes in sub-second timeframes, even under heavy loads, Apache Druid excels in delivering fast insights on fresh data. Its seamless integration with Apache Kafka and Amazon Kinesis further solidifies its position as the go-to choice for real-time analytics.
When choosing an analytics database for streaming data, considerations such as scale, latency, and data quality are crucial. The ability to handle the full-scale of event streaming, ingest and correlate multiple Kafka topics or Kinesis shards, support event-based ingestion, and ensure data integrity during disruptions are key requirements. Apache Druid not only meets these criteria but goes above and beyond to deliver on these expectations and provide additional capabilities.
Druid was purposefully designed to excel in rapid ingestion and real-time querying of events as they arrive. It has a unique approach for streaming data, ingesting events on an individual basis rather than relying on sequential batch data files to simulate a stream. This eliminates the need for connectors to Kafka or Kinesis. Additionally, Druid ensures Data Quality by supporting exactly-once semantics, guaranteeing the integrity and accuracy of the ingested data.
Like Apache Kafka, Apache Druid was specifically designed to handle internet-scale event data. Its services-based architecture allows independent scalability of ingestion and query processing, making it capable of scaling almost infinitely. By mapping ingestion tasks with Kafka partitions, Druid seamlessly scales along with Kafka clusters, ensuring efficient and parallel processing of data.
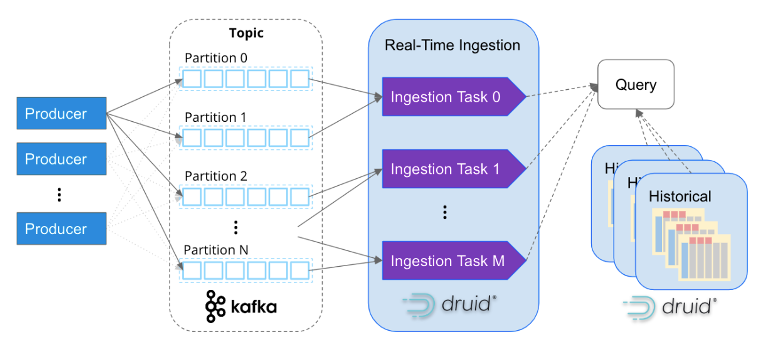
It is becoming increasingly common for companies to ingest millions of events per second into Apache Druid. For instance, Confluent, the creators of Kafka, has built their observability platform using Druid and successfully ingests over five million events per second from Kafka. This showcases the scalability and high-performance capabilities of Druid in handling massive event volumes.
However, real-time analytics goes beyond just having access to real-time data. To gain insights into patterns and behaviors, it is essential to correlate historical data as well. Apache Druid excels in this regard, as depicted in the diagram above, by seamlessly supporting both real-time and historical analysis through a single SQL query. Druid efficiently manages large volumes of data, even up to petabytes, in the background, enabling comprehensive and integrated analytics across different time periods.
When all the pieces are brought together, a highly scalable data architecture for real-time analytics emerges. This architecture is the preferred choice of thousands of data architects when they require high scalability, low latency, and the ability to perform complex aggregations on real-time data. By leveraging event streaming with Apache Kafka or Amazon Kinesis, combined with the power of Apache Druid for efficient real-time and historical analysis, organizations can achieve robust and comprehensive insights from their data.
Case Study: Ensuring a Top-Notch Viewing Experience – The Netflix Approach
Real-time analytics is a critical component in Netflix’s relentless pursuit of delivering an exceptional experience to over 200 million users, who collectively consume 250 million hours of content daily. With an observability application tailored for real-time monitoring, Netflix effectively oversees more than 300 million devices to ensure optimal performance and customer satisfaction.
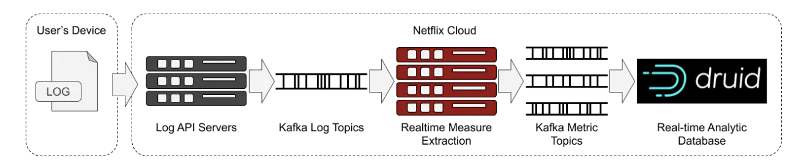
By leveraging real-time logs generated by playback devices, which are seamlessly streamed through Apache Kafka and ingested event-by-event into Apache Druid, Netflix gains valuable insights and quantifiable measurements regarding the performance of user devices during browsing and playback activities.
With an astounding throughput of over two million events per second and lightning-fast sub-second queries performed on a massive dataset of 1.5 trillion rows, Netflix engineers possess the capability to accurately identify and investigate anomalies within their infrastructure, endpoint activity, and content flow.
Unlock Real-Time Insights with Apache Druid, Apache Kafka, and Amazon Kinesis
If you’re interested in constructing real-time analytics solutions, I strongly encourage you to explore Apache Druid in conjunction with Apache Kafka and Amazon Kinesis.



