Data management (DM) comprises a comprehensive collection of consistent and responsible practices, concepts, and processes. These resources align data for business success and implement a data strategy. Additionally, they span long-term, abstract planning to hands-on, day-to-day data activities.
Since DM spans many outcomes, behaviors, and activities throughout the data lifecycle, companies find organizing it into a framework helpful. Such a methodology includes at least the following:
- Data Strategy: The basis for prioritizing resources and doing data operations
- Data Governance: A formalization of Data Management policies, procedures, and roles
- Data Architecture: The enterprise’s data infrastructure in its totality and its components
Organizations manage these three components, among others, to increase business opportunities, run operations well, and reduce risks.
Live Online Course: Data Management Fundamentals
Gain a comprehensive foundation in data management and prepare for CDMP certification – July 28-30, 2026.

Data Management Defined
Sometimes, data management gets interchanged with its components and practices during business communications. Consequently, it gets used in a particular context, such as a data governance program or implementing a specific data platform, while keeping other DM principles aside.
This kind of communication solves problems or deals with matters quickly. However, formalized Data Management definitions take a broad stance to focus on its entire framework, so other components get considered by the business, in general.
For example, DAMA International’s DMBoK defines Data Management as the “development, execution, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycles.” This meaning spans all activities with data through the course of its usage.
Data management also includes any connection between business and data. This concept covers all enterprise data subject areas and structure types to meet the data consumption requirements of all applications and business processes. Additionally, any data events and practices necessary to use data in business decisions fall in the context of DM.
Processes and involvements around delivering consistent and real-time data across the company happen under the DM umbrella. This includes improved scalability, visibility, quality, preparation, governance, security, and reliability.
Data Management Components
The assortment of Data Management practices, concepts, and processes forms different components, describable according to the Data Management framework. DAMA International has provided an evolved DMBoK 2 Wheel, as seen below:
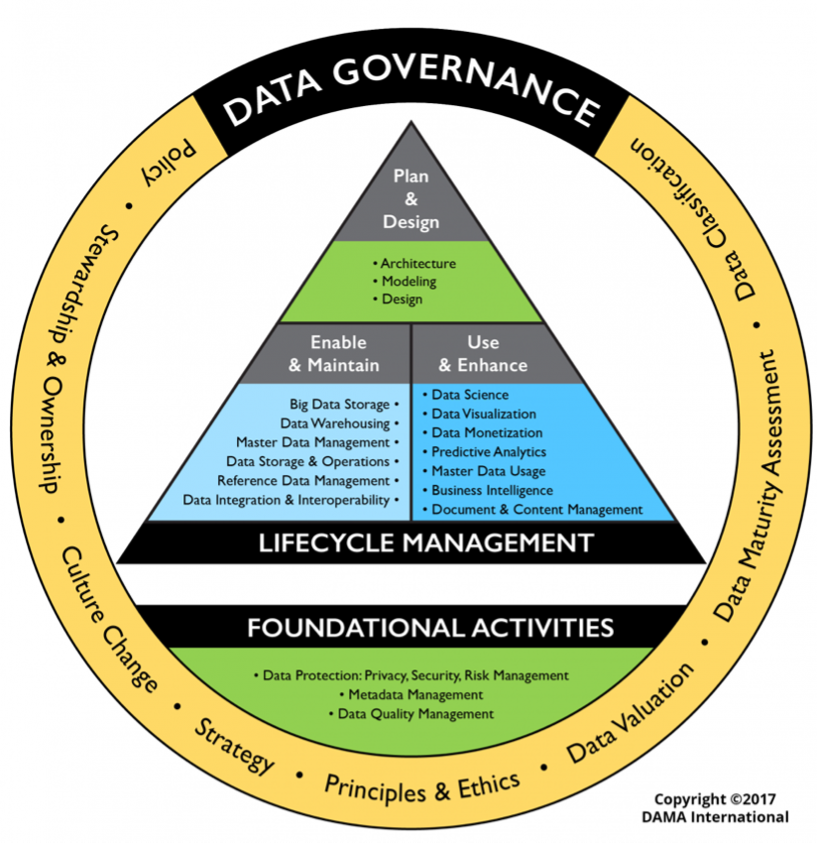
A yellow circle with high-level concepts surrounds Data Management activities conducted across its lifecycle and foundational activities. These ideas inform, guide, and drive the implementation of DM in an organization. They include the Data Strategy and Data Governance.
Foundational activities serve Data Management work done to manage the lifecycle and emerge from Data Governance deliverables. Examples of these outputs include:
- Data security: Implementing policies and procedures to ensure people and things take the right actions with data and information assets, even with malicious inputs.
- Metadata Management: Good Metadata Management “creates the context for other data elements, providing a complete picture of the data,” notes writer David Kolinek. This holistic view allows for organizing and locating data, understanding its meaning, and maximizing its value.
- Data Quality Management: Data Quality (DQ) describes the degree of business and consumer confidence in data’s usefulness based on agreed-upon business requirements. Data Quality Management aligns DQ expectations with reality.
Lifecycle management activities happen daily on the ground and are the most hands-on and visible parts of Data Management. These activities show up in three categories:
- Planning and Designing: Planning and designing practices combine the high-level conceptual guidance and the foundational activities into practical requirements to implement technically. For example, Data Architecture represents a planning and designing management activity.
- Enabling and Maintaining: Enablement and maintenance activities focus on DataOps to ensure predictable data communication, integration, and automation. Master Data Management, a method to ensure uniformity and accuracy of an organization’s shared data assets, constitutes a set of enablement and maintenance activities.
- Using and Enhancing: Activities that use and enhance data directly generate business insights and typify the work of analysts, data scientists, and other business professionals. For example, data visualization describes how the information appears on the screen, determining its usefulness.
Data Management vs. Data Governance
When managers and workers discuss Data Governance, they may substitute the concept of Data Management. The meanings of Data Governance and DM overlap quite a bit in processes around Data Quality, integration, policies, and standards.
However, DM also covers implementations of policies and procedures that do not fall under the mantle of Data Governance through technologies and tools. Day-to-day data activities, such as data observability, are not categorized as a Data Governance practice but are covered in Data Management practices.
CDMP Prep Made Easy
Prep smarter with expert-led courses, DMBoK coverage, and practice tests built to help you pass the CDMP exam.
Is Data Management Covered in Data Security?
Data security represents an essential component of Data Management. Its practices protect digital information from unauthorized access, corruption, or theft throughout its entire lifecycle, encompass every aspect of information security, and closely tie in with Data Governance.
However, focusing only on data security misses important Data Management aspects. For example, data privacy focuses on protecting personal data but may not overlap with data security. A business division may learn about an employee’s relationship status on social media, but if the organization fails to inform that person of the discovery, it calls into question the company’s Data Management of data privacy.
Moreover, gaining insights through reporting and analytics is a primary driver of DM. Since executives have a stronger drive to find new business opportunities, which requires appropriate access and transparency with data across their organizations, that factors into Data Management frameworks.
The Role of Digital Transformation
While Data Management is a strong foundation of digital transformation management, they are not the same. Data Management concentrates on leveraging data to maintain and improve the business. Digital transformation management leverages new technologies to support and advance a company.
For example, say a company, Dynamic, wants to transform its operations digitally through newer generative AI technologies. Dynamic will need to do DM processes to improve access to knowledge about its customers, employees, products, or finances.
Also, Dynamic will need to start with its people to share their knowledge for digital transformation. To get to this point, Dynamic will need to encourage their teams to work together, which may involve an outing to bring remote workers together for lunch. Although not a DM event, the lunch would provide a building block for digital transformation.
In the meantime, Dynamic would need to train employees to become data-literate, improving their work and analysis of enterprise data. Such Data Literacy training may not be relevant to digital transformation but may be relevant to other DM aspects, like human compliance with the General Data Privacy Regulation (GDPR).
Benefits of Data Management
Data, a reusable resource, fuels business opportunities and revenue. Data Management provides the engine to drive data towards that end.
Additionally, DM saves companies money and increases efficiency. It provides a means to identify and handle risks, such as inefficient operations or fines due to a lack of compliance or a data breach.
Moreover, organizations use Data Management to adapt quickly when the business environment changes. Through DM, they can handle common and ongoing challenges, like increasing data volumes, new roles for analytics, and compliance requirements.
Businesspeople see these advantages concretely, with
- Better performance of business activities with more scalability
- Improved customer relationships by customizing their experience
- Enhanced security and privacy
- More effective marketing and sales campaigns
- Improved data access through greater capabilities to share data
- Faster delivery of products and services
- Improved operations management by streamlining individual activities together
- Better regulation and compliance controls
- Speedier API and system development
- Improved decision-making and reporting, especially with real-time data
- Better data flow across business units across the organization
- More consistency across all enterprise work activities
- Faster adoption of AI technologies
Use Cases
Data Management use cases span various applications, technologies, industries, and outcomes. These examples span larger long-term business goals and specific technical implementations.
Long-Term Enterprise-Wide Scenarios
See below for long-term, company-wide examples:
- The USTRANSCOM developed and implemented a Data Strategy for better-informed decision-making, customer understanding, and improvements in operations.
- An institution for higher learning implemented a Data Governance program as an enterprise-wide initiative, including a data catalog. This DM implementation led to enhanced collaboration and transparency, with notifications about Data Governance decisions decreasing from 80 to 25 days.
- A healthcare company implemented machine learning (ML) technologies to identify and address fraud.
- A global financial services company implemented a robust DM framework to accommodate high transaction volumes.
- European automakers deployed a secure data exchange ecosystem, Catena-X, with capabilities to detect a quality issue, reducing the number of vehicles to recall by more than 80%.
Short-Term Project-Based Scenarios
The list below contains use cases conducted on a particular short-term project or sub-group of units:
- A company implemented digital transformation through a WalkMe app and a Digital Adoption Platform (DAP). The organization engaged customers through technology, people, and processes, leading to a central help content repository.
- A joint research initiative among a couple of universities, the E2e Project, captured manufacturing data about air compression through an Internet of Things (IoT) kit and reported energy usage. The manufacturers received recommendations to improve efficiency and target repairs and replacements.
- A finance group at an organization integrated its data with other business units across the organization.
- A company implemented data fabric to follow up on customer sentiments to predict churn and conduct advanced predictive and prescriptive analytics for optimizing products or processes.
Image at top used under license from Shutterstock.com
Applied Data Governance Practitioner Certification
Validate your expertise and take your career to the next level.

