
Data integration processes benefit from automated testing just like any other software. Yet finding a data pipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
A characteristic of data pipeline development is the frequent release of high-quality data to gain user feedback and acceptance. At the end of every data pipeline iteration, it’s expected that the data is of high quality for the next phase.
Automated testing is essential for the integration testing of data pipelines. Manual testing is impractical in highly iterative and adaptive development environments.
Primary Issues with Manual Data Testing
First, it takes too long and is a critical inhibitor to the frequent delivery of pipelines. Teams that rely primarily on manual testing end up postponing testing to dedicated testing periods, allowing bugs to accumulate.
Second, manual data pipeline testing is insufficiently reproducible for regression testing.
Automating the data pipeline tests requires initial planning and continuous diligence, but once the technical teams adopt automation, the project’s success is more assured.
Variants of Data Pipelines
- Extract, transform, and load (ETL)
- Extract, load, and transform (ELT)
- Data lake, data warehouse pipelines
- Real-time pipelines
- Machine learning pipelines
Data Pipeline Components for Test Automation Consideration
Data pipelines consist of several components, each responsible for a specific task. The elements of a data pipeline include:
- Data Sources: The origin of the data
- Data Ingestion: The process of collecting data from the data source
- Data Transformation: The process of transforming the collected data into a format that can be used for further analysis
- Data Verifications/Validations: The process to ensure that the data is accurate and consistent
- Data Storage: The process of storing the transformed and validated data in a data warehouse or data lake
- Data Analysis: The process of analyzing the stored data to identify patterns, trends, and insights
Best Practices for Automating Data Pipeline Testing
What and when to automate (or even if you need automation) are crucial decisions for the test (or development) team. The selection of suitable product characteristics for automation largely determines the success of automation.
When automating tests for a data pipeline, best practices include:
- Define clear and specific test objectives: Before you start testing, it is essential to define what you want to achieve through testing. Doing so will help you create effective, efficient tests that provide valuable insights.
- Test all workflows of the data pipeline: A data pipeline usually consists of several components: data ingestion, processing, transformation, and storage. It is important to test each component to ensure the proper and smooth flow of data through the pipeline.
- Use credible test data: When testing a data pipeline, it’s important to use realistic data that mimic real-world scenarios. This will help identify any issues that may occur when handling different data types.
- Automate with effective tools: This can be achieved using testing frameworks and tools.
- Monitor the pipeline on a regular basis: Even after testing is complete, it is essential to monitor the pipeline regularly to ensure it is working as intended. This will help identify issues before they become critical problems.
- Engage stakeholders: Involve stakeholders such as data analysts, data engineers, and business users in the testing process. This will help ensure that the tests are relevant and valuable to all stakeholders.
- Maintain documentation: Maintaining documents that describes the tests, test cases, and test results is important. This will help ensure the tests can be replicated and maintained over time.
Be careful; automation of changing unstable features should be avoided. Today, no known business tool or set of methods/processes can be considered a complete end-to-end test of the data pipeline.
Consider Your Test Automation Goals
Data pipeline test automation is described as using tools to control 1) test execution, 2) comparisons of actual outcomes to predicted outcomes, and 3) the setup of test pre-conditions and other test control and test reporting functions.
Generally, test automation involves automating an existing manual process that uses a formal test process.
Although manual data pipeline tests can reveal many data flaws, they are laborious and time-consuming. In addition, manual testing may be ineffective in detecting certain defects.
Data pipeline automation involves developing test programs that would otherwise have to be performed manually. Once the tests are automated, they can be repeated quickly. This is often the most cost-efficient method for a data pipeline that can have a long service life. Even minor fixes or enhancements over the lifetime of the pipeline can cause features to break which were working earlier.
Integrating automated testing in data pipeline development presents a unique set of challenges. Current automated software development testing tools are not readily adaptable to database and data pipeline projects.
The wide variety of data pipeline architectures further complicates these challenges because they involve multiple databases requiring special coding for data extraction, transformations, loading, data cleansing, data aggregations, and data enrichment.
Test automation tools can be expensive and are usually used along with manual testing. However, they may become cost-effective in the long run, especially when used repeatedly in regression tests.
Frequent Candidates for Test Automation
- BI report testing
- Business, government compliance
- Data aggregation processing
- Data cleansing and archiving
- Data quality tests
- Data reconciliation (e.g., source to target)
- Data transformations
- Dimension table data loads
- End-to-end testing
- ETL, ELT validation and verification testing
- Fact table data loads
- File/data loading verification
- Incremental load testing
- Load and scalability testing
- Missing files, records, fields
- Performance testing
- Referential integrity
- Regression testing
- Security testing
- Source data testing and profiling
- Staging, ODS data validations
- Unit, integration, and regression testing
Automating these tests may be necessary due to the complexity of the processing and the number of sources and targets that should be verified.
For most projects, data pipeline testing processes are designed to verify and implement data quality.
The Variety of Data Types Available Today Presents Testing Challenges
There is a wide variety of data types available today, ranging from traditional structured data types such as text, numbers, and dates to unstructured data types such as audio, images, and video. Additionally, various types of semi-structured data, such as XML and JSON, are widely used in web development and data exchange.
With the advent of the Internet of Things (IoT), there has been an explosion in various data types, including sensor data, location data, and machine-to-machine communication data. As these data types are extracted and transformed, testing can become more complicated without appropriate tools. This has led to new data management technologies and analytical techniques like stream processing, edge computing, and real-time analytics.
Figure 1 displays examples of data types widely used today. The vast number represents challenges when testing whether required transformations are correctly performed. As a result, data professionals must be well-versed in a broad range of data types and be adaptable to test emerging trends and technologies.
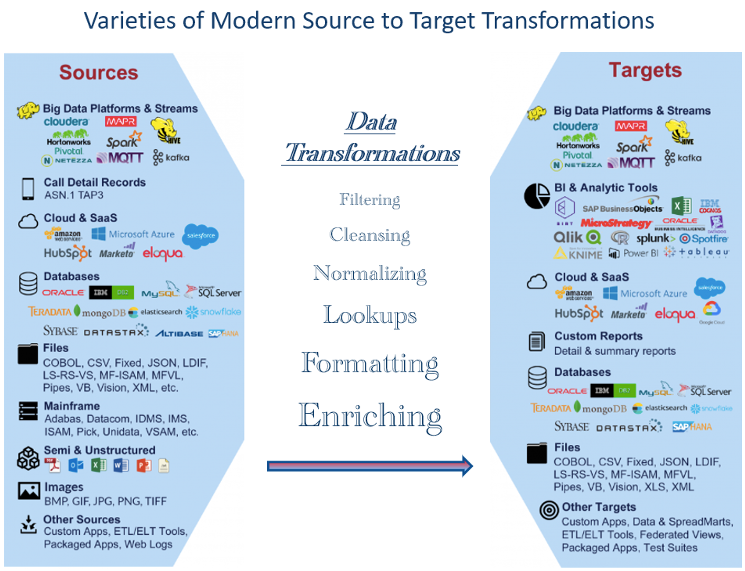
Evaluate Pipeline Components for Possible Automated Testing
A key element of agile and other modern developments is automated testing. We can apply this awareness to the data pipeline.
An essential aspect of data pipeline testing is that the number of tests performed will continue to increase to check added functionality and maintenance. Figure 2 shows many areas where test automation can be applied in a data pipeline.
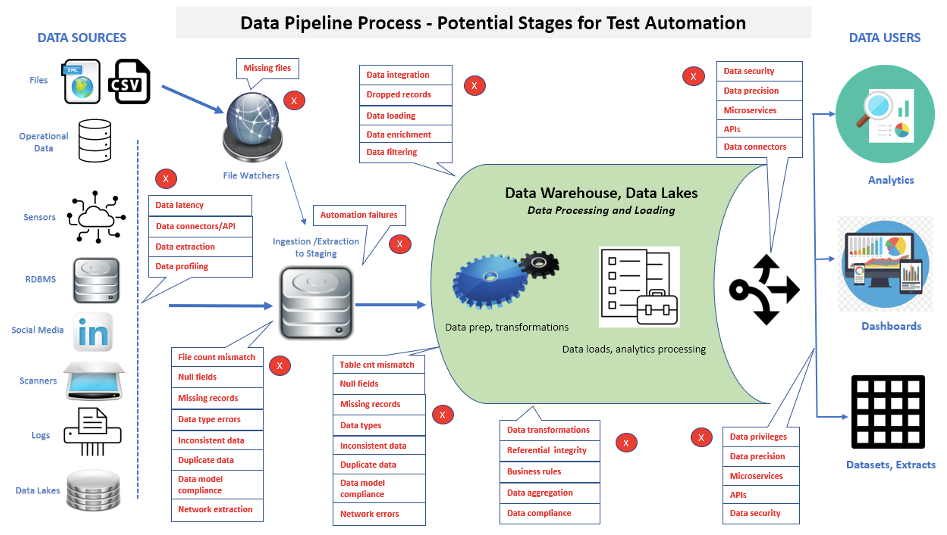
When implementing test automation, data can be tracked from source layers, through data pipeline processing, to loads in the data pipeline, then finally to the front-end applications or reports. Suppose corrupt data is found in a front-end application or report. In that case, the execution of automated suites can help more rapidly determine whether individual problems are located in data sources, a data pipeline process, a newly loaded data pipeline database/data mart, or business intelligence/analytics reports.
An emphasis on the rapid identification of data and performance problems in complex data pipeline architectures provides a key tool for promoting development efficiencies, shortening build cycles, and meeting release criteria targets.
Decide Categories of Tests to Automate
The trick is determining what should be automated and how to handle each task. A set of questions should be considered when automating tests, such as:
- What is the cost of automating the tests?
- Who is responsible for test automation (e.g., Dev., QA, data engineers)?
- Which testing tools should be used (e.g., open source, vendor)?
- Will the chosen tools meet all expectations?
- How will the test results be reported?
- Who interprets the test results?
- How will the test scripts be maintained?
- How will we organize the scripts for easy and accurate access?
Figure 3 shows examples of time durations (for test execution, defect identifications, and reporting) for manual vs. automated test cases from an actual project experience.
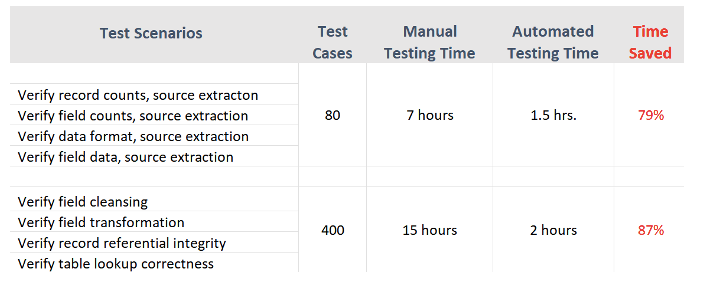
Automated data pipeline testing aims to cover the most critical functions for loading a data pipeline – synchronization and reconciliation of source and target data.
Benefits and Limitations of Automated Testing
Test Automation Challenges
- Report testing: Testing business intelligence or analytic reports through automation
- Data complexity: Data pipeline testing often involves complex data structures and transformations that can be challenging to automate and require specialized expertise.
- Pipeline complexity: Data pipelines can be complex and may involve multiple processing stages, which can be challenging to test and debug. In addition, changes to one part of the pipeline may have unintended consequences downstream.
Test Automation Benefits
- Executes test cases faster: Automation may speed up the implementation of test scenarios.
- Creates a reusable test suite: Once the test scripts are run with the automation tools, they can be backed up for easy recall and reuse.
- Eases test reporting: An interesting feature of many automated tools is their ability to produce reports and test files. These capabilities accurately represent data status, clearly identify deficiencies, and are used in compliance audits.
- Reduces staffing and rework costs: Time spent on manual testing or retesting after correcting defects can be spent on other initiatives within the IT department.
Potential Limitations
- Cannot completely replace manual testing: Although automation can be used for various applications and test cases, it cannot completely replace manual testing. Intricate test cases will still exist where automation will not capture everything, and for user acceptance testing, end-users often have to perform tests manually. Therefore, having the right combination of automated and manual testing in the process is vital.
- Cost of tools: Commercial testing tools can be expensive, depending on their size and functionality. On the surface, a business may view this as an unnecessary cost. However, reuse alone can quickly make it an asset.
- Cost of training: Testers should be trained not only in programming but also in scheduling automated tests. Automated tools can be complicated to use and may need user training.
- Automation needs planning, preparation, and dedicated resources: The success of automated testing is mainly dependent on precise testing requirements and the careful development of test cases before testing begins. Unfortunately, test case development is still primarily a manual process. Because each organization and data pipeline application can be unique, many automated test tools will not create test cases.
Getting Started with Data Pipeline Test Automation
Not all data pipeline tests are suitable for automation. Assess the above situations to determine what types of automation would benefit your test process and how much is needed. Evaluate your test requirements and identify efficiency gains that can be achieved through automated testing. Data pipeline teams who devote considerable time to regression testing will benefit the most.
Develop a business case for automated testing. IT must first make the case to convey the value to the business.
Evaluate the options. After assessing the current state and requirements within the IT department, determine what tools align with the organization’s testing processes and environments. Options may include vendors, open source, internal, or a mix of tools.
Conclusions
As test automation has quickly become an essential alternative to manual testing, more and more businesses are looking for tools and strategies to successfully implement automation. This has led to a significant growth of test automation tools based on Appium, Selenium, Katalon Studio, and many others. However, the data pipeline and data engineers, BI, and quality assurance teams must have the right programming skills to use these automation tools fully.
Many IT experts have predicted that the knowledge gap between testers and developers must and will be reduced continuously. Automated data pipeline testing tools can significantly reduce the time spent testing code compared to conventional manual methods.
As data pipeline development capabilities continue to increase, the need for more comprehensive and modern automated data testing also increases.



