
Click to learn more about author Mike Brody.
When the inventor of the World Wide Web says a new technology is gonna be big, I’m inclined to listen. In this now decade-old TED Talk, W3C Director Sir Tim Berners-Lee makes a convincing case for the critical importance of what he calls “data linking,” a technology that would allow data to be linked the way pages are in Wikipedia. Since that talk, the concept has evolved into a critical component of the next internet revolution, what experts call Web 3.0.
Berners-Lee explains data linking this way: “Like the web of hypertext, the web of data is constructed with documents on the web. However, unlike the web of hypertext, where links are relationships anchored in hypertext documents written in HTML, for data they [link] between arbitrary things” — people, places, ideas, events, activities, and just about anything else you can imagine.
If you were to search this data-linked Semantic Web for the term “Berlin,” for example, instead of getting a list of web pages deemed relevant by a search engine’s algorithm, you’d get a web of entities conceptually linked to Berlin. Berlin would be recognized as a city, which possesses certain properties – such as having districts and population demographics – and you’d be able to drill from “Berlin” into “Turkish Germans” into “Greece” into “The Golden Age of Athens” and so on based on the relationships between those things at a conceptual level, not based on the relationships between web pages about them. “Berlin” would transform from static text into a concept rooted in a contextual web.
This is data ontology in action. In philosophy, ontology is the study of the nature of being; but in information technology it’s “the working model of entities and interactions in some particular domain of knowledge or practices.” This might sound a lot like the definition of a taxonomy, but there’s a key distinction between the two. Taxonomies deal with “is-a” relationships: a cat is a feline, which is a carnivore, which is a mammal, which is a vertebrate, which is an animal. Each node in the taxonomic chain has only one parent; a mammal cannot also be an invertebrate or a fungus. Ontologies, by contrast, deal with “[insert verb here]-a” relationships — “has-a,” “reports-to-a,” “is-also-known-as-a,” and so on. These are all valid relationships between one entity and another, which makes ontologies considerably more complex than taxonomies.
It also makes them more powerful.
The Semantic Web proposed by W3C would be organized according to a standardized Web Ontology Language (OWL) that could then be queried, as one queries a database, using a compatible querying language such as SPARQL. The below SPARQL query references the ontological concept of a person in retrieving a list of names and email addresses.

Person is a pretty useful concept in the domain of social interaction but consider the impact of the global medical community agreeing on a single definition of the term disorder. SNOMED International created SNOMED Clinical Terms (CT), the largest international ontology of medical terms in the world. These standards, combined with other medical interoperability technologies like FHIR, have the power to make critical medical research universally accessible and highly interconnected for better discoverability. Take, for example, this SNOMED concept for a viral upper respiratory tract infection:
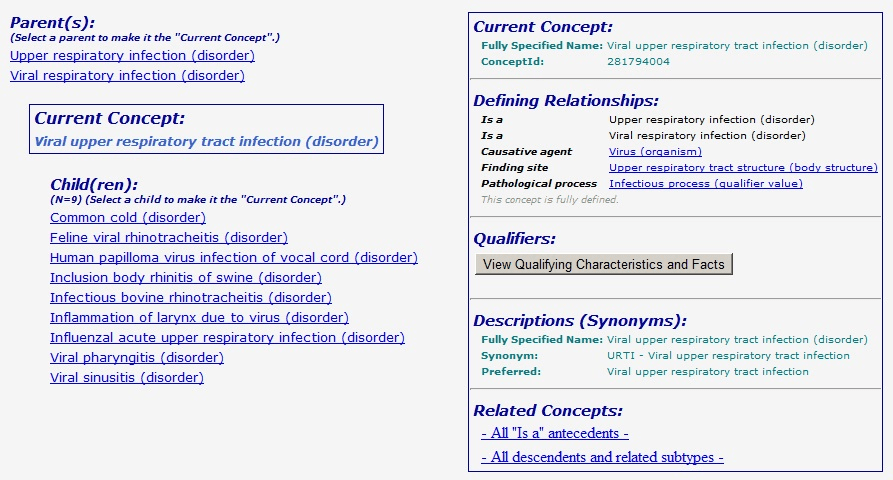
A veterinarian could move from this concept to feline viral rhinotracheitis, and from there view the causative agent, and from there see what other disorders that same causative agent is known to incite, etc. SNOMED-CT has begun to collect and document case studies of its ontological system in action, and evidence suggests the benefit to patients is significant.
If all this sounds eerily familiar, it might be because companies have been leveraging ontological principles for decades as part of their data warehousing operations. More refined data warehouses will include a semantic layer responsible for translating “underlying database structures into business user oriented terms and constructs.” This could involve aliasing data objects and/or fields, enforcing rules around calculation/aggregation, providing descriptions, and reorganizing data to reflect business definitions so that disparate data are mapped to a common ontological scheme. Those who have attempted simply to catalog those definitions know how daunting a task it can be to create something like business logic for an entire company. Imagine what it would take to unite an entire industry.
Still, the upfront cost of creating a data ontology pays off in the long run, which is why so many systems are under development. An ontology’s advantages over more common data structures can be summarized as follows:
- Easy Architectural Changes: Applying structural changes to relational databases is a cumbersome process. Something as simple as changing a property from being single-valued to multi-valued could mean having to add a new table and foreign key reference to the original table, possibly compromising existing queries to it. With an ontology, you could simply modify the semantic concept underpinning the property. For example, where a friend-of-a-friend (foaf) might originally have been defined as a person possessing one name and one email address, it could be redefined as a person possessing multiple names and multiple email addresses, automatically transforming how a foaf query would interpret the available data.
- Inference: Data ontology has the potential to dramatically accelerate machine learning algorithms by introducing pre-defined concepts. An ML algorithm linked to SNOMED data might infer that because a common cold affects the upper respiratory tract structure, and the upper respiratory tract system includes the sinuses and mouth, and the common cold is a disorder, and disorders have symptoms, that a common cold may present with symptoms involving the sinuses and mouth. This is a lot for a machine to deduce without any supervised learning.
- Linking Systems Together: When systems share an ontological language, they can pass data between them with ease. Because ontologies exist externally to IT systems, they can function as bridges between them, serving as a common reference point for diverse operating systems, database types, and applications, eliminating the need for a translation layer in between.
- Data Surfing: Can you imagine being able to surf a dataset the way you surf the web, linking from record to related record? Those accustomed to using BI software are familiar with the concept of “drilldowns” but know that they can only drill so far before hitting the bottom. Instead of drilling strictly in one direction (down, toward more granular records), ontologies would permit people to travel the informational web in all directions, the way they surf the internet. Such a network of ontological associations could lead to powerful data insights.
As the world generates ever-growing volumes of data, I can’t help but think that data ontology will become fundamental to how we organize and distribute it. Sir Tim Berners-Lee has a knack for webs, and he spent a good deal of his TED talk pleading with the audience to ask for linked data. Why would someone with the power and technical ability to create data ontologies do something like that? Because, like any other large-scale operation, it requires buy-in. A critical mass of people need to use an ontology for it to become self-sustaining.
That buy-in, I think, is coming, and it will be interesting to see how it affects BI. Will we be helping analysts query in SPARQL and SNOMED CT one day? With any luck, that day will be in the not-too-distant future.