
In the contemporary landscape of data-driven decision-making, enterprises are increasingly turning to predictive analytics to gain valuable insights into future trends and behaviors. Predictive analytics involves extracting patterns from historical data to forecast future outcomes, enabling organizations to make proactive decisions and optimize their operations. Traditionally, predictive analytics has been performed using standalone machine learning platforms, necessitating data extraction, preprocessing, modeling, and deployment pipelines. However, this approach often introduces complexity, latency, and potential security risks due to data movement across disparate systems.
To address these challenges, there is a growing trend toward integrating predictive analytics directly into database management systems (DBMSs). By embedding machine learning (ML) capabilities within the database, organizations can leverage the power of predictive analytics while minimizing data movement, ensuring data integrity, and streamlining the development lifecycle.
Benefits of In-Database Machine Learning
- Reduced complexity: In-database machine learning helps to streamline the workflow by allowing multiple users from different sources to perform tasks like model training, evaluation, and deployment directly within the database environment.
- Enhanced data security: Embedding ML within the database also helps to minimize security risks associated with data movement from different data sources to target and sensitive information remains within the confines of the database.
- Improved efficiency: Lastly, in-database machine learning helps to minimize data transfer and processing times, leading to faster model development and deployment.
Bridging the Gap Between Data Storage and Analytics
Historically, machine learning and data analysis have functioned in separate spheres, often necessitating cumbersome data transfers between systems. This siloed approach introduces drawbacks like inefficiency, security vulnerabilities, and a steeper learning curve for non-specialists (Singh et al., 2023).
In-database machine learning emerges as a game-changer, integrating machine learning capabilities directly within database management systems (DBMSs). This streamlined approach allows users to perform tasks like model training, evaluation, and deployment entirely within the familiar database environment. By leveraging existing SQL commands and database functionalities, in-database machine learning fosters closer collaboration between data scientists, analysts, and database administrators. Additionally, it empowers a broader range of users to contribute to building and deploying models, as expertise in specialized machine learning languages is no longer a mandatory requirement.
In-database machine learning solutions typically offer a diverse array of built-in algorithms for tasks like classification (e.g., predicting customer churn), regression (e.g., forecasting sales), clustering (e.g., segmenting customers based on behavior), and anomaly detection (e.g., identifying fraudulent transactions) (Verma et al., 2020). This empowers users to tackle a wide range of predictive analytics challenges directly within the database, eliminating the need for complex data movement. Furthermore, these solutions provide robust capabilities for model evaluation and deployment, allowing users to assess model performance and seamlessly integrate them into operational workflows for real-time scoring of new data.
For instance, companies in the manufacturing sector can leverage in-database machine learning to analyze sensor data from equipment and predict potential failures proactively, enabling preventive maintenance (Verma et al., 2020). In the retail industry, in-database machine learning can be used to analyze customer behavior and recommend personalized products or services, leading to increased customer satisfaction and sales (Singh et al., 2023).
Key Features of In-Database Machine Learning
In-database machine learning solutions offer a comprehensive set of features for building and deploying predictive models directly within the database environment:
- Built-in algorithms: No need to start from scratch! In-database machine learning comes equipped with a toolbox of popular algorithms like linear regression, decision trees, and clustering. These algorithms are fine-tuned to work efficiently within your database, saving you time and effort.
| Algorithm | Description |
| Linear Regression | A statistical method for modeling the relationship between a dependent variable and one or more independent variables. |
| Logistic Regression | A regression analysis used for predicting the probability of a binary outcome. |
| Decision Trees | A non-parametric supervised learning method used for classification and regression tasks. |
| Random Forests | An ensemble learning method that constructs a multitude of decision trees during training and outputs the mode of the classes for classification tasks. |
| K-Means Clustering | A clustering algorithm that partitions data points into k distinct clusters. |
- Model training and evaluation: Imagine training your model directly in the database using simple SQL commands. You can tell the system what data to use, what you’re trying to predict, and how to adjust the model. The system then provides feedback on how well your model is performing using clear metrics like accuracy and precision. This built-in evaluation helps you fine-tune your model for optimal results.
- Model deployment: Once you’ve built a great model, you can put it to work right away. In-database machine learning lets you deploy your model directly within the database as a user-defined function (UDF). This means you can get predictions on new data instantly, without needing to move information around or rely on external tools.
- SQL integration: In-database machine learning integrates seamlessly with the SQL you already know. This lets you combine machine learning tasks with your existing database operations. Data scientists, analysts, and database administrators can all work together in the same environment, making the development process smoother and more efficient.
Data Preparation
Data Cleaning
Before proceeding with analysis, it’s crucial to ensure the integrity and quality of the data. In this section, we’ll perform data cleaning operations to remove any null or irrelevant values from the sensor data.

Data Transformation
Data transformation involves reshaping and structuring the data into a format suitable for analysis. Here, we’ll transform the raw sensor readings into a more structured format, aggregating them at an hourly level.
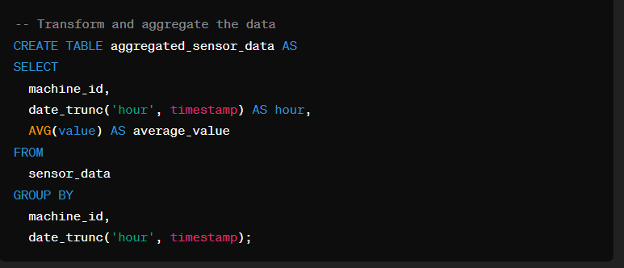
Data Aggregation
Aggregating the data allows us to summarize and condense information, making it easier to analyze trends and patterns. In this snippet, we aggregate sensor data by machine ID and hourly timestamp, calculating the average sensor value for each interval.
These data cleaning, transformation, and aggregation functionalities enhance the comprehensiveness of our analysis and ensure that we’re working with high-quality, structured data for predictive maintenance modeling.
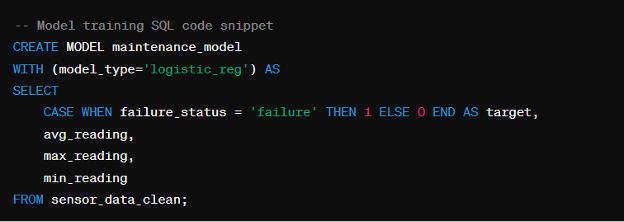
Model Training
With the preprocessed data in hand, we can proceed to train a predictive maintenance model. Let’s say we choose to use a logistic regression model for this task:
Model Evaluation
Once the model is trained, we can evaluate its performance using relevant metrics such as accuracy and ROC curve:

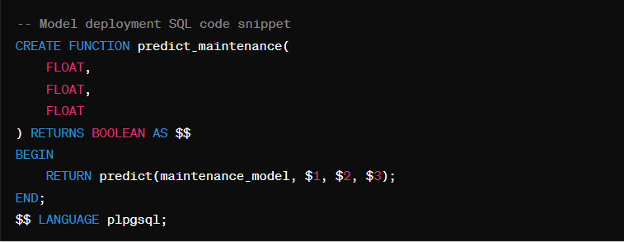
Real-Time Prediction
Finally, we can deploy the trained model as a user-defined function (UDF) for real-time prediction:
Conclusion
In the past, getting insights from data involved a lot of back-and-forth. Information needed to be moved around, analyzed by specialists, and then the results delivered back. This could be slow and cumbersome. But in-database machine learning is changing the game.
Imagine having a powerful toolbox built right into your data storage system. That’s the idea behind in-database machine learning. It lets you create “smart models” directly within your existing database. These models can analyze your data and predict future trends or uncover hidden patterns. It’s like having a crystal ball for your business, all without ever needing to move your data around.
This new approach offers several exciting benefits. First, it allows for much faster decision-making. Traditional methods often involve waiting for data transfers and external analysis, which can take time. In-database machine learning works directly with your data where it’s stored, giving you real-time insights. No more waiting around for results!
Second, in-database machine learning empowers a wider range of people to contribute to data-driven initiatives. Building these smart models no longer requires a Ph.D. in machine learning. By leveraging familiar commands already used in databases, even people without specialized machine learning degrees can participate. It’s like opening the door for a team effort, allowing everyone with valuable knowledge about the data to contribute.
Third, in-database machine learning solutions are built to scale. As your business collects more information, the system can handle it with ease. It’s like a toolbox that expands as you need it, ensuring the system remains effective even as your data grows.
Finally, in-database machine learning keeps your data safe and secure. Instead of moving your data around for analysis, it stays securely locked away within the confines of your database system. This eliminates the risks associated with data transfers and potential breaches.
The applications of in-database machine learning go far beyond traditional examples like predicting equipment failures or customer churn. It can be used for all sorts of amazing things. Imagine online stores that recommend the perfect product for you based on your past purchases, or financial institutions that manage risks more effectively. In-database machine learning even has the potential to revolutionize fields like healthcare and autonomous vehicles.
In essence, in-database machine learning is like giving your data superpowers. It helps businesses unlock the true potential of their information, make quicker and smarter decisions, and stay ahead of the curve in today’s data-driven world.
References:
- Mayo, M. (2023, May 17). In-database machine learning: Why your database needs AI. Towards Data Science.
- Hackney, H. (2023, February 12). Five Reasons Why In-Database Machine Learning Makes Sense. Architecture & Governance Magazine.
- Otto, P. (2022, June 10). A beginner’s guide to PostgresML. Medium.
- Celkis, I. (2022). PostgreSQL for machine learning: A hands-on guide with TensorFlow and scikit-learn. Packt Publishing.
- Singh, A., Thakur, M., & Kaur, A. (2023). A survey on in-database machine learning: Techniques and applications. Expert Systems with Applications, 220, 116822.
- Verma, N., Kumar, P., & Jain, S. (2020, September). In-database machine learning for big data analytics. In 2020 International Conference on Innovative Trends in Communication and Computational Technology (ICTCCT) (pp. 261-265). IEEE. DOI: 10.1109/ICTCCT50032.2020.9218221

