
While Apache Kafka has earned its reputation as a highly capable distributed streaming platform, it also features a bit of complexity when it comes to ensuring that data is stored – and can be retrieved – in the order that you want it to be.
To capture streaming data, Apache Kafka publishes records to a topic, a category or feed name that multiple Kafka consumers can subscribe to and retrieve data. The Kafka cluster maintains a partitioned log for each topic, with all messages from the same producer sent to the same partition and added in the order they arrive. In this way, partitions are structured commit logs, holding ordered and immutable sequences of records. Each record added to a partition is assigned an offset, a unique sequential ID.
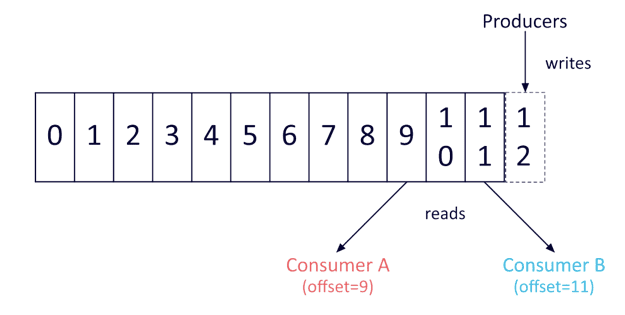
The challenge of receiving data in the order you prefer it in Kafka has a relatively simple solution: a partition maintains a strict order, and will always send data to consumers in the order it was added to the partition. However, Kafka does not maintain a total order of records across topics with multiple partitions.
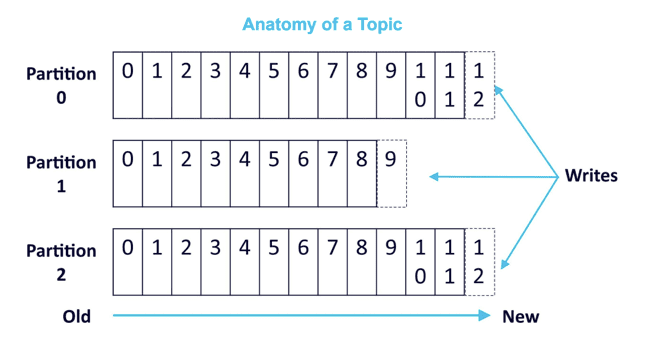
For applications requiring total control of records, the solution is using a topic with just a single partition (this will also limit utilization to a single consumer process per consumer group).
Keep in mind that most applications will not require this level of control, and are better served by the technique of using per-partition ordering alongside data partitioning by key.
Examples of How to Use Apache Kafka Partitioning and Keying
Let’s look at an example of what happens when we send data to multiple partitions. First, we’ll create a topic with 10 partitions, named “my-topic”:

Next, we’ll make a producer and send records containing the numbers “1” through “10”.

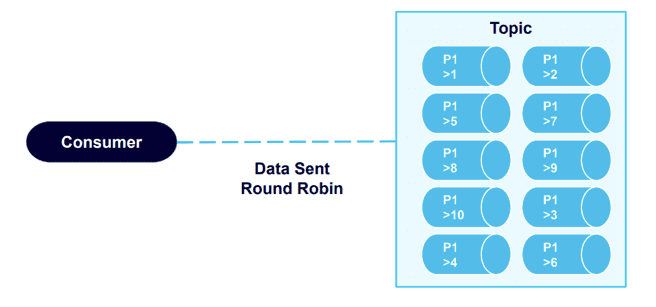
These records are sent to the topic in order, but to ten different partitions. When we use the consumer to read this data from the beginning of the topic, it arrives quite out of order:

This demonstrates the fact that data order is not guaranteed at the topic level – data is retrieved from all partitions in a round robin fashion.
Now let’s create a new example, using a topic with just one partition:

We’ll send the same “1” through “10” data:

This time, we retrieve the data in the order we sent it.
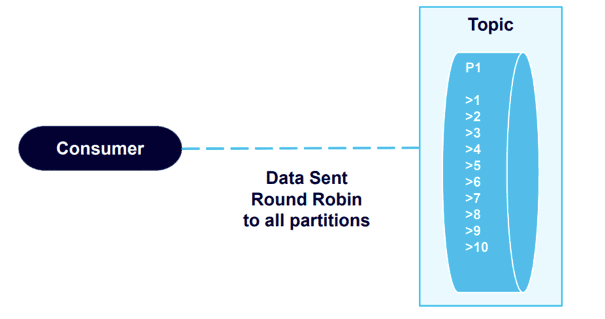
This validates Kafka’s guarantee of data order on the partition level. The producer sends messages in a specific order, the broker writes to the partition in that order, and consumers read the data in that order.
Next, let’s use an example that introduces keying, which allows you to add keys to producer records. We’ll send four messages that include keys to a Kafka topic with two partitions:
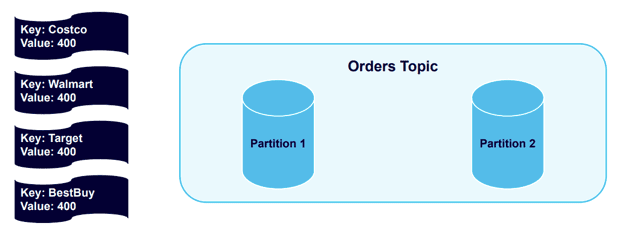
The four different keys – Costco, Walmart, Target, and Best Buy, and hashed and distributed across the cluster into the partitions:

Now we’ll send another four messages:
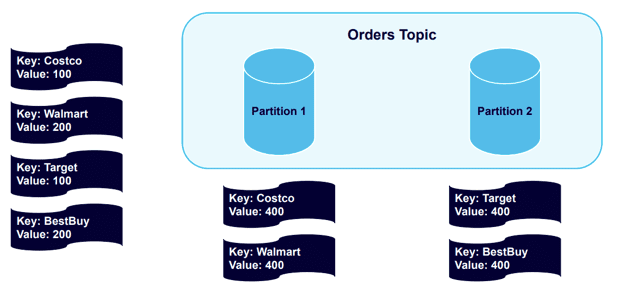
Kafka will send messages to the partitions that already use the existing key:

All Costco or Walmart records go in Partition 1, and all Target or Best Buy records go in Partition 2. The records are in the order that they were sent to those partitions.
Next, let’s see what happens if we add more partitions to the cluster, which we might want to do in order to balance the data in a healthier way.
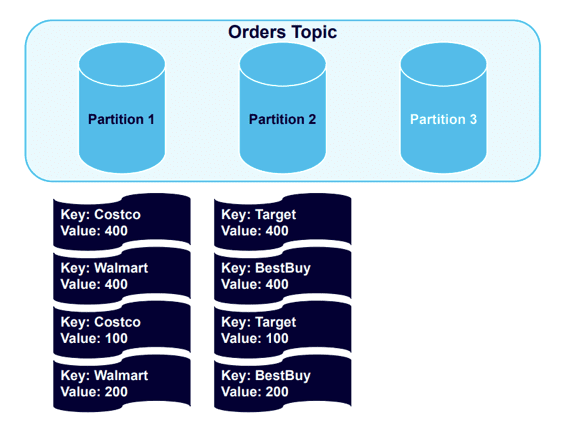
With the new partition added, we’ll trigger a rebalance event:
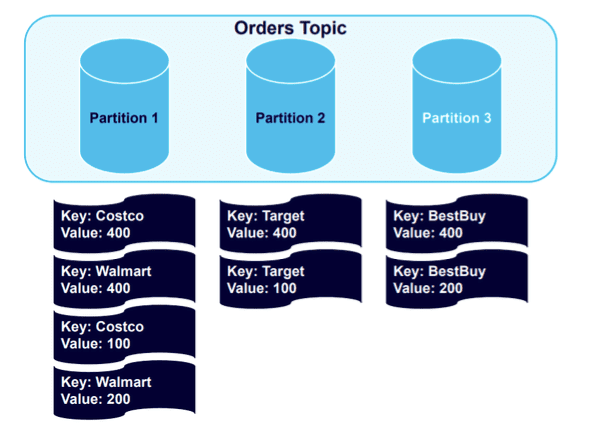
The data remains nicely structured by key, with all Best Buy data balanced to Partition 3. It will remain so if we add four more messages to the topic:
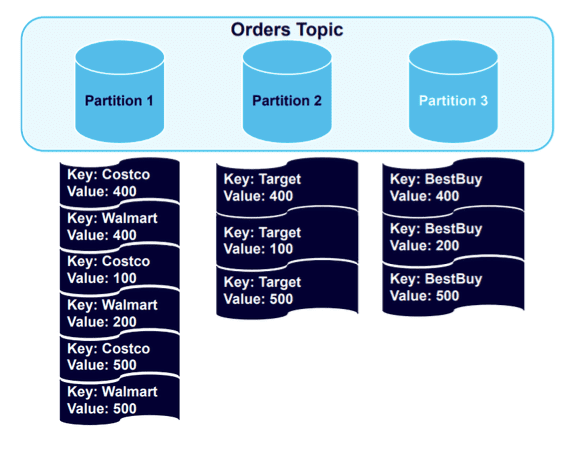
Data goes to the partitions holding the established keys. However, because one partition is holding twice as much data as the others, it makes logical sense to add a fourth partition and trigger another rebalance:
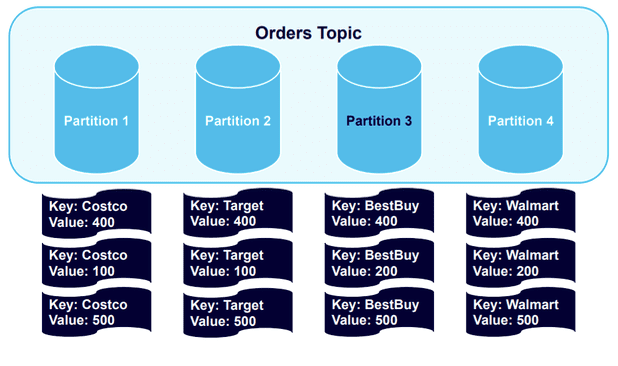
The result is a healthy balancing of the data sets.
Ensuring that Data is Always Sent in Order
There are a number of additional issues that can cause data to arrive out of order in Kafka, including broker or client failures and disorder produced by reattempts to send data. To address these , let’s first take a closer look at the Kafka producer.
Here is a high-level overview showing how a Kafka producer works:
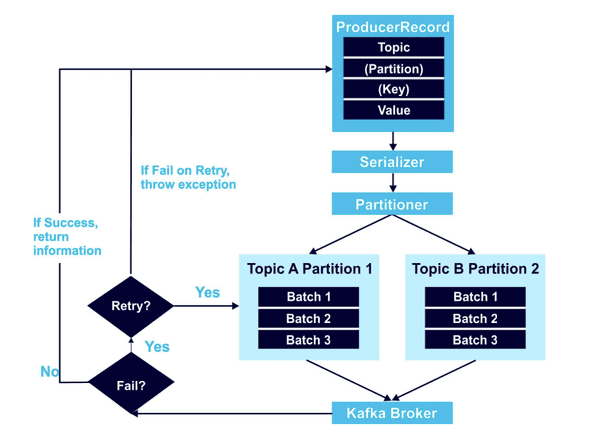
At minimum, a ProducerRecord object includes the topic to send the data to, and a value. It can also include a specified partition to use, and key. At stated in the examples above, I recommend that you always use keys. If you don’t, data will be distributed round robin to any partition with no organization in place. Data from the ProducerRecord is next encoded with the Serializer, and then the Partitioner algorithm decides where the data goes.
The retry mechanism, outlined on the left-hand side of the above diagram, is an area where data order issues can frequently occur. For example, say you attempt to send two records to Kafka, but one fails due to a network issue and the other goes through. When you try resending the data, there’s a risk that data will be out of order, because you’re now sending two requests to Kafka simultaneously.
You can resolve this issue by setting max.in.flight.requests.per.connection to 1. If this is set to more than one (and the retries parameter is nonzero), the broker could fail to write the first message batch, successfully write the second because it was allowed to also be in-flight, and then successfully retry the first batch, swapping their order to one you didn’t intend. In contrast, setting max.in.flight.requests.per.connection to 1 ensures that those requests occur and one after the other and in order.
In scenarios where order is crucial, I recommend setting in.flight.requests.per.session to 1; this ensures that additional messages won’t be sent while a message batch is retrying. However, this tactic severely limits producer throughput, and should only be used if order is essential. Setting allowed retries to zero may seem like a possible alternative, however, if the impact on system reliability makes it a non-option.
Achieving “Exactly-Once Message Delivery”
Apache Kafka includes three different message delivery methods, each with its own guaranteed behaviors:
- At-Once Message Delivery: This method will either deliver a message batch once, or never. This eliminates the risk of resending the same messages, but allows them to be lost as well.
- At-Least-Once Message Delivery: This method will not stop until messages are delivered. While delivery always succeeds and no messages are lost, they can be delivered multiple times.
- Exactly-Once Message Delivery: This method guarantees delivery of all messages, and that each is delivered only one time. While failures and retries will occur, Exactly-Once Message Delivery takes extra steps to ensure a single successful delivery.
Obviously, Exactly-Once Message Delivery is ideal for preserving data order.
Putting Exactly-Once Message Delivery into practice requires utilizing three components: an idempotent producer, transactions across partitions, and a transactional consumer.
1) Idempotent producer
Producer idempotency can cause messages to persist through just a single process, preventing retry issues. Activating idempotency adds a producer ID (PID) and a sequence ID to each Kafka message. When a broker or client failure occurs and a retry is attempted, the topic only accepts messages with never-before-seen producer and sequence IDs. Idempotency is further assured by the broker, which deduplicates all messages the producer sends automatically.
2) Transactions across partitions
Transactions can make sure that each message is processed exactly once. This allows a selected message to be transformed and atomically written to multiple topics or partitions, along with an offset tracking consumed messages.
The state of atomic writes is maintained by the transaction coordinator and transaction log (introduced in Apache Kafka v0.11). The transaction coordinator is similar to the consumer group coordinator: each producer has an assigned transaction coordinator, which is responsible for assigning PIDs and managing transactions. The transaction log is a persistent record of all transactions acting as the state store for the transaction coordinator.
3) Transactional Consumer
To force a transactional consumer to read only committed data, set isolation.level to read_committed (by default, the isolation level is read uncommitted.)
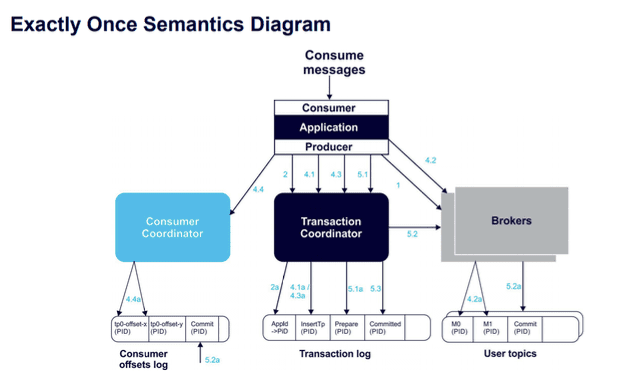
Steps of a Kafka Transaction Workflow for Exactly-Once Message Delivery
The following diagram captures the Kafka transaction workflow steps needed to achieve Exactly-Once Message Delivery.
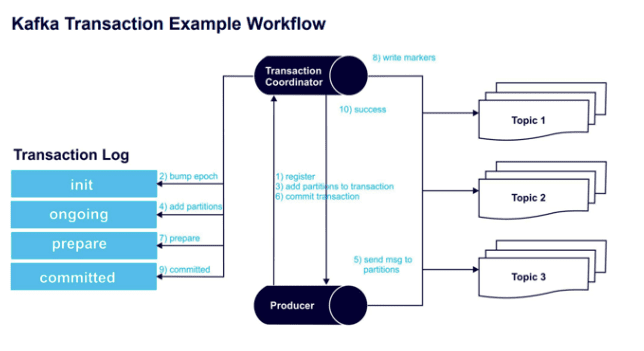
Step 1 – initTransactions() registers a transaction ID (a unique persistent producer ID) with the transaction coordinator.
Step 2 – The coordinator bumps up the epoch of the producer ID (ensuring there is just one legitimate active instance of the producer). Writes from previous instances of that PID are no longer accepted.
Step 3 – Before sending data to a partition, the producer adds a new partition with the coordinator.
Step 4 – The coordinator stores each transactions’ state in memory and writes it to the transaction log.
Step 5 – The producer sends the messages to the partitions.
Step 6 – The producer begins a commit transaction, causing the coordinator to initiate its two-phase commit protocol.
Step 7 – (Commit protocol phase 1) The coordinator prepares the commit by updating the transaction log.
Step 8 – (Commit protocol phase 2) The coordinator writes transaction commit markers to topic partitions involved in the transaction.
Step 9 – The coordinator marks the transaction as committed.
Step 10 – The “Exactly-Once Message Delivery” transaction is a success.
Below is a more technical architecture diagram of this process:
By understanding how Apache Kafka orders data and leveraging the above techniques, you can make sure your data or your application remain in good working order.



