
Click to learn more about author Martyna Pawletta.
The availability of scientific datasets in Google BigQuery opens new possibilities for the exploration and analysis of public life sciences data. The Google Cloud Platform (GCP) provides a place where SQL queries can be easily and intuitively created in order to explore huge datasets extremely fast. Here we present a practical example of how you can work with them effectively, on BigQuery stored datasets, using the open-source Analytics Platform.
In this blog post, we will cover a use case relevant for life sciences research. We will focus on answering some questions from the area of pharmaceutical research by linking and querying different datasets stored in BigQuery.
But don’t worry: Even if you’re not a life science expert, you still might find it useful to see how easy it can be to connect to BigQuery, construct complex queries without needing to write SQL, and explore the results of the queries using the Analytics Platform.
SciWalker Open Data
This example was inspired by the SciWalker Open Data sets that were added to Google BigQuery and announced at the American Chemical Society meeting in San Diego this year. You can find the abstract in the Chemical Information Bulletin, page 86-87, here.
SciWalker is a comprehensive resource that contains chemistry-related data like molecules, nucleotides, and peptide sequences (overall 211 million unique molecules) that are linked to additional scientific information. The datasets also include clinical and drug-related data with links to different ontologies that allow us to compare data coming from different data sources using different wording.
- Set up a BigQuery Account first! You’ll find a detailed description on how to set up your BigQuery account in this blog article by Emilio Silvestri.
Once your BigQuery account is configured, you can create your first query using the other database nodes, as demonstrated in the short example below. These nodes let you create SQL queries in a visual way, without needing to write SQL yourself (although you can add SQL if you want/need to).
- To learn more about nodes provided for databases, check out our Hub, where you’ll also find more example workflows.
- Additionally, you will find documentation, the Database Extension Guide, here.
Selecting and Downloading Data
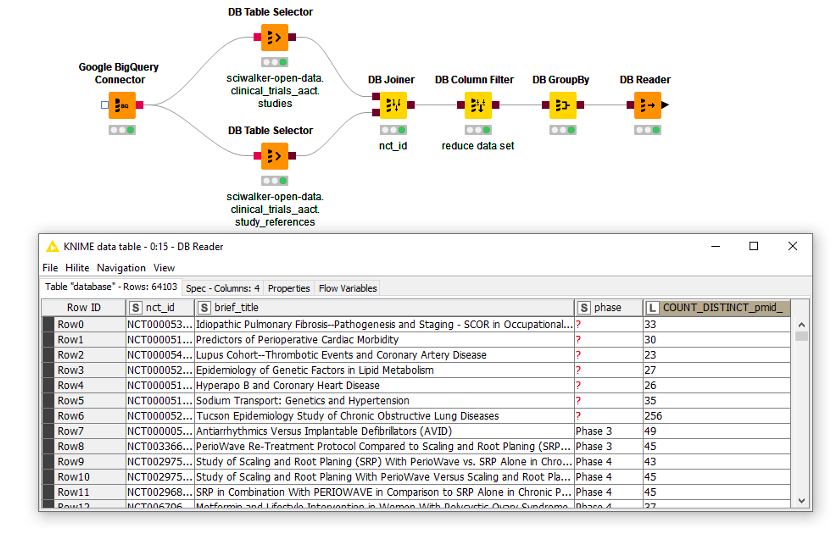
In the short workflow below, we select data from two tables: One contains general information about clinical trials and the other references to literature that has been linked to those clinical trials. They can be joined using the DB Joiner node on the nct_id column and filtered for certain columns like IDs, title, study phase, and the PubMed ID from the reference table using the DB Column Filter node. Additionally, we group the data according to nct_id and count how many PubMed references have been registered per study.
In the last step, the DB Reader node is used in order to execute the query and download the data into a table.
Time to Play
Now that you’ve connected to a BigQuery resource and queried it with the database nodes, we will demonstrate how to interactively explore the data in a few simple steps. In each step you can use an interactive view to select the data you’re interested in, which are then used to create further queries and pull the matching data from BigQuery – and all this without writing code!

Fig. 2: The workflow “Explore Scientific Data Stored on BigQuery.”
Step 1
In the very first step of our exploration journey, we retrieve a list of diseases that are included in the clinical data (clinicaltrials.gov) datasets and standardized according to the disease ontology that is part of the SciWalker data collection. We then use this list to create an autocomplete menu, which we can use to select the disease we want to investigate further. For example, here we will investigate schizophrenia.
Step 2
Selecting a disease brings us – after some data querying, joining, wrangling, and preprocessing – to the next step, where we can explore compounds that have been registered for clinical studies on schizophrenia. We calculate some chemical properties and merge the data with additional information about the clinical trial. In a second table, PubMed references from each study are visible.
To make the view even more interactive, we added web links to the study and reference IDs that will bring you directly to the web pages describing those studies/references.
Let’s select “methotrexate”here, which is known as a chemotherapy agent and immune system suppressant, and see what happens in the next step.
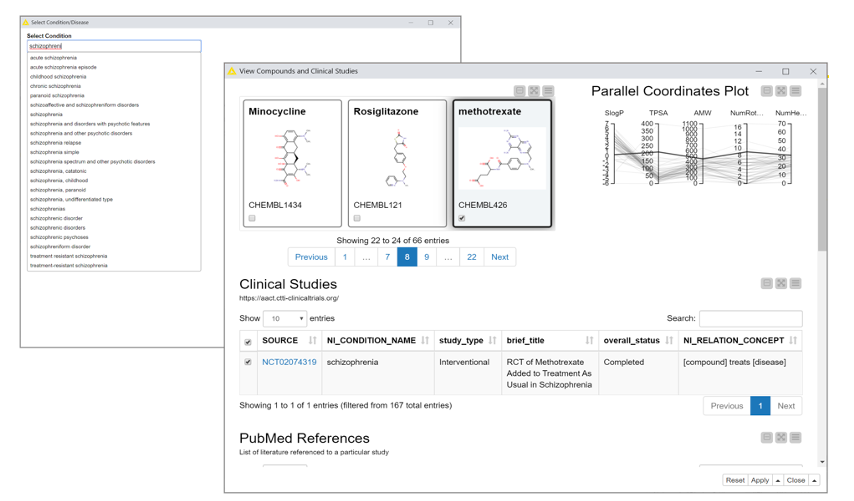
Fig. 3: Interactive view, with additional web links to the study and reference IDs that bring you directly to the web pages describing those studies/references.
Step 3
Here we once again take advantage of the ontologies available in SciWalker.
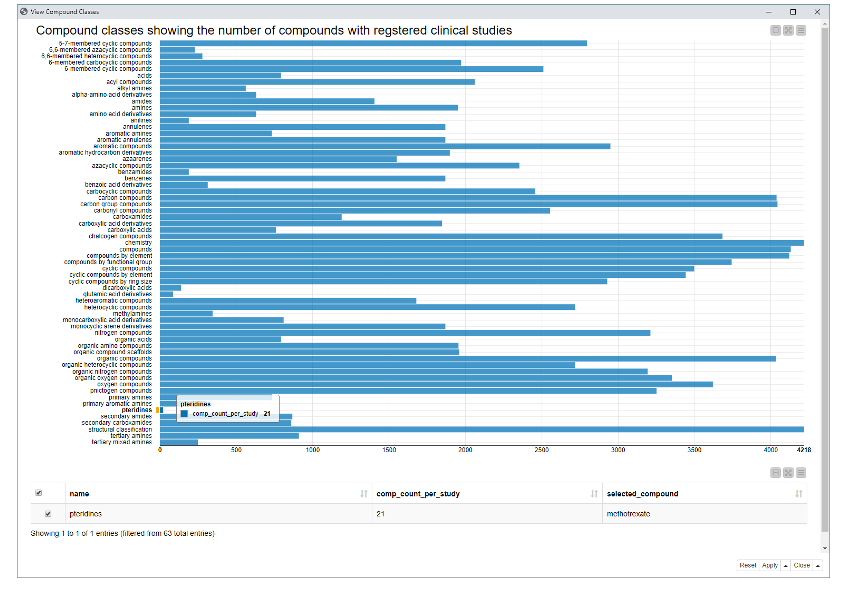
The view below shows which chemical classes “methotrexate”belongs to, along with how many other compounds from each of those chemical classes have been registered for clinical studies. Here, one class should be selected to go to the next step. We selected “pteridines,” which seems to be not that popular (with only 21 compounds registered for clinical studies). In the next step, let’s check which 21 compounds those are and for which diseases the studies have been conducted.
Step 4
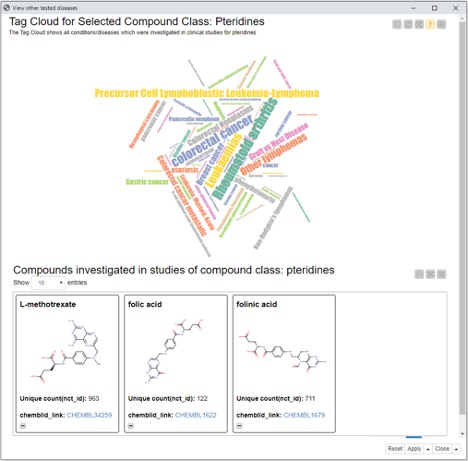
This view shows a tag cloud with disease and condition names for which studies have been registered for compounds in the selected compound class (here: pteridines). When you select a disease from the tag cloud, the list of compounds in the selected class that are associated with that disease are displayed in the table below.
When we select “Rheumatoid arthritis,” we see that within the class of pteridines three compounds are linked. We see that methotrexate has been tested for schizophrenia and rheumatoid arthritis.
Step 5
The last view shows all compounds found in the clinical trials dataset that have been tested for both schizophrenia and rheumatoid arthritis. If you are curious which compounds those are, check out the workflow on the Hub here.
Prerequisites to run the example:
- BigQuery account
- Simba Driver
- KNIME Analytics Platform (4.1)
- KNIME Big Data Extension
- KNIME Community Extensions – Cheminformatics (including RDKit)
Wrapping Up
In this blog post, we highlighted how to interactively explore and analyze scientific data using Google BigQuery and KNIME Analytics Platform together. We showed that combining these two tools allows us to take advantage of the breadth of data available in BigQuery using the interactive query construction, data analysis, and visualization capabilities in the Analytics Platform. Maybe this sparks further ideas or questions or even allows you to create new hypotheses?
Though we’ve focused on life sciences data here, the combination of an analytics platform and Google BigQuery can be applied in many different fields, so feel free to give it a try no matter what your use case or industry!
If this makes you curious, start playing with the workflow demonstrated today or look for other examples here on the Hub.
If you want to explore and do more experiments using freely available scientific datasets on Google BigQuery, check out the Marketplace. There is a lot more data to explore!