
Organizations all over the world – both profit and nonprofit – are looking at leveraging data analytics for improved business performance. Findings from a McKinsey survey indicate that data-driven organizations are 23 times more likely to acquire customers, six times as likely to retain customers, and 19 times more profitable [1]. Research by MIT found that digitally mature firms are 26% more profitable than their peers [2]. But many companies, despite being data-rich, struggle to implement data analytics due to the conflicting priorities between business needs, available capabilities, and resources. Research by Gartner found that over 85% of data and analytics projects fail [3] and a joint report from IBM and Carnegie Melon shows that 90% of data in an organization is never successfully used for any strategic purpose [4].
With this backdrop, we introduce the “data analytics fabric (DAF)” concept, as an ecosystem or a structure that enables data analytics to function effectively based on (a) business needs or objectives, (b) available capabilities such as people/skills, processes, culture, technologies, insights, decision-making competencies, and more, and (c) resources (i.e., components that a business needs to operate the business).
Our primary goal of introducing the data analytics fabric is to answer this fundamental question: “What is required to effectively build a decision-enabling system from Data Science algorithms to measure and improve business performance?” The data analytics fabric and its five key manifestations are shown and discussed below.
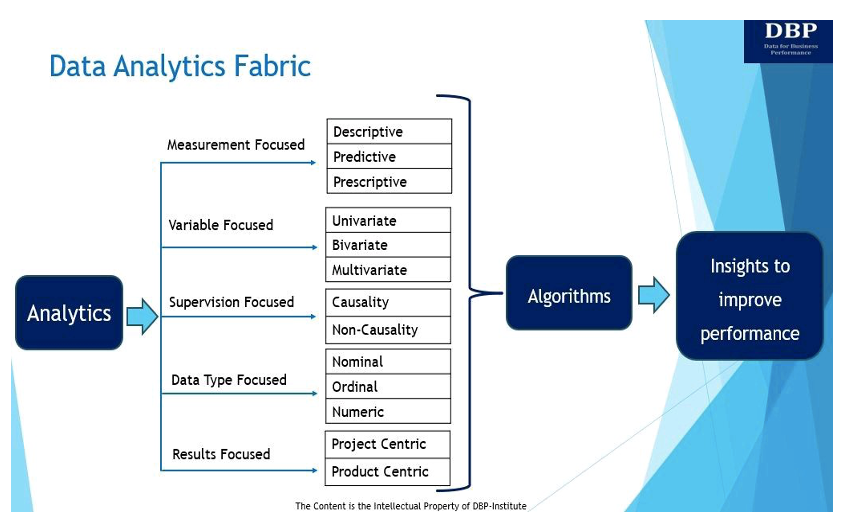
1. Measurement-Focused
At its core, analytics is about using data to derive insights measure and improve business performance [5]. There are three main types of analytics to measure and improve business performance:
- Descriptive analytics asks the question, “What happened?” Descriptive analytics is used to analyze historical data to identify patterns, trends, and relationships using exploratory, associative, and inferential data analysis techniques. Exploratory data analysis techniques analyze and summarize data sets. Associative descriptive analysis explains the relationship between variables. Inferential descriptive data analysis is used to infer or conclude trends about a larger population based on the sample data set.
- Predictive analytics looks at answering the question, “What will happen?” Basically, predictive analytics is the process of using data to forecast future trends and events. Predictive analysis can be conducted manually (commonly known as analyst-driven predictive analytics) or using machine learning algorithms (also known as data-driven predictive analytics). Either way, the historical data is used to make future predictions.
- Prescriptive analytics helps to answer the question, “How can we make it happen?” Basically, prescriptive analytics recommends the best course of action for moving forward using optimization and simulation techniques. Typically, predictive analysis and prescriptive analytics go together because predictive analytics helps find potential outcomes, while prescriptive analytics looks at those outcomes and finds more options.
2. Variable-Focused
Data can also be analyzed based on the number of variables available. In this regard, based on the number of variables, the data analytics techniques can be univariate, bivariate, or multivariate.
- Univariate Analysis: Univariate analysis involves analyzing the pattern present in a single variable using measures of centrality (mean, median, mode, and so on) and variation (standard deviation, standard error, variance, and so on).
- Bivariate Analysis: There are two variables wherein the analysis is related to cause and the relationship between the two variables. These two variables could be dependent or independent of each other. The correlation technique is the most used bivariate analysis technique.
- Multivariate Analysis: This technique is used for analyzing more than two variables. In a multivariate setting, we typically operate in the predictive analytics arena and most of the well-known machine learning (ML) algorithms such as linear regression, logistic regression, regression trees, support vector machines, and neural networks are typically applied to a multivariate setting.
3. Supervision-Focused
The third type of data analytics fabric deals with training the input data or independent variable data that has been labeled for a particular output (i.e., the dependent variable). Basically, the independent variable is the one the experimenter controls. The dependent variable is the variable that changes in response to the independent variable. The supervision-focused DAF could be one of two types.
- Causality: Labeled data, whether generated automatically or manually, is essential for supervised learning. Labeled data allows one to clearly define a dependent variable, and then it is a matter of the predictive analytics algorithm to build an AI/ML tool that would build a relationship between the label (dependent variable) and the set of independent variables. The fact that we have a distinct demarcation between the notion of a dependent variable and a set of independent variables, we allow ourselves to introduce the term “causality” to best explain the relationship.
- Non-Causality: When we indicate “supervision-focused” as our dimension, we also mean the “absence of supervision,” and that brings the non-causal models to the discussion. The non-causal models deserve mention because they do not require labeled data. The basic technique here is clustering, and the most popular methods are k-Means and Hierarchical Clustering.
4. Data Type-Focused
This dimension or manifestation of the data analytics fabric focuses on the three different types of data variables related to both the independent and dependent variables that are used in the data analytics techniques for deriving insights.
- Nominal data is used for labeling or categorizing data. It does not involve a numerical value and hence no statistical calculations are possible with nominal data. Examples of nominal data are gender, product description, customer address, and the like.
- Ordinal or ranked data is the order of the values, but the differences between each one is not really known. Common examples here are ranking companies based on market capitalization, vendor payment terms, customer satisfaction scores, delivery priority, and so on.
- Numeric data needs no introduction and is numerical in value. These variables are the most fundamental data types that can be used to model all types of algorithms.
5. Results-Focused
This type of data analytics fabric looks at the ways in which business value can be delivered from the insights derived from analytics. There are two ways in which business value can be driven by analytics, and they are through products or projects. While products may need to address additional ramifications around user experience and software engineering, the modeling exercise done for deriving the model will be similar in both the project and product.
- A data analytics product is a reusable data asset to serve the long-term needs of the business. It collects data from relevant data sources, ensures data quality, processes it, and makes it accessible to anyone who needs it. Products are typically designed for personas and have multiple lifecycle stages or iterations at which product value is realized.
- A data analytics project is designed to address a particular or unique business need and has a defined or narrow user base or purpose. Basically, a project is a temporary endeavor intended to deliver the solution for a defined scope, within budget and on time.
The world’s economy will dramatically transform in the coming years as organizations will increasingly use data and analytics to derive insights and make decisions to measure and improve business performance. McKinsey found that companies that are insight-driven report EBITDA (earnings before interest, taxes, depreciation, and amortization) increases of up to 25% [5]. However, many organizations are not successful in leveraging data and analytics for improving business outcomes. But there is no one standard way or approach to deliver data analytics. The deployment or implementation of data analytics solutions depends on business objectives, capabilities, and resources. The DAF and its five manifestations discussed here can enable analytics to be deployed effectively based on business needs, available capabilities, and resources.
References
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-their-peers/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, “Analytics Best Practices”, Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth




