Click to learn more about author Thomas Frisendal.
Now is a good point in time to look at best practices in database design for SQL databases. Are there things that could have been easier to do if the SQL designers had had absolute foresight? Of course, the answer is yes. But what is most important is what could really have made a big difference.
The Evolution of SQL —Which Traits Are We Waiting for?
In general terms, the SQL standard has grown by embracing many issues that materialized over the years. Let me just mention XML, time datatypes, and multi-dimensional as examples of useful adaptations. For “bread and butter” databases, SQL generally works fine, but some things are worth discussing:
- The need for surrogate keys as well as the complexity of handling concatenated (business) keys indicate that the concepts of keys and scope of such keys could need a makeover
- The scope of keys is also worth a discussion — in the graph space, people are quite happy with the RDF concept of IRIs (Internalized Resource Identifiers). IRIs are used a lot, with a global scope. In the SQL communities, GUID’s are used for similar purposes
- (Foreign) key relationships could have a stronger role to play in the SQL paradigm — actually, it is not relationships between keys, but relationships between business object types that matter
- This touches upon the matters of normalization (and controlled de-normalization), which are very much parts of best practices in SQL database design
Between the four different issue groups mentioned above, there is one common denominator: temporality. This could also be stated as “handling record-keeping properly over time” in more everyday terms — addressing business needs that we have attempted to solve by way of data warehouses and data lakes in demanding, data-intensive industries such as government, finance, pharmaceuticals, tech, and science.
Data Vaults and Anchor Models — Ensemble
Many heavy-duty databases in demanding industries have found their ways to two somewhat related modeling approaches:
- Data Vault Modeling: Originally developed by Dan Linstedt for US Defense
- Anchor Modeling: Open source project originating in Sweden, by Lars Rönnbäck
Today the two communities (5000-plus DV modelers) and a 3-digit number of anchor modelers (primarily in Sweden and the Netherlands) present themselves as part of the “Ensemble — Modeling for the modern data warehouse.”
The principal motivation for modeling databases in these ways can be summarized in three words:
- Scalability (petabyte levels)
- Temporality (uni-, bi-, and more)
- Resilience (towards structural and terminological changes)
Anchor Modeling
I will focus on data vault modeling, but before doing that — some comments on anchor modeling:
- Anchor modeling has a good website for reference
- There is a free, online modeling tool here
- You can get online training here
Anchor modeling is described by Lars Rönnbäck like this:
“Anchor modeling is an open source database modeling technique built on the premise that the environment surrounding a data warehouse is in constant change. A large change on the outside of the model will result in a small change within. The technique incorporates the natural concepts of objects, attributes, and relationships, making it easy to use and understand. It is based on the sixth normal form, resulting in a highly decomposed implementation, which avoids many of the pitfalls associated with traditional database modeling. Thanks to its modular nature, the technique supports separation of concerns and simplifies project scoping. You can start small with prototyping and later grow into an enterprise data warehouse without having to redo any of your previous work.”
“Even though its origins were the requirements found in data warehousing, it is a generic modeling approach, also suitable for other types of systems. Every change is implemented as an independent non-destructive extension in the existing model. As a result, all current applications will remain unaffected. Changes in the input to and output from the database can thereby be handled asynchronously, and all versions of an application can be run against the same evolving database. Any previous version of the database model still exists as a subset within an anchor model.”
Data Vault Modeling: A Brief Overview
Although data vault modeling uses a different terminology and sports some different representations, the intentions are much the same. A good comparison can be found here.
The authoritative sourcebook for data vault is Building a Scalable Data Warehouse with Data Vault 2.0 by Daniel Lindstedt and Michael Olschimke (Morgan Kaufmann, 2016).
I recommend visiting these three websites when trying to get an overview of data vault modeling:
The basic building blocks are:
- “Hubs” (the core of the record of a business object type)
- “Satellites” (information about attributes of business object types)
- “Links” (connections between hubs and satellites)
Here is a diagram of a simple data vault model (DDL-level examples will follow):
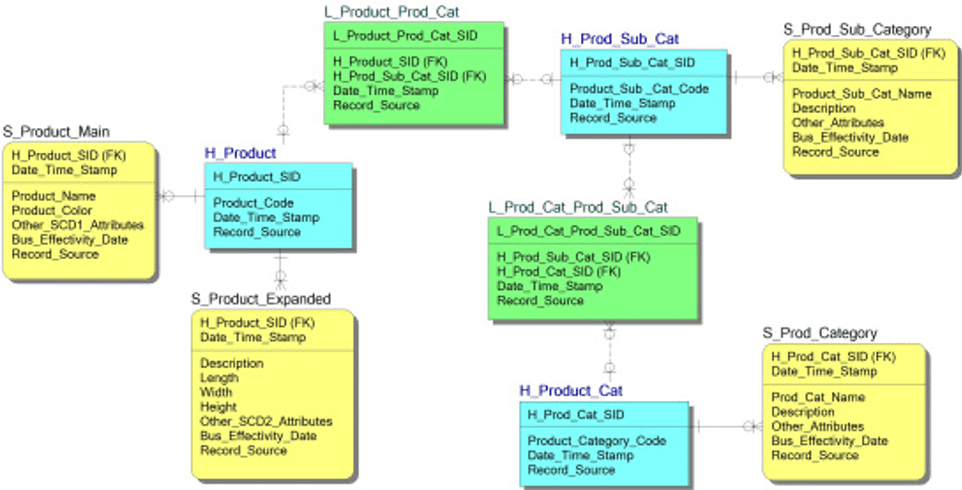
Hans Hultgren is a well-known data vault trainer and “evangelist” working with Genesee Academy and others.
Note that:
- There can be multiple hubs for a given business object type (if it originates in more than one system)
- There can be multiple satellites for a given business object type (if there are multiple source systems and or multiple patterns of change across them). Data vault generally seeks to “bundle” data, which shares update patterns (and timelines) into one table
- All hubs, links, and satellites are individual tables in SQL
- Data vault databases typically work with hashkeys to isolate versions, etc.
(In anchor modeling, the choice is always sixth normal form with individual tables for everything — and in “concurrent-temporal” modeling, only inserts are being done in the database).
For a good intro, read Dan Linstedt’s post about the Northwind database represented as a data vault. If that is not enough for you, then I’d recommend THE book about data vault, Building a Scalable Data Warehouse with Data Vault 2.0, mentioned up above.
The data vault 2.0 book (referenced above) has a number of extensions to the terminology presented so far. Here follows a list of the most important ones together with an explanation, where necessary.
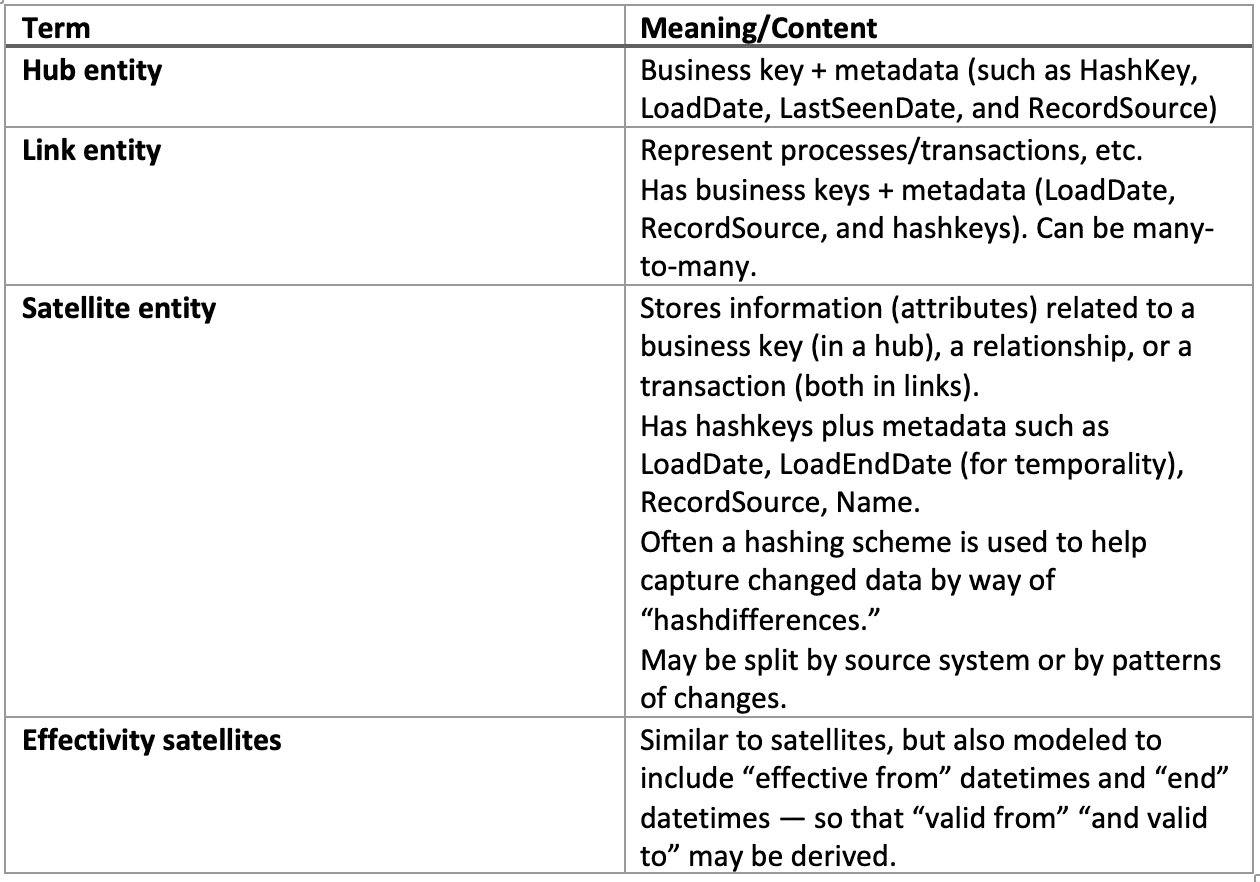
Many more data vault specific terms and constructs exist, but the format of a blog post does not have room for them! Follow the links above, and read the book mentioned in this post for more.
Data vaults are frequently built by way of template-based data vault generators available on the market — here is a handful of them:
- Vaultspeed
- WhereScape
- Visual Data Vault
- Datavault Builder
- TEAM
In the data vault book mentioned above (2.0, the current version of the book), data vaults may be constructed (using “point in time” tables) to eliminate updates (of, for instance, the end datetimes), leading to insert-only loads, which are the most performant.
Data Vault DDL Examples
The data vault book we’ve referenced several times, Building a Scalable Data Warehouse with Data Vault 2.0, has an accompanying site where you can download a large collection of code. You will have to purchase the book to get access. I have handpicked a few examples of CREATE TABLE statements below to give you a flavor of the complexity of the table definitions in a data vault:
A simple hub (anchor point for AirlineID):

A slightly complex hub (supporting a concatenated business key):

A “payload” satellite describing airports of origin:

A link table (linking flights, carriers, aircraft, dates, origins, and destinations):

An effectivity satellite:

Lessons Learned from Building Large Databases in SQL
To wrap this up: What, then, can we carry over as additional business requirements for making an even better database language than what SQL is today?
Clearly, the basic data vault constructs, separating a business entity into hub(s) and satellites, handle several issues pertaining to:
- Keys
- Updates (potentially in different source systems)
The explicit support of relationships as physical tables (“links”) is also targeted at handling keys (foreign in SQL terms) and updates (also potentially in different source systems).
It is fair to say that we may conclude that we must solve the issues related to the handling of keys:
- Identity and uniqueness
- Persistent keys
- Concatenated business keys
- Foreign keys and their relationship to relationships
A targeted, intuitive, and flexible approach must be designed (instead of decomposing the issues into several physical database objects).
Temporality is also a major driver behind data vault and anchor modeling:
- Load datetime stamps
- Change detection
- As is versus as of (versions)
- Effective from and to
- Schema change handling
And, finally, “record-keeping” is also explicitly addressed in the complex data modeling practices described above:
- Load datetime stamps
- Source tracking
- Change detection
- Load history
Not explicitly visible, but certainly a major driver behind data vault is the need for speed in loading data. Users are in need of petabyte-scale databases, and they do insist on fast load and fast queries.
An interesting thought is that the metadata models inside those data vault generators probably resemble (parts of) a 6th normal form data model relatively closely. Certainly, that is also the case for anchor modeling.
Can we solve these challenges in new manners? Yes, we can! A new language (such as the coming Graph Query Language, GQL) can be designed to support the modeling issues listed above in straightforward, to the point constructs that are intuitive and effectively handle those requirements, behind the scenes and with good performance. In parallel with the physical database objects, the DBMS must be aware of the “deep structures” of semantics that lie behind the data model.



