
Click to learn more about author Thomas Frisendal.
“Complete Consistence” Drives Temporality, … And What Else?
In August I published a blog post called The Future History of Time in Data Models. The short version of that story is that if you aim for “Complete Consistence for Temporal Extensions”, you need to work on the most atomic level, which is a completely denormalized (6NF) structure. Such a structure is also known as a graph:

The lesson learned is that what drives the need for support of temporality for any property, is nothing else but business requirements. In other words, there are no structural imperatives, which may force e.g. Kennel Code, Kennel Name and Kennel Location to share a timeline – even if the diagram suggests so. The reasons for this are related to functional dependencies, identity and uniqueness. If, in the diagram above, Kennel Location was given an explicit identity by itself (e.g. Official Street Address), the case would be different.
Notice the verbal appearance of the graph data model. The relationship names is the secret sauce, also for functional dependencies.
That temporality feels at home in 6NF implies that, in consequence, similar arguments may be raised for other kinds of property relationships (dependencies). As a matter of principle.
The Schism between Data Modeling and Reality
Why did it take us so long to realize that the “deep structure” is so important, even in a simple database? Which metaphors paved the way for the later data model architectures?
This nice Checheng wood bucket bento from Taiwan illustrates one of the early metaphors used for a database: “A bucket of data”.

What we had to do was to find ways of “pouring data in and out of the data bucket”. Getting data in was maybe not the difficult part, but organizing them and getting them out again proved to be an intellectual challenge. Database was hence a radical novelty, and we have always had problems with those. For starters, we did expect databases to be able to do, what we were used to be able to do for many years, using magnetic tapes and punch cards:
- Search
- Sort
- Merge
- Aggregate
- Report
Remember, this is back in the 60’s and early 70’s. System construction was specified using manual templates for systems flowcharting diagramming such as the one on the photo below. They did not have a database stencil on them, but they had: Magnetic tape, punched tape, card deck, card file and the newcomers (from the “clouds of 70’s”) online storage and keying by magnetic drum or magnetic disc:
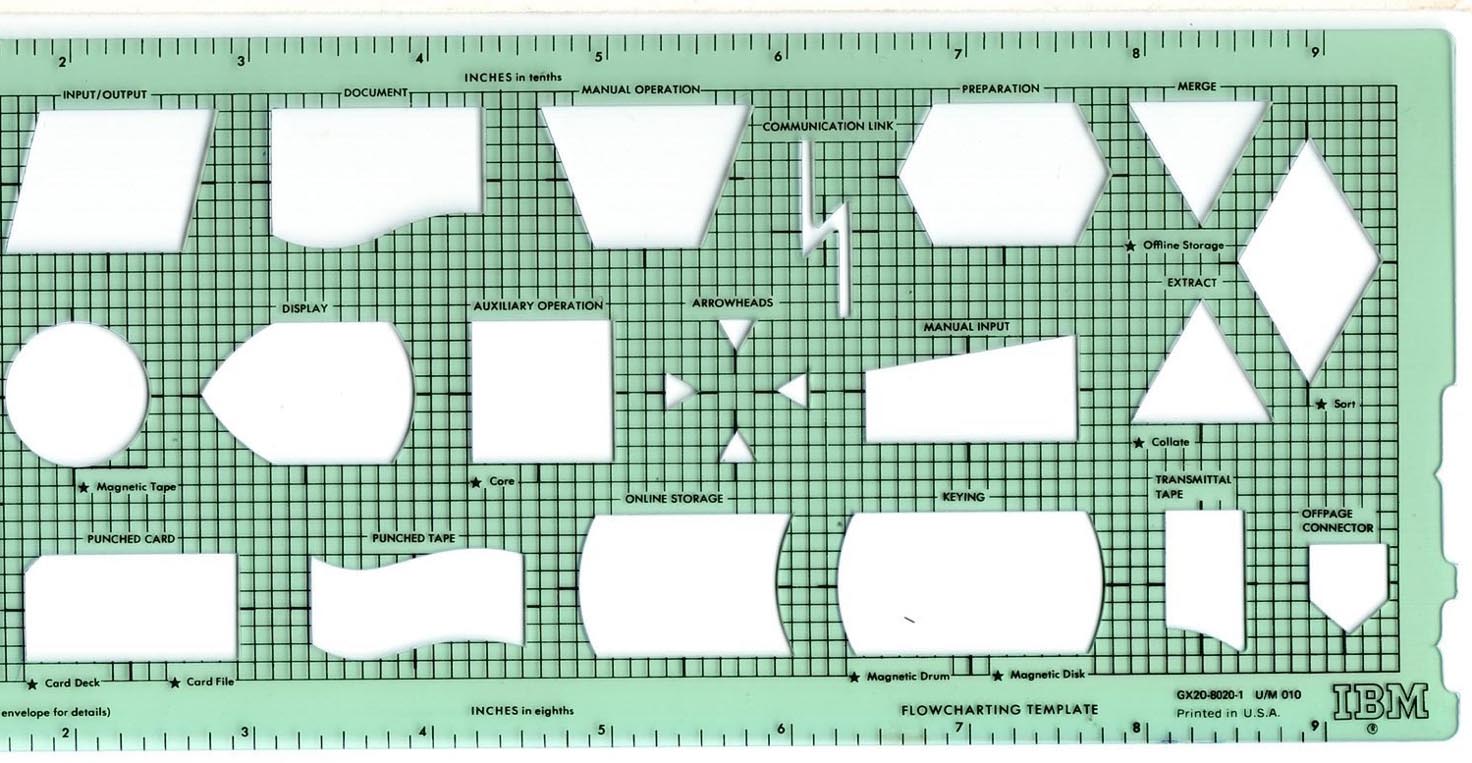
So, we sharpened our pencils and got going!
But the magnetic discs added a joker: Random access! What kind of new “behaviors” could a database “system” perform, based on “random” (direct) disk access?
In grave existential situations like that, we humans tend to look for the apparently safe ways out. One of my favorite professors, Edsger Dijkstra formulated this very well in a lecture note (On the cruelty of really teaching computing science) from the Univ. of Austin, TX, back in 1988:
“It is the most common way of trying to cope with novelty: by means of metaphors and analogies we try to link the new to the old, the novel to the familiar. Under sufficiently slow and gradual change, it works reasonably well; in the case of a sharp discontinuity, however, the method breaks down: though we may glorify it with the name “common sense”, our past experience is no longer relevant, the analogies become too shallow, and the metaphors become more misleading than illuminating. This is the situation that is characteristic for the “radical” novelty.”
Mathematics to Battle the Radical Novelties
In our case (database), the safe haven was conceived to be that of mathematics. Set algebra (for relational), formal logic and later type hierarchies and inheritance etc.
The disconnect between mathematical metaphors (like abstract types) and computing reality later proved to be enormous. State of the art in the 70’s was data structure diagrams (the Bachman style of CODASYL etc., see for example from 1969) and forerunners for Peter Chen’s ER diagrams.
In preparation of this post, I reread one of my text books from university back then (On Construction and Implementation of Information Systems, Thomas Skousen, Forum, 1976, in Danish only). It used pre-Chen notation, starting with:

In fact, for some years “Entity” was used in the meaning “Master file”, whereas “Relation” meant “Structures file”. So, master files were pointed to by structures files materializing a compound database structure.
Later on (as part of Chen’s 1976 publication), more complete database semantics were added, as many of you will know:
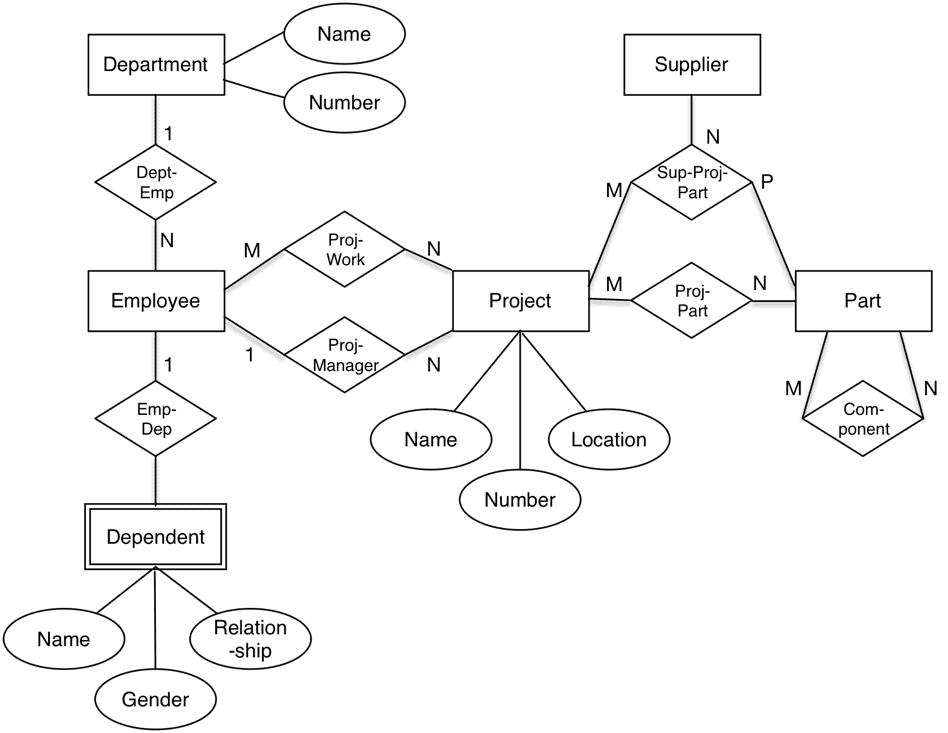
In the same 1976 textbook there is a reference to a seminal article: Term Structures, Concept Structures and Data Structures from 1972 (in Danish only) by Klaus Kjøller, a promising Danish researcher at the Technical University of Denmark. His thesis is that “You use special terms and concepts when describing what goes on in a business. Knowledge about these terms and concepts are useful in particular when constructing larger, database-oriented management information systems.” (My own translation).
The article goes into quite some detail about the semantic structures necessary for building data structures. It goes along these lines:
- Identify words, which describe activity and actions
- Identity words, which describe states
- Look for sentences, which link terms, such as:
- Costs – related to – manufacturing
This is also a “verbal” approach to data modeling with some graph thinking on top.
Similar thinking found its way into data modeling via Prof. Nijssens binary models, today known as fact models, and also into the psychological foundation for concept mapping (Prof. Novak and “linking phrases”).
And, by the way, the same textbook mentioned above has an addendum detailing the graph structures of the data instance diagrams coming out of the Chen-style database structures, as this photo from the book confirms:

This is proof of the clear connections between Chen ER and graph data models from the early 1970’s!
So, the schism is on the table:
On the one side, we had people in the early seventies trying to figure out how to build databases for business information systems. They focused on Entity-Relationship-Attribute structures visualized as graphs (a Chen diagram is a graph data model). They implemented these models in DBOMP, Pluto, IDMS or TOTAL. Getting the semantic structure and meaning right was the top priority.
On another side, we had people looking into formal math for securing a safe haven for the very same, complex novelty. The driving metaphor was systems thinking, which is where math really adds value. And the “fail safe” mathematical foundation was the chosen path.
But systems thinking is for systems, and databases are not systems (although DBMS’s are).
Is Math a Good Idea in Data Modeling?
As demonstrated, the problem was (and is) building high quality business-oriented databases. Databases are not systems per se, but rather semantic constructs, following the bent and twisted rules of necessity in real life. Data modeling is not about behavior (i.e. system engineering is not that beneficial), but it is about human communication of common terms and concepts.
There are aspects of database technology, which deserve good quality meta level design. Database and query languages, for example. SQL has demonstrated that inconsistencies and non-completeness is undesirable. But such requirements are technical, not business oriented. As are data models.
So, we can only conclude that overly engineered data models imply risks of not being able to represent the real world. When it comes to temporality this implies that subtypes should be carefully designed to be in true compliance with the real schemes for handling functional dependencies. Generalizations such as the properties of an entity in 5NF are “probably or frequently updated at the same points of time” is a gross simplification. The challenge with rules like that, is that approximations last shorter time than you assume (hope for?), when you make the decision.
Databases are long-lasting structures, where the business sets the rules – no systems-derived imperatives can change the ownership of data models.
What, Then, About Supertypes and Subtypes?
One way of answering that question is in consequence: Well, if a handful of properties share the same timeline, they are, most likely, also a valid subtype (of their supertype, if any).
The more general answer is that in order to determine valid subtypes, you must deconstruct all the way down to 6NF and be certain that you have all the dependencies right.
This means that at times, exceptions and other business rules may block the subtyping (and consequential inheritance). If you find out too late, you will have corrupt data.
Other inherent problems in working with presumed, strict hierarchies are:
- The data model is always, at best, an approximation of the real world (and the “Evil Empire” has a tendency to strike back),
- Dependencies between a property and the rest of the world might well be also outside of the type hierarchy (could be a quiet 1:M relationship)
- There is always an information loss when you decide to aggregate subtypes, and this can hit you later on
- Overlapping and otherwise untidy hierarchies are more frequent than you think – see for example Karen Lopez’ excellent presentation about lacking hierarchies (“Hierarchies don’t really exist”) in real life Master Data Management, here: https://vimeo.com/126521883.
- NB: Relational normalization recognizes these challenges, when dealing with the so-called 5NF and 6NF: “Isolate semantically related multiple relationships”, for example.
I have only seen inheritance at the DB level at work in the case of ODBMS. And that worked well for some complex (“life and death”) use cases in health care.
Instead of inheritance, the best practice is to model subtypes as entity types in their own right. Having their properties of the appropriate levels. And the relationship names can perfectly well express what is going on. (Customer)-[divided into]->(Consumer), (Customer)-[divided into]->(Small business) etc. “Is-a” can also be called “comprises”, “consists of” etc. when looking top down.

In the example above, there is clearly more work to do. Both Social Security Number and VAT Number probably belong to some intermediate subtypes (all persons and all companies).
There are also a number of examples of “wrappers”, which are used for deconstructing type hierarchies and present them as tree structures (as in the graph data model above). Let me name a few:
- JSON
- GraphQL
- Even good old SQL views
- (and we need graph views as well)
The major advantages of class inheritance are on the methods and operations side, not the data side.
Customer is, in real life, one good example of a complex structure that does not map into a hierarchical structure. In fact, the customer data model is a graph (network). Whichever way you try to twist it, you will have to understand the deep, 6NF, structure, like it or not.
From Data Buckets to Data Lakes
As we have seen, temporal dependencies quickly explode into highly connected networks, which best can be handled by a graph DBMS. And the same goes for multitype class hierarchies.
We, now, also understand that some of our more mathematical constructs originate from a line of systems thinking, where the database is seen as an extension of the application (which makes type inheritance quite attractive).
As long as we could contain the database within one bucket, we could enforce imperatives. At least that is what we thought (reality, however, showed us, well, the reality).
Today we are not looking at buckets of data but at lakes of data, which means that the applications cannot be in control:

Business rules the data models, and the business context is king! That is the real reason why 6NF structural understanding is necessary and why graph databases own the solution space for complete consistence in persistent databases. Be it fine-grained temporal control or misfits in type hierarchies.