
Click to learn more about author Mark Marinelli.
We’ve explored the benefits of an agile data mastering approach in a previous post, but let’s do a quick recap:
Many businesses that collect a large amount of data have an accumulating data mastering issue that leaves their data largely untouchable and riddled with inaccuracies. The problem lies in using an old approach to data mastering that is laborious, expensive, and prohibitive. As a result, they cannot effectively leverage their data to make sound decisions that optimize and drive business results.
I liken this antiquated data mastering problem to waterfall development that was the gold standard in the software industry over a decade ago. As we all know, waterfall development is extremely slow and restrictive. There’s a reason that software development companies all moved away from it.
It’s time that we on the data side of business catch up to our software development counterparts and take an agile approach to data mastering.
Below, I’ll break down the three pillars needed to transform from waterfall to agile data mastering, a process which is aligned to the emerging industry approach we now call DataOps, which is essentially an analogue for the DevOps approach which enabled a sea change in software development.
Pillar 1: Agile Mindset
Your entire mindset needs to shift to emulate practices of agile software development when working with data. Start envisioning your team as software developers building data applications, because that’s what you are. The sophistication of modern data supply chains which transform diverse and dirty data into actionable information has evolved far beyond traditional BI stacks, and simultaneously the demand for this information has increased dramatically. Different data constituents need different data in different forms on different time scales, so the top-down approach no longer applies.
Your focus should be building operational and analytical applications that solve major business problems, not building on reports. There are tons of modern tools that enable your end users to self-serve and build glorious visualizations of their data. But they need someone to deliver data that is current, complete, and trustworthy to feed into these tools. Your impact to the business will be in delivering the substrate for their projects as fast as they can ask for new data, just as DevOps teams have enabled developers to just write great code, enabled by automated build, test, and release infrastructure.
So get rid of all the rigorous processes of Data Modeling and rules-based data transformation that have been holding you back. Stop waiting for the perfect outcome before deriving value from your data. Instead you need to be iterative and collaborative with your entire organization. In summation? Get out of the archaic waterfall software development mindset and hold your team accountable for continuous delivery of transformative results.
Pillar 2: Agile Skill Set
After you get in the right mindset for DataOps, it’s time to upskill your team. There tends to be a lot of ambiguity in data roles which leads to inconsistencies and unaccountability. There’s no room for that in the agile world.
It is critical that stakeholders from the entire data supply chain – this who own the source systems, those who consume data in their analytical and operational applications, and those who provide the former for the latter – be included in the teams who build data applications. Too much can be lost in translation if those who understand the data best are not directly involved in the process.
To get everyone on board with the agile approach to data mastering, you need to clearly define roles and what’s expected from everyone on the team. Everyone needs to understand what their responsible for delivering so that they’re held accountable. The below organizational chart gives you an idea of what your team should look like:
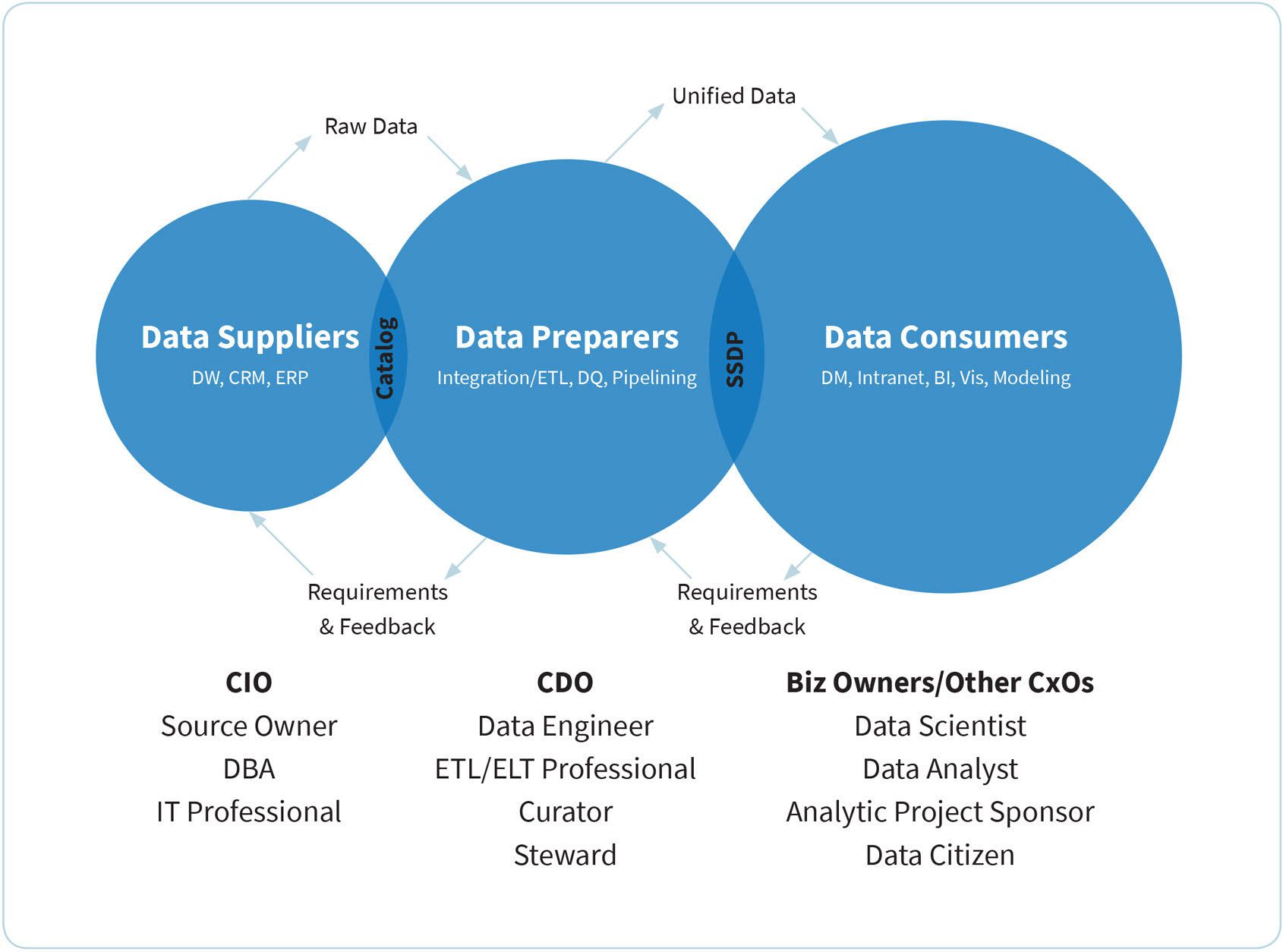
To accomplish the above often means a reorganization of the data team for many businesses, and that’s a good thing. It also means hiring dedicated talent for some new roles that may have been previously shared by a number of people (e.g. data engineers, data curators).
Pillar 3: Agile Toolset
The last (but potentially most important) part of transforming into a DataOps team is arming your people with the tools they need to be successful. You can embrace new ways of thinking and build a great team of data engineers, but if your infrastructure wasn’t built to support rapid, iterative workflow, and if it isn’t interoperable with emerging technologies which contribute best of breed solutions to each part of that data supply chain, you’re going to be grinding gears.
Perhaps one of the most common and troubling challenges businesses face when tackling their data problem is being stuck using a traditional end-to-end platform which provides suboptimal functionality at each stage in the data pipeline, but which is deemed too expensive or complex to replace.
Don’t let this hinder your ability to take charge of your data. The money you will save long term by being able to master your data will far surpass any upfront cost to set your team up for success. The best of breed tools in the data world are designed to be interoperable. You can (and should) mix and match vendors based on your unique business needs.
The great thing about well-designed tools is that it allows for easy integration across all of your platforms so that you can unify and master your data through Machine Learning. You need the right tool in your DataOps toolbox, and one tool will not suffice.
Make sure that whichever tools you use allows for automation (another page we’re stealing from the DevOps book of automated testing). The Machine Learning and algorithmic approaches automation uses take away much of the low hanging manual labor bogging down your team and helps streamline the entire process to be more efficient. The best tools offload lower-value work of Data Modeling and wrangling to algorithms and free up your people to do what you hired them to do – build great analytical and operational apps with your data.
Final Thoughts
GDPR revealed that many companies face a data integrity crisis, and it’s only getting worse. The amount of data collected by businesses is unfathomable, and having outdated processes in place leaves you susceptible to problems far worse than inefficiencies. Inaccurate and unaccounted for data can lead to misleading information or even data security issues.
It’s not too late to take control of your data with an agile approach. The mindset, skillset, and toolset pillars we of DataOps discussed above is how all successful future data teams will run. With DataOps, the very notion of, “I didn’t have access to the data” will no longer exist.