
Click to learn more about co-author Shrif Nada.
Click to learn more about co-author Davin Chia.
Over the last year, our team has interviewed more than 200 companies about their data integration use cases. What we discovered is that data integration in 2021 is still a mess.
The Unscalable Current Situation
At least 80 of the 200 interviews were with users of existing ETL technology, such as Fivetran, StitchData, and Matillion. We found that every one of them was also building and maintaining their own connectors, even though they were using an ETL solution (or an ELT one – for simplicity, we will just use the term ETL). Why?
We found two reasons:
- Incomplete coverage for connectors
- Significant friction around database replication
Inability to Cover All Connector Needs
In our interviews, we found that many users’ ETL solutions didn’t support the connector they wanted, or supported it but not in the way they needed.
An example for context: Fivetran has been in existence for eight years and supports 150 connectors. Yet, in just two sectors – martech and adtech – there are over 10,000 potential connectors.
The hardest part of ETL is not building the connectors, but maintaining them. That is costly, and any closed-source solution is constrained by ROI (return on investment) considerations. As a result, ETL suppliers focus on the most popular integrations, yet companies use more and more tools every month and the long tail of connectors goes ignored.
So even with ETL tools, data teams still end up investing huge amounts of money and time building and maintaining in-house connectors.
Inability to Address the Database Replication Use Case
Most companies store data in databases. Our interviews uncovered two significant issues with database connectors provided by existing ETL.
- Volume-based pricing: Databases are huge and serve growing amounts of data. A database with millions of rows, with the goal of serving hundreds of millions of rows, is a common sight. The issue with current ETL solutions is their volume-based pricing. It’s easy for an employee to replicate a multi-million-row database with a click. And that simple click could cost a few thousand dollars!
- Data privacy: With today’s concerns over privacy and security, companies place increasing importance on control of their data. The architecture of existing ETL solutions often ends up pulling data out of a company’s private cloud. The closed-source offerings prevent companies from closely inspecting the underlying ETL code/systems. The reduced visibility means lesser trust.
Both of these points explain why companies end up building additional internal database replication pipelines.
Inability to Scale with Data
The two points mentioned above about volume-based pricing and data privacy also apply as companies scale. It becomes less expensive for companies to have an internal team of data engineers to build the very same pipelines maintained in ETL solutions.
Why Open Source Is the Only Way Forward
Open source addresses many of the points raised above. Here is what open source gives us.
- The right to customize: Having access to and being able to edit the code to your needs is a privilege open source brings. For instance, what if the Salesforce connector is missing some data you need? With open source, such a change is as easy as submitting a code change. No more long threads on support tickets!
- Addressing the long tail of connectors: You no longer need to convince a proprietary ETL provider that a connector you need is worth building. If you need a connector faster than a platform will develop it, you can build it yourself and maintain it with the help of a large user community.
- Broader integrations with data tools and workflows: Because an open-source product must support a wide variety of stacks and workflows for orchestration, deployment, hosting, etc., you are more likely to find out-of-the-box support for your data stack and workflow (UI-based, API-based, CLI-based, etc.) with an open-source community. Some of them, like Airbyte’s open source Airflow operator, are contributed by the community. To be fair, you can theoretically do that with a closed-source approach, but you’d likely need to build a lot of the tooling from scratch.
- Debugging autonomy: If you experience any connector issues, you won’t need to wait for a customer support team to get back to you or for your fix to be at the top of the priorities of a third-party company. You can fix the issue yourself.
- Out-of-the-box security and privacy compliance: If the open-source project is open enough (MIT, Apache 2.0, etc.), any team can directly address their integration needs by deploying the open-source code in their infrastructure.
The Necessity of a Connector Development Kit
However, open source itself is not enough to solve the data integration problem. This is because the barrier to entry for creating a robust and full-featured connector is too high.
Consider, for example, a script that pulls data from a REST API.
Conceptually this is a simple “SELECT * FROM entity” query over some data living in a database, potentially with a “WHERE” clause to filter by some criteria. But anyone who has written a script or connector to continuously and reliably perform this task knows it’s a bit more complicated than that.
First, there is authentication, which can be as simple as a username/password or as complicated as implementing a whole OAuth flow (and securely storing and managing these credentials).
We also need to maintain state between runs of the script so we don’t keep rereading the same data over and over.
Afterwards, we’ll need to handle rate limiting and retry intermittent errors, making sure not to confuse them with realerrors that can’t be retried.
We’ll then want to transform data into a format suitable for downstream consumers, all while performing enough logging to fix problems when things inevitably break.
Oh, and all this needs to be well tested, easily deployable … and done yesterday, of course.
All in all, it currently takes a few full days to build a new REST API source connector. This barrier to entry not only means fewer connectors created by the community, but can often mean lower-quality connectors.
However, we believe that 80% of this hardship is incidental and can mostly be automated away. Reducing implementation time would significantly help the community contribute and address the long tail of connectors. If this automation is done in a smart way, we might also be able to improve standardization and thus maintenance across all connectors contributed.
What a Connector Development Kit Looks Like
Let’s look again at the work involved in building a connector, but from a different perspective.
- Incidental complexity
- Setting up the package structure
- Packaging the connector in a Docker container and setting up the release pipeline
- Lots of repeated logic:
- Reinventing the same design patterns and code structure for every connector type (REST APIs, databases, warehouses, lakes, etc.)
- Writing the same helpers for transforming data into a standard format, implementing incremental syncs, logging, input validation, etc.
- Testing that the connector is correctly adhering to the protocol
- Testing happy flows and edge cases
We believe in the end, the way to build thousands of high-quality connectors is to think in onion layers. To make a parallel with the pet/cattle concept that is well known in DevOps/Infrastructure, a connector is cattle code, and you want to spend as little time on it as possible. This will accelerate productivity tremendously.
Abstractions as Onion Layers
Maximizing high-leverage work leads you to build your architecture with an onion-esque structure:
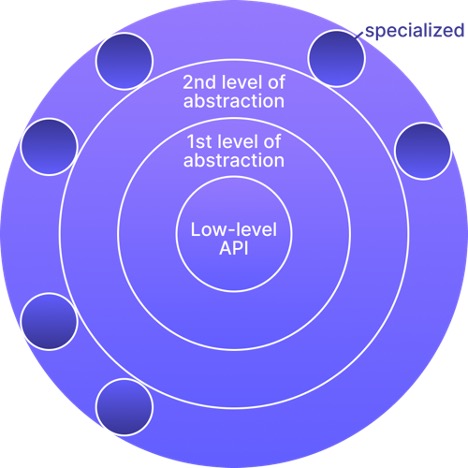
The center defines the lowest level of the API. Implementing a connector at that level requires a lot of engineering time. But it is your escape hatch for very complex connectors where you need a lot of control.
Then, you build new layers of abstraction that help tackle families of connectors very quickly. For example, sources have a particular interface, and destinations have a different kind of interface.
Then, for sources, you have different kinds like HTTP-API based connectors and databases. HTTP connectors might be split into REST, GraphQL, and SOAP, whereas databases might split into relational, NoSQL, and graph databases. Destinations might split into warehouses, data lakes, and APIs (for reverse ELT).
The CDK is the framework for those abstractions!
What Is Already Available
Our company’s CDK is still in its early days. Today, the framework ships with the following features:
- A Python framework for writing source connectors
- A generic implementation for rapidly developing connectors for HTTP APIs
- A test suite to test compliance with the Airbyte Protocol and happy code paths
- A code generator to bootstrap development and package your connector
In the end, the CDK enables building robust, full-featured connectors within two hours versus two days previously.
Our team has been using the framework internally to develop connectors, and it is the culmination of our experience developing more than 70-plus connectors (our goal is 200 by end of the year with help from the user community!). Everything we learn from our own experience, along with the user community, goes into improving the CDK.
Conclusion – The Future Ahead
Wouldn’t it be great to bring the time needed to build a new connector down to 10 minutes, and to extend to more and more families of possible integrations? How’s that for a moonshot!
If we manage to do that together with our user community, then at long last the long tail of integrations will be addressed in no time – not to mention that data integration pipelines will be commoditized through open source.