
Those who want to design universal data pipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each data pipeline platform embodies a unique philosophy, architectural design, and set of operations. Some platforms are centered around batch processing, while others are centered around real-time streaming.
While the nuances of these technologies make them exceptionally adept at the tasks they were designed for, they also make it difficult to accommodate all their test requirements fully.
In theory, universal, full-function testing tools would be a panacea, deftly navigating the peculiarities of any data pipeline system that is currently in use. The realities of conducting such an endeavor paint a more complicated picture. A Herculean effort would be needed to craft tools that are comprehensively integrated and finely tuned to the particulars of each system.
This problem is made even more difficult by the ever-changing nature of technology, characterized by the frequent appearance of updates, new features, and original platforms. The search for universally applicable data pipeline test tools raises an essential question:
Is it possible for a single testing tool to provide the breadth and precision required to support the requirements of all data pipeline technologies?
This article delves into these complexities and highlights the intricacies that stand in the way of universal testing tools that can be applied to a wide variety of data pipelines (Figure 1). Then we outline how you can identify individual tools and frameworks to meet your needs.
Figure 1: Data pipeline complexities, data volumes, and varied architectures challenge testing tools.
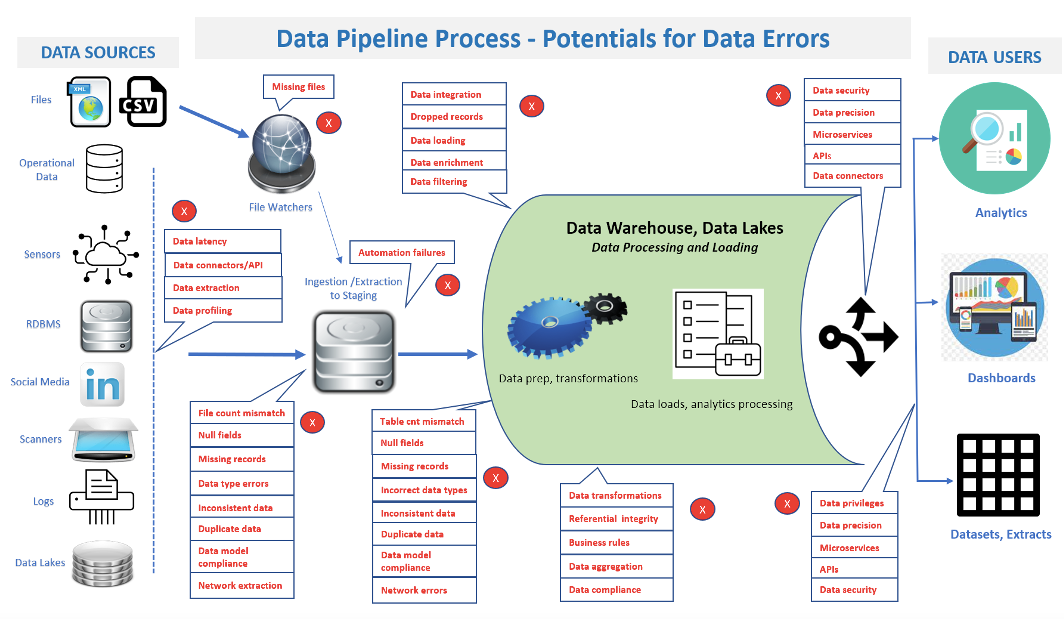
Challenges for Data Pipeline Test Tool Developers
Data pipeline test tools are often hindered by challenges that prevent them from supporting complex data pipeline technologies and frameworks.
Commercial considerations: From a business standpoint, tool developers and vendors must consider market demand. If their primary audience uses a subset of technologies, it makes commercial sense to provide in-depth, robust support for those rather than shallower support for a broader range. Deep, specialized support can improve customer satisfaction, even if the tool does not cater to every technology.
Complexity and diversity of technologies: Data pipeline technologies vary significantly in their internal mechanics, APIs, and usage patterns. For instance, a batch processing system like Apache Hadoop operates in a fundamentally different way from a real-time stream processing system like Apache Kafka. Crafting a test tool that can interface seamlessly with both means would be grappling with two distinct systems. This complexity amplifies as more technologies are added to the mix.
Complexity of CI/CD pipelines: Integrating testing tools with Continuous Integration and Continuous Deployment (CI/CD) processes is essential for streamlining development workflows and ensuring consistent quality. However, the integration poses several challenges:
- CI/CD pipelines involve numerous steps: Code integration, unit testing, and system testing to deployment and monitoring. Introducing a testing tool into a workflow means accounting for and managing its interactions across all these intricate stages.
- Configuration management: Ensuring testing tools are consistently configured across various environments (development, staging, production) in a CI/CD pipeline is challenging. A minor configuration mismatch can lead to inconsistent test results.
- Tool compatibility: Not all testing tools are designed to integrate seamlessly with popular CI/CD platforms like Jenkins, Travis CI, or GitLab CI. Achieving smooth integration might require adding plugins, adapters, or custom scripting.
- Performance overheads: Automated tests can introduce latency when added to a CI/CD pipeline. Ensuring that tests run efficiently is crucial to avoid slowing down the entire deployment process.
- CI/CD’s dynamic environment management often involves creating temporary environments for testing. Ensuring that testing tools can dynamically adapt to these environments, especially when dealing with data pipelines, can be complex.
- Granular feedback mechanisms: Developers need specific, actionable feedback when a test fails during the CI/CD process. Ensuring the testing tool can provide granular error messages and logs integrated into the CI/CD dashboard is vital for quick troubleshooting.
- Version control and updates: As the testing tools and CI/CD platforms evolve, maintaining compatibility between their versions becomes a moving target. Regular updates and checks are needed to prevent integration breakdowns.
- Parallel execution: To speed up CI/CD processes, tests may be run in parallel. Ensuring testing tools can handle concurrent executions without conflicts or resource contention is challenging.
- State management: It is crucial to manage the state of data before and after tests, especially in data pipeline testing. Integrating tools that can set up, test, and tear down data states within CI/CD processes can be complex.
- Security concerns: CI/CD pipelines often have stringent security protocols. Integrating an external testing tool means ensuring it follows these protocols, does not introduce vulnerabilities, and can handle sensitive data securely.
Custom features and extensions: Many data pipeline technologies allow for customization via plugins, extensions, or user-defined functions. These customizations might alter the standard behavior of the technology. For a testing tool to universally support such custom elements across multiple technologies, it must be incredibly adaptable to allow custom scripting or modular extensions to handle these unique cases.
Depth vs. breadth: A tool that attempts broad compatibility might miss the nuances and intricacies of individual technologies. For example, while a generalized tool might verify data integrity across Apache Spark and Apache NiFi, it might not be attuned to Spark’s specific partitioning mechanics or NiFi’s specific flowfile attributes.
Different data structures and formats: Data can be structured, semi-structured, or unstructured. While one tool might manage JSON data streams, another might focus on columnar data like Parquet or Avro. A universal testing tool would need comprehensive parsers and validators for many data formats, adding to its complexity.
Different pipeline architectures: Not all data pipelines follow the same architectural patterns. Some might have complex branching, looping, or conditional flows. Others might offer simple, linear transformations. Testing tools must account for these architectural differences, ensuring they can visualize, trace, and validate data across varied flow patterns. Adapting to and ensuring comprehensive testing across these diverse architectures is a substantial challenge.
Differing scalability needs: Tools like Apache Kafka are designed for high-throughput, low-latency data streams and can manage millions of messages per second. In contrast, batch-oriented systems might process vast volumes of data but do not support real-time processing speeds. A testing tool that caters to both must be architected to efficiently manage vastly different scalability and performance scenarios.
Maintenance challenges: With each technology a testing tool supports, there is an added maintenance burden. This includes handling bugs, interfacing with different APIs, and catering to user requests specific to each technology. The compounded maintenance effort can slow the development cycle, leading to slower feature releases and longer bug-fix times.
Performance overheads: Ensuring compatibility with numerous technologies might require additional layers of abstraction within the testing tool. These layers can introduce latency or processing overheads. In data-intensive operations, where performance is paramount, these overheads might be unacceptable or detrimental to real-time processing needs.
Rapid evolution: The tech landscape evolves swiftly, especially in big data and data pipeline realms. New versions of existing tools or entirely new tools are released frequently. Test tools that support multiple technologies must continuously be updated to keep pace with these changes, ensuring that it remains compatible and leverages new features or best practices.
The allure of universal testing tools is indisputable; however, the practical challenges posed by the diverse and intricate world of data pipeline technologies make selecting specialized tools a more feasible and practical option for many scenarios. Choosing specialized tools is a more feasible and practical option for many scenarios.
Specialized tools are better equipped to handle the specifics of testing environments. Data pipelines are frequently complex systems that are responsible for the management of substantial amounts of essential data. Because of this, the significance of employing reliable automated testing cannot be overstated. It is essential for data-driven decision-making to have access to trustworthy, up-to-date, and high-quality data; therefore, appropriate testing tools and strategies are required.
Specialized tools are better equipped to handle the specifics of testing environments. Because of this, the significance of employing reliable automated testing cannot be overstated. It is essential for data-driven decision-making to have access to trustworthy, up-to-date, and high-quality data; therefore, appropriate testing tools and strategies are required.
Assessing Functional Requirements for Data Pipeline Testing
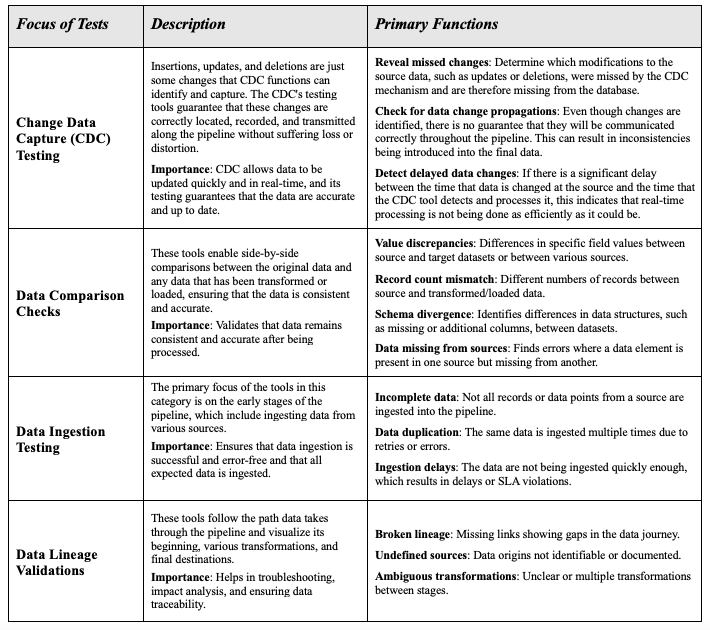
Table 1 shows several of the many types of testing functions needed for data pipeline testing.
An expanded table with more than 15 types of tests can be accessed here.
Table 1: Commonly used automated testing functions for data pipeline verifications and validations.
Conclusion
As we have seen, one of the challenges of developing or implementing multifaceted tools is that they frequently require users to make important decisions regarding the level of depth versus the level of breadth that the tool offers. As the data landscape continues to develop and evolve, it is becoming increasingly important for organizations to understand these nuances.
Instead of searching for testing solutions that apply to all situations, the focus should be on finding specialized tools or modular frameworks that provide a combination of adaptability and depth. Implementing this strategy assures exhaustive testing tailored to precise requirements and paves the way for innovation in data pipeline testing methodologies.
In part two of this blog post, we will look at some practical testing frameworks that should be considered. When seeking solutions to problems with data pipeline testing, it is a good idea to begin by conducting research on commercial tool providers, open-source tools, chats about artificial intelligence, web searches, and consulting with IT professionals. Proper planning for data pipeline testing solutions requires this type of research. Part two of this blog post will provide a comprehensive list of the studies and tool sources that can be utilized.


