 Does this scenario sound familiar? In an organization’s quest to become data-driven and analytics-savvy, it has worked to implement a Data Lake. The initial hope was that such an organization would realize greater agility for certain use cases than was possible with a Data Warehouse – which were time-consuming to set up, costly to maintain, and not particularly friendly to data additions.
Does this scenario sound familiar? In an organization’s quest to become data-driven and analytics-savvy, it has worked to implement a Data Lake. The initial hope was that such an organization would realize greater agility for certain use cases than was possible with a Data Warehouse – which were time-consuming to set up, costly to maintain, and not particularly friendly to data additions.
The volume of data dumped into the Data Lake has continued to grow, without best practices in place to manage it all, it started to become obvious that finding, querying, using, and analyzing these raw data assets was problematic, too. It has become a Data Swamp.
If your organization has its hands up, join the crowd. Many companies that are using or would like to use Hadoop don’t have a team of data experts on hand to solve these issues, says Paul Barth, founder and CEO of Podium Data.
Given the right tools, data developers would be able to catalog and build a Metadata Repository so that they would be able to pick the raw data they need from a Hadoop Data Lake at the time they need it to meet business requirements, cleaning it up at that point to support Data Analytics and other emerging technologies such as AI and Machine Learning. An automated way to do all that would promote better Data Quality to fulfill a particular business need.
With such a system in place, Data Lakes would be well-positioned to surpass what Data Warehouses can offer for satisfying growing needs to gain faster insights from a much wider set of data.
The Data Lake market will be worth close to $9 billion by 2021, reports MarketsandMarkets Research. The report explains:
“The major forces driving the Data Lakes market are the need for increased business agility and accessibility, increasing adoption of Internet of Things (IoT), potential for in-depth insights to drive competitive advantage, and growing volume and variety of business data. The Data Lakes market is growing rapidly because of the transformation from traditional Data Management techniques for storage to advanced techniques and massive surge of flowing structured and unstructured data.”
Bringing More Structure to the Data Lake
A few years ago, however, Gartner predicted that through 2018, 90 percent of deployed Data Lakes will be useless as they are overwhelmed with information assets captured for uncertain use cases.
A number of vendors have stepped forward in the intervening years to bring management to the space, aiming to help turn around that unhappy prediction. They have been bringing tools for Data Management, Data Lineage, Metadata Management, and Data Governance to the fore. Constellation Research in March even came out with its shortlist of Data Lake Management vendors, which included Podium Data, along with others such as IBM, Informatica, Kylo, Oracle, Unifi Software and Zaloni.
The category, the report notes:
“Is important for any organization that wants to take advantage of high-scale data, particularly as data sources and data-driven applications multiply and as data scale and diversity grows, contributing to the complexity and risk of lost and unusable data within data lakes.”
The Podium Data Marketplace is the enterprise-class software platform Podium Data originally created to help businesses get more out of Data Lakes. It first came to the market a few years ago, but its value proposition remains the same, Barth says:
“When we first started we recognized that the issue with adopting Data Analytics and bringing data to bear was 100 percent gated by the ability to have ready data for those processes.”
In developing the solution, the company did a lot of work with customers about how long it took them to do everything from adding new data to Data Lakes to getting useful insights, and how much those numbers and results differed from what they wanted them to be. Those discussions made it clear that “time-to-answer” needed to be drastically shortened. “Lowering the cost and the engineering required to get answers is a fundamental driver of agility,” Barth says.
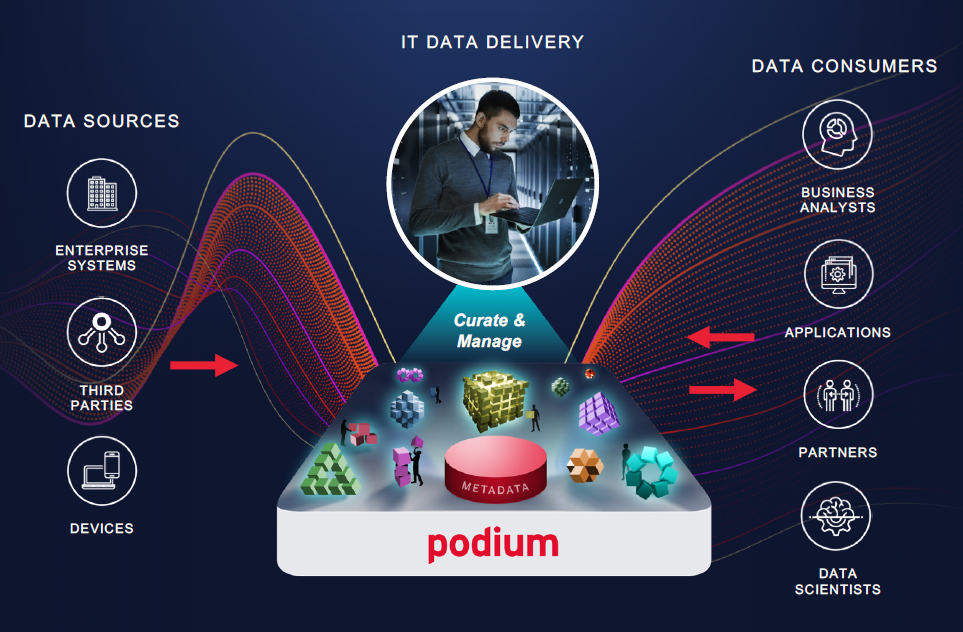
Image Credit: Podium Data
Astellas Pharmaceutical, for example, has gone from taking three months on average to provide analytics insight to two days, says Barth, “because we have everything staged and ready for when that query comes in.”
The Podium Process
Podium’s philosophy is centered around bringing business-ready data to users on demand in a self-service model that includes reuse and collaboration, and enterprise grade Data Management. As the product name reflects, it’s all about creating a marketplace where data consumers and producers create value together and enrich the products that are in the marketplace.
“We always felt that the consumer of data needed a stronger hand – not just give things to IT to produce for them but to co-produce with them,” Barth says.
Offering Data Lake Management for data on Hadoop was its first effort at realizing its value proposition of taking advantage of data to the maximum level. But now that extends to using Hadoop and parallel processing to create a high-quality, profiled catalog of data that could include data from inside and outside Hadoop environments: data that at some point could go into the lake and then start building out these assets as they should appear there. It automatically converts, validates, and profiles legacy and external data sources into a consistent format and structure on Hadoop, including mainframe data sets.
“Companies can put all their data on this-cost effective platform and we will have it available, ready, and refreshed with quality controls,” Barth says. Its smart Data Catalog provides automated and mandated continuous metadata capture with intelligent rules – including processes for creating lineage, business tagging, governance and more – as well as searchability.
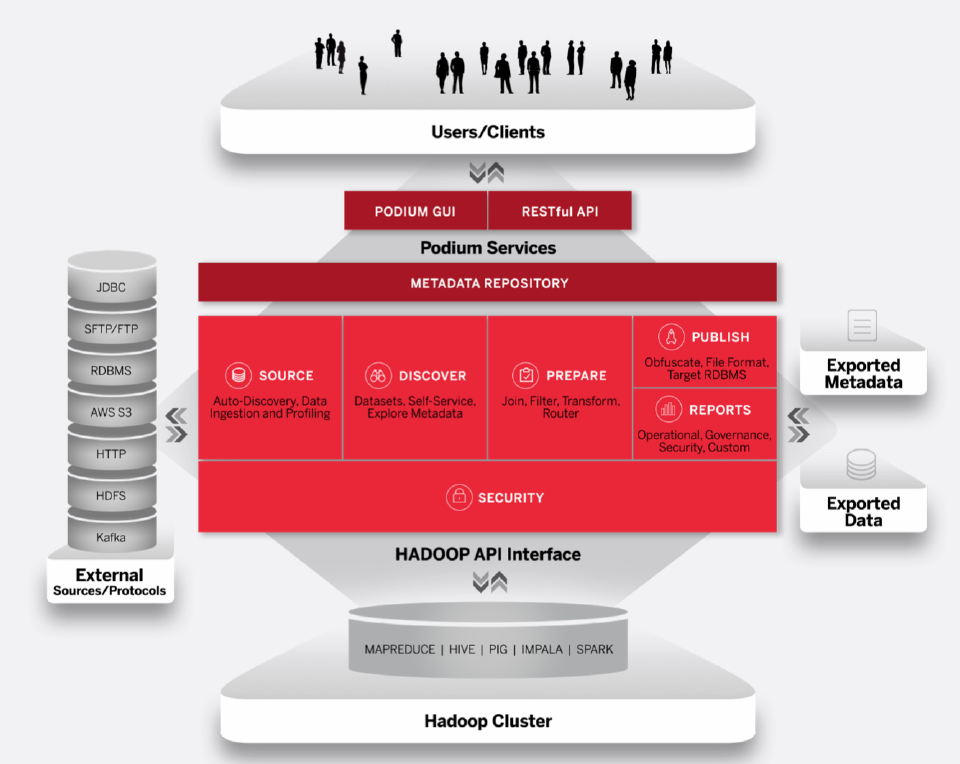
Image Credit: Podium Data
In the last couple of years, Podium Data has also been able to write rules and detection algorithms against the metadata itself to generate more metadata – for instance, to detect whether information is qualified as PII by looking at field signatures.
With the solution, says Barth:
“Everyone can go to the common platform or location to get raw data, and we make it easy to refine that data so it can be shared to get incredible levels of reuse that you never got before when data was shipped all over the place.”
Barth wants companies to understand that data and Data Architecture is living and dynamic, and that as new data sources come into the platform and are tracked in the catalog, it’s possible to join things together in new ways to create new value. “We encourage them to build the catalog first, then use it to identify business opportunities and prioritize their goals. The catalog enables a truly data-driven business strategy,” Barth says.
Provisioning data into a raw data environment where it can be consumed and understood, creating purpose-built data sets, and exposing trusted data with appropriate access controls for self-service user communities are key aspects. “You find gaps, weaknesses and maybe opportunities that you hadn’t thought of by having the catalog at the ready for you at all times,” says Barth.
Indeed, he explains, “we want the catalog centric view of the world to be dominant.” It has to be smart about where data is, whose using it, and ensuring that it is transparent, agile, and scalable.
“The future isn’t everything consolidated in one Hadoop cluster,” Barth says, “and to manage hybrid and federated data that spans on-premises and in the cloud you need a catalog-centric product.”
Photo Credit: zhu difeng/Shutterstock.com