“Remember that every science is based upon an abstraction. An abstraction is taking a point of view or looking at things under a certain aspect or from a particular angle. All sciences are differentiated by their abstraction.” (Fulton Sheen)
Graph and document databases (aka document stores), also demonstrate this principle. A few years, graph databases really took off as a new must-have technology. The Panama Papers, reported in 2017 by the International Consortium of Investigative Journalists, showed the power of graph databases. They released the Pandora Papers, an expansion on the original, with more analysis through graph technologies, in mid-2021. Graph technology is still in its infancy, although it has come a long way.
In contrast to a graph databases, document database technology has been known for a while. NoSQL databases, such as graph and document databases, enable businesses to quickly solve problems despite a deluge of fast-changing information. But managers have the challenge of knowing what kind of database to use, as one provides a very different data view than another.
The best database designs depend on the business structure and problems to be addressed.
Take retirement benefit administration, for example. The State of Oregon has a very complicated retirement formula relying on paying the right person the right amount at the right time. PERS payment amounts depend on an employee’s age and when, how long, and where they were hired, among other variables.
Current and potential retirees need to know how to navigate this system to update their information and keep abreast of changes. Oregon provides Member Services strategy, education and outreach to the state entities and their employees. Challenges include reaching the most members in a timely manner, which is no small feat for 367,000 current and former employees, associated with 904 agencies. How could graph and document databases assist with this mission statement? What sort of problems could they address, and should these different database architectures even be considered?
A Category of NoSQL Database
Graph databases and document stores make up a subcategory of non-relational databases or NoSQL. NoSQL databases were created to get a handle on large amounts of messy big data, moving very quickly. Managers use the non-relational toolkit to gain business insights and detect patterns in information on the fly, as big data streams into the system. Many companies, especially those with a large web presence like Google, Facebook, and Twitter, consider NoSQL databases a must-have.
Prior to the adoption of non-relational databases, organizations used data warehouses or relational databases to report on business specifics and support operations. SQL or Structured Query Language does very well with specifics and a defined future time or point. For example, a data warehouse may provide an answer about how many former employees who worked in Bend, Oregon will require over $50,000 next year as a retirement payout.
Since data warehouses have defined structures with fixed data types and quantities, they are good for everyday reporting, sales, and purchases. But relational databases have limited capability to handle rapidly changing business contexts, respond to unforeseen business needs, and process changes in a timely manner.
A data warehouse cannot adapt to vast amounts of unstructured or semi-structured data. Complicated questions take too long to answer in a relational database, such as how groups of former and recently retired employees compare as they are using the phone or website to update their retirement information, or how do retirees with multiple combinations of education, gender, age, former career, locations, compare in the frequency of withdrawing retirement payments.
Relational databases do not readily find content across a wide variety of formats, for example accessing information on filling out retirement forms through video, audio, or text. NoSQL databases step in to solve these types of issues.
Flexibility defines graph and document databases, as they have the NoSQL advantages. A graph databases provides immediate feedback on data relations, outpacing traditional relational databases. For example, journalists used graph databases instead of poring over 11.5 million documents and 2.6TB of data by hand to determine the relationship between offshore tax havens and account owners.
Like a graph database, a document store has the NoSQL technology handle all sorts of data types and perform quickly to filter this data. For example, The National Health Service UK (NHS) delivers clinical information using a document store called Riak.
Both graph and document stores have the convenience, speed, scalability, and versatility to grow a business. However, graph and document databases differ on how they abstract and conceptualize streaming big data.
Graph and Document Databases: Different Types of Abstraction
If a Member Services Department wants to improve or change outreach and retirement education. It wants to improve its website effectiveness in presenting and engaging prospective and current employees and decrease phone contact with support. To develop new insights, should member services invest in a graph or document database?
A graph database would be better at figuring out how hundreds of different member characteristics relate in several different ways to disseminate retirement information. A graph database, like any ontology, depicts behaviors of entities and the relationships between them. Graph databases show connections, and the specific data values mean less. Each entity, (a business, person, or object) appears as a node. Each node is connected to another by an “edge,” a connection representing a relationship between two nodes. Each node also contains characteristics or properties that are represented as “key-value pairs.” As data is added or modified, the graph database adapts and updates this information in real-time. The example below shows asset management dependencies and business complexities in an account, portfolio, or fund manager.
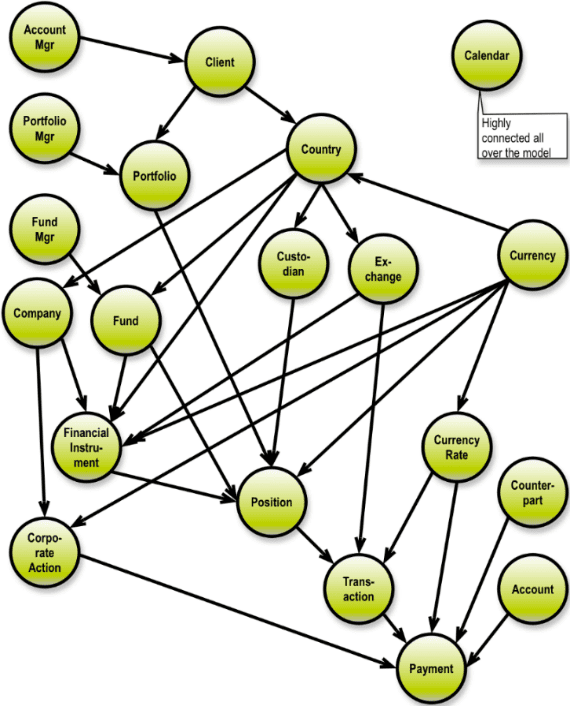
Image Credit: Thomas Frisendal
Graph database technology finds information best where the initial data structure is challenged, and skewed distributions present themselves. Thomas Frisendal advises graph databases handle problems where over 150 percent of the data is interrelated and/or there are tens to hundreds of data distributions spanned between data nodes.
Examples of good graph databases include:
- Social relationships (nodes are people)
- Public transport links (nodes can be bus or train stations)
- Roadmaps (nodes are street intersections or highway intersections)
- Anything requiring traversing a graph to find the shortest routes, nearest neighbors, etc.)
Grouping 367,000 retirement members into hundreds of different combinations and connecting multiple modes used to retrieve retirement information (e.g. phone, a class, website, snail mail, email, etc.) to understand correlations suits a graph database.
Suppose Retirement Member Services learns that clusters of members, in the hundreds, use older internet technologies with less bandwidth, and are more likely to call support or attend a class. Can Member Services find and import contact information from the graph database and customize the information to various retirement subsections? No, graph databases do not carry or store specific data values; they use approximations. So, grouping the various graphical nodes, establishing relational tables, and reporting on how to present retirement information to whom, will not translate well. But a document database may solve the problem in a different way.
A document database provides a flexible taxonomy that is not bound by context. The hierarchy can be rearranged, and each document can have a different set of attributes. Data appears in a tree structure where paths or branches connect data values, or leaves. These data values or leaves organize according to the stored properties in XML, JSON, or BSON formats, different kinds of tagging languages. As Keith Foote states:
“Each document is effectively an object containing attribute metadata along with a typed value such as string, date, binary, or an array. This provides a way to index and query data based on the attributes in the document.”
An example of a document store is depicted below.

Image Credit: Akshay Pore
Document stores easily find and reuse information through metadata, across different documents types (emails, scientific papers, news articles, videos, etc.), and collections. Furthermore, document databases can quickly disseminate content to many recipients, scale-up as the customer base increases, and adapt to different data formatting requirements on the fly.
This kind of technology could cope with new data types to be used in the future and handle system failures well, still providing reliable educational retirement content. If Member Services uses a document store database to store and locate its training materials on retirement options, then the department could customize retirement information and support in real-time.
Graph and document databases offer new super powers to handle the future. Graph databases could show connections between hot new technologies and the members who would be likely to use them. Add Machine Learning to the mix, which updates managers on the fly about how to present educational material on the website, and this could happen almost immediately, by using a document database. Graph and document databases offer different perspectives and power to solve problems.
Image used under license from Shutterstock.com


